 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-assisted Coding with Cody: Lessons from Context Retrieval and Evaluation for Code Recommendations
Aug 09, 2024In this work, we discuss a recently popular type of recommender system: an LLM-based coding assistant. Connecting the task of providing code recommendations in multiple formats to traditional RecSys challenges, we outline several similarities and differences due to domain specifics. We emphasize the importance of providing relevant context to an LLM for this use case and discuss lessons learned from context enhancements & offline and online evaluation of such AI-assisted coding systems.
Local Linear Forests
Jul 30, 2018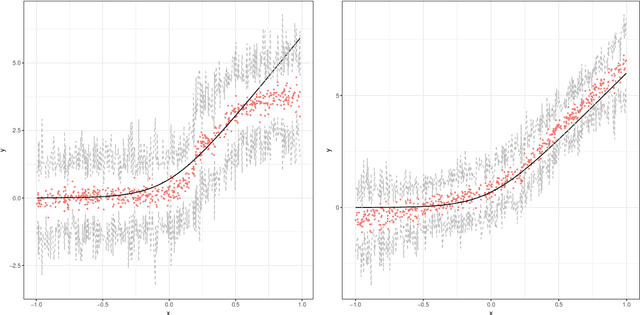

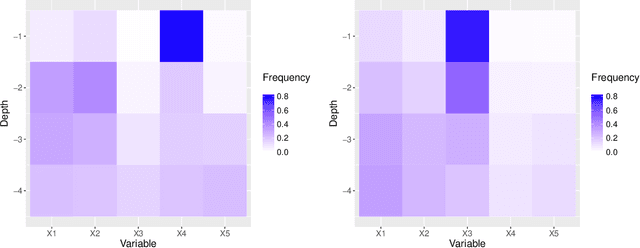
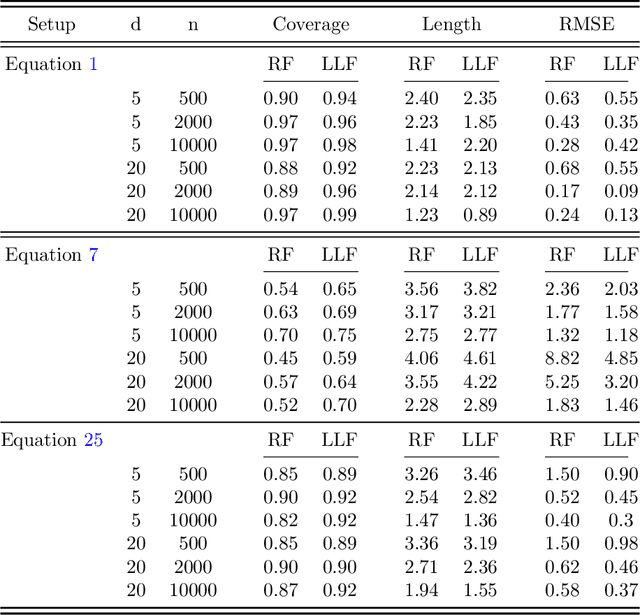
Random forests are a powerful method for non-parametric regression, but are limited in their ability to fit smooth signals, and can show poor predictive performance in the presence of strong, smooth effects. Taking the perspective of random forests as an adaptive kernel method, we pair the forest kernel with a local linear regression adjustment to better capture smoothness. The resulting procedure, local linear forests, enables us to improve on asymptotic rates of convergence for random forests with smooth signals, and provides substantial gains in accuracy on both real and simulated data.
Generalized Random Forests
Apr 05, 2018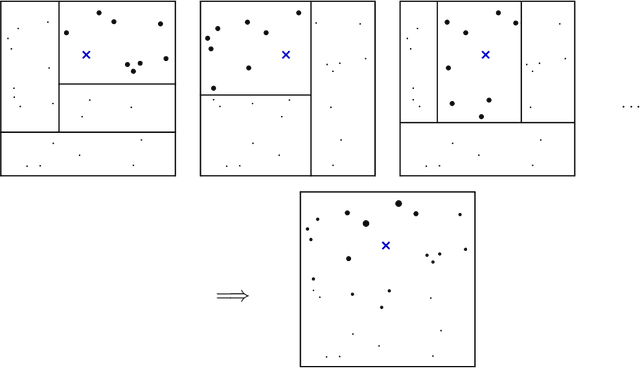
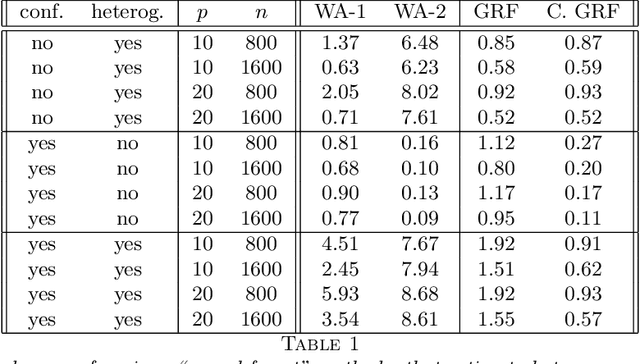
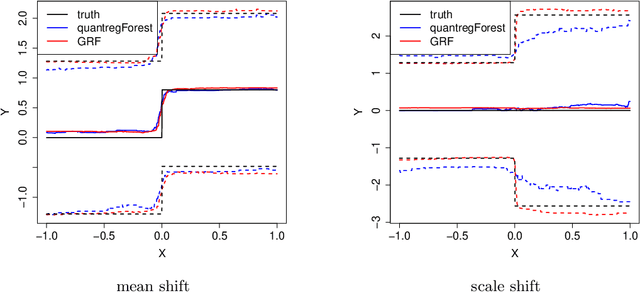

We propose generalized random forests, a method for non-parametric statistical estimation based on random forests (Breiman, 2001) that can be used to fit any quantity of interest identified as the solution to a set of local moment equations. Following the literature on local maximum likelihood estimation, our method considers a weighted set of nearby training examples; however, instead of using classical kernel weighting functions that are prone to a strong curse of dimensionality, we use an adaptive weighting function derived from a forest designed to express heterogeneity in the specified quantity of interest. We propose a flexible, computationally efficient algorithm for growing generalized random forests, develop a large sample theory for our method showing that our estimates are consistent and asymptotically Gaussian, and provide an estimator for their asymptotic variance that enables valid confidence intervals. We use our approach to develop new methods for three statistical tasks: non-parametric quantile regression, conditional average partial effect estimation, and heterogeneous treatment effect estimation via instrumental variables. A software implementation, grf for R and C++, is available from CRAN.
Robust Logistic Regression using Shift Parameters (Long Version)
Apr 29, 2014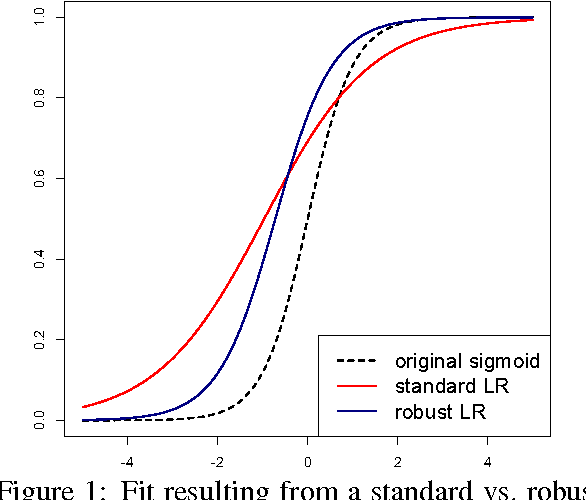


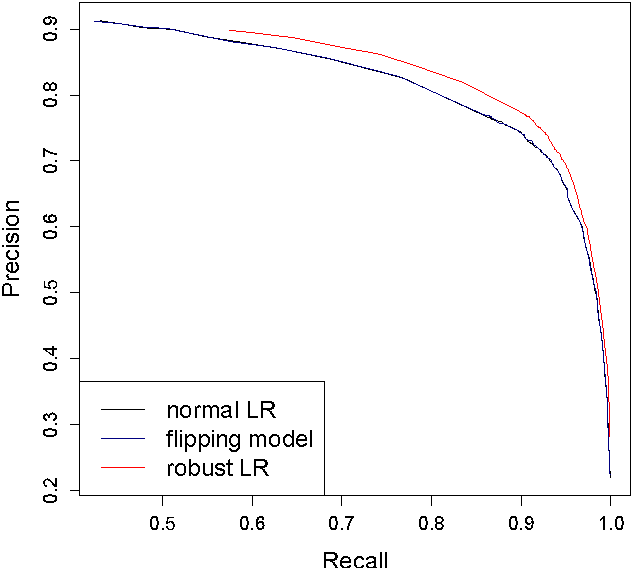
Annotation errors can significantly hurt classifier performance, yet datasets are only growing noisier with the increased use of Amazon Mechanical Turk and techniques like distant supervision that automatically generate labels. In this paper, we present a robust extension of logistic regression that incorporates the possibility of mislabelling directly into the objective. Our model can be trained through nearly the same means as logistic regression, and retains its efficiency on high-dimensional datasets. Through named entity recognition experiments, we demonstrate that our approach can provide a significant improvement over the standard model when annotation errors are present.