Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Logistic Regression using Shift Parameters (Long Version)
Paper and Code
Apr 29, 2014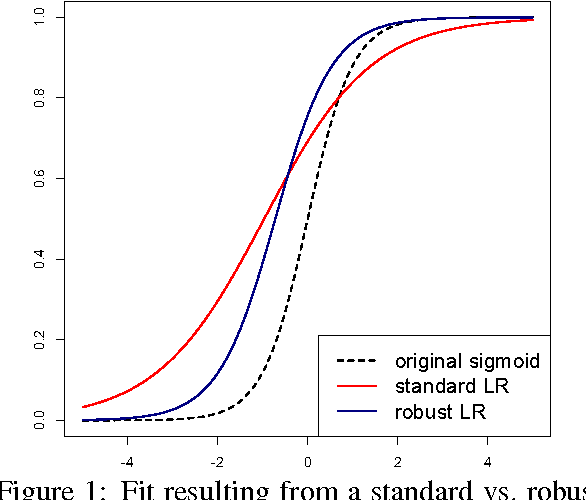


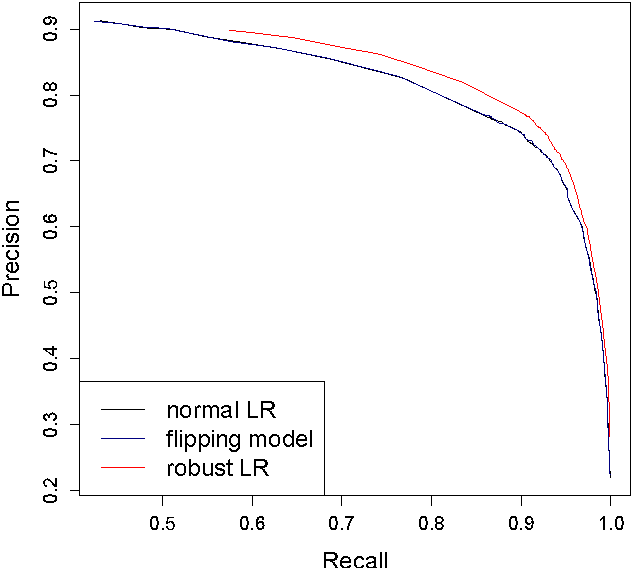
Annotation errors can significantly hurt classifier performance, yet datasets are only growing noisier with the increased use of Amazon Mechanical Turk and techniques like distant supervision that automatically generate labels. In this paper, we present a robust extension of logistic regression that incorporates the possibility of mislabelling directly into the objective. Our model can be trained through nearly the same means as logistic regression, and retains its efficiency on high-dimensional datasets. Through named entity recognition experiments, we demonstrate that our approach can provide a significant improvement over the standard model when annotation errors are present.
View paper on