 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions
Aug 24, 2020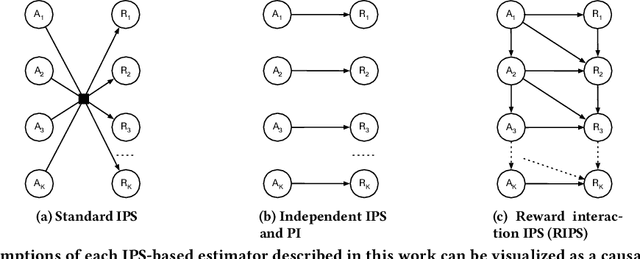
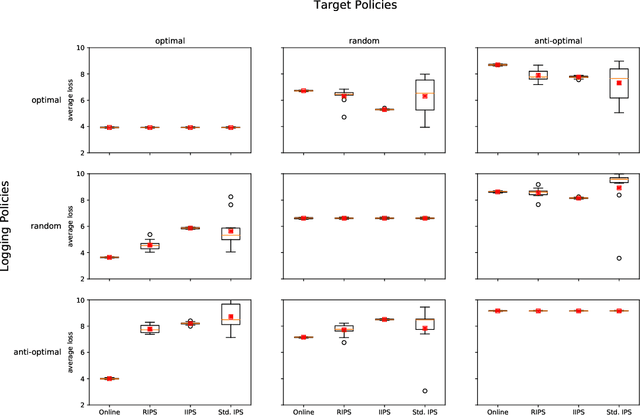
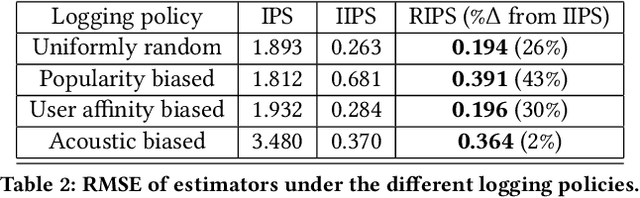
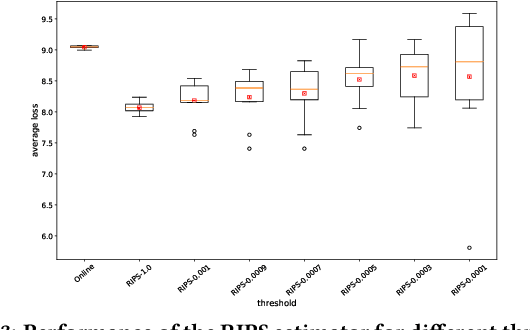
Users of music streaming, video streaming, news recommendation, and e-commerce services often engage with content in a sequential manner. Providing and evaluating good sequences of recommendations is therefore a central problem for these services. Prior reweighting-based counterfactual evaluation methods either suffer from high variance or make strong independence assumptions about rewards. We propose a new counterfactual estimator that allows for sequential interactions in the rewards with lower variance in an asymptotically unbiased manner. Our method uses graphical assumptions about the causal relationships of the slate to reweight the rewards in the logging policy in a way that approximates the expected sum of rewards under the target policy. Extensive experiments in simulation and on a live recommender system show that our approach outperforms existing methods in terms of bias and data efficiency for the sequential track recommendations problem.
Data Cleansing with Contrastive Learning for Vocal Note Event Annotations
Aug 05, 2020
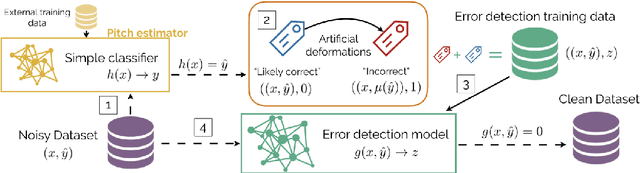

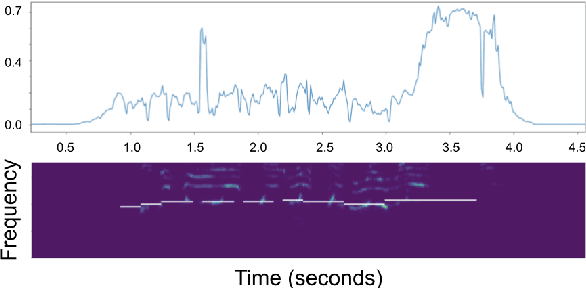
Data cleansing is a well studied strategy for cleaning erroneous labels in datasets, which has not yet been widely adopted in Music Information Retrieval. Previously proposed data cleansing models do not consider structured (e.g. time varying) labels, such as those common to music data. We propose a novel data cleansing model for time-varying, structured labels which exploits the local structure of the labels, and demonstrate its usefulness for vocal note event annotations in music. %Our model is trained in a contrastive learning manner by automatically creating local deformations of likely correct labels. Our model is trained in a contrastive learning manner by automatically contrasting likely correct labels pairs against local deformations of them. We demonstrate that the accuracy of a transcription model improves greatly when trained using our proposed strategy compared with the accuracy when trained using the original dataset. Additionally we use our model to estimate the annotation error rates in the DALI dataset, and highlight other potential uses for this type of model.
Multi-Dueling Bandits and Their Application to Online Ranker Evaluation
Aug 22, 2016
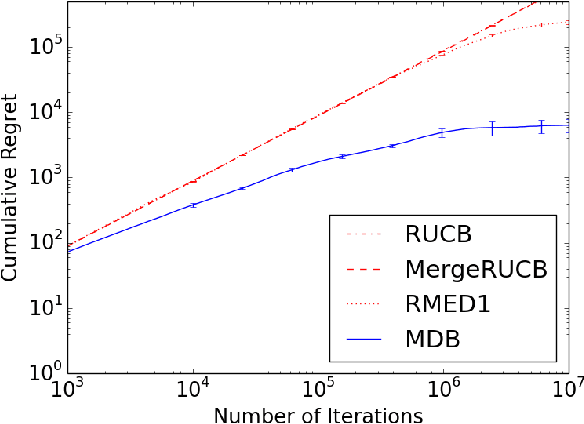
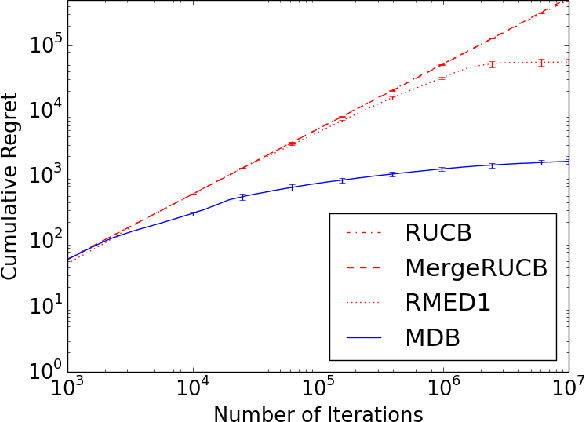
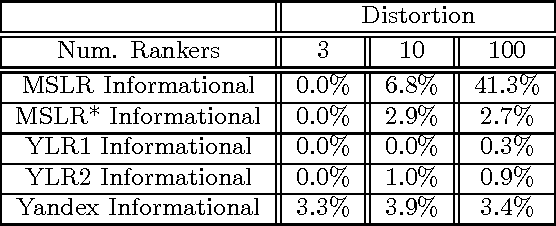
New ranking algorithms are continually being developed and refined, necessitating the development of efficient methods for evaluating these rankers. Online ranker evaluation focuses on the challenge of efficiently determining, from implicit user feedback, which ranker out of a finite set of rankers is the best. Online ranker evaluation can be modeled by dueling ban- dits, a mathematical model for online learning under limited feedback from pairwise comparisons. Comparisons of pairs of rankers is performed by interleaving their result sets and examining which documents users click on. The dueling bandits model addresses the key issue of which pair of rankers to compare at each iteration, thereby providing a solution to the exploration-exploitation trade-off. Recently, methods for simultaneously comparing more than two rankers have been developed. However, the question of which rankers to compare at each iteration was left open. We address this question by proposing a generalization of the dueling bandits model that uses simultaneous comparisons of an unrestricted number of rankers. We evaluate our algorithm on synthetic data and several standard large-scale online ranker evaluation datasets. Our experimental results show that the algorithm yields orders of magnitude improvement in performance compared to stateof- the-art dueling bandit algorithms.