 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Motion Models for Assessing Generated Videos
Apr 30, 2025A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.
Spectral Image Tokenizer
Dec 12, 2024



Image tokenizers map images to sequences of discrete tokens, and are a crucial component of autoregressive transformer-based image generation. The tokens are typically associated with spatial locations in the input image, arranged in raster scan order, which is not ideal for autoregressive modeling. In this paper, we propose to tokenize the image spectrum instead, obtained from a discrete wavelet transform (DWT), such that the sequence of tokens represents the image in a coarse-to-fine fashion. Our tokenizer brings several advantages: 1) it leverages that natural images are more compressible at high frequencies, 2) it can take and reconstruct images of different resolutions without retraining, 3) it improves the conditioning for next-token prediction -- instead of conditioning on a partial line-by-line reconstruction of the image, it takes a coarse reconstruction of the full image, 4) it enables partial decoding where the first few generated tokens can reconstruct a coarse version of the image, 5) it enables autoregressive models to be used for image upsampling. We evaluate the tokenizer reconstruction metrics as well as multiscale image generation, text-guided image upsampling and editing.
Four-Plane Factorized Video Autoencoders
Dec 05, 2024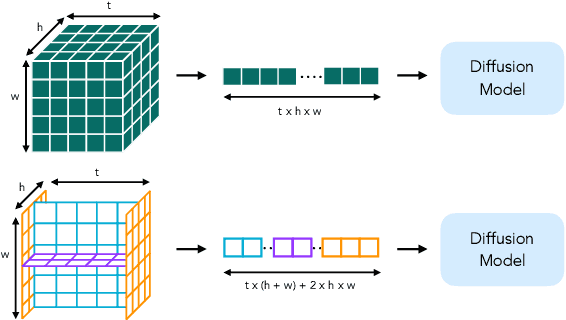
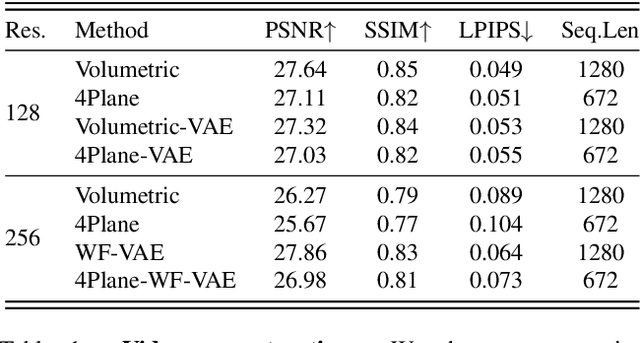
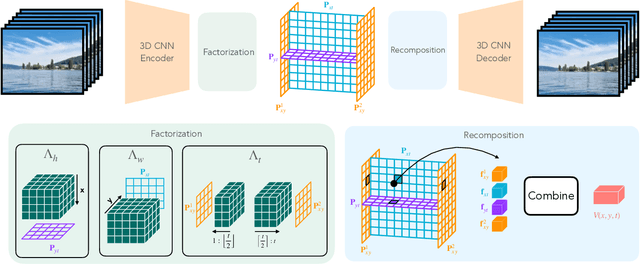

Latent variable generative models have emerged as powerful tools for generative tasks including image and video synthesis. These models are enabled by pretrained autoencoders that map high resolution data into a compressed lower dimensional latent space, where the generative models can subsequently be developed while requiring fewer computational resources. Despite their effectiveness, the direct application of latent variable models to higher dimensional domains such as videos continues to pose challenges for efficient training and inference. In this paper, we propose an autoencoder that projects volumetric data onto a four-plane factorized latent space that grows sublinearly with the input size, making it ideal for higher dimensional data like videos. The design of our factorized model supports straightforward adoption in a number of conditional generation tasks with latent diffusion models (LDMs), such as class-conditional generation, frame prediction, and video interpolation. Our results show that the proposed four-plane latent space retains a rich representation needed for high-fidelity reconstructions despite the heavy compression, while simultaneously enabling LDMs to operate with significant improvements in speed and memory.
Generalizable Patch-Based Neural Rendering
Jul 28, 2022
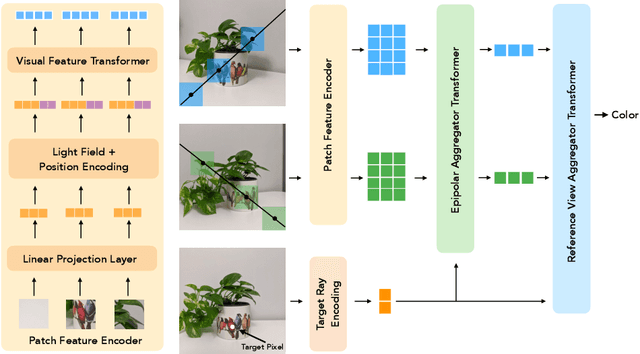
Neural rendering has received tremendous attention since the advent of Neural Radiance Fields (NeRF), and has pushed the state-of-the-art on novel-view synthesis considerably. The recent focus has been on models that overfit to a single scene, and the few attempts to learn models that can synthesize novel views of unseen scenes mostly consist of combining deep convolutional features with a NeRF-like model. We propose a different paradigm, where no deep features and no NeRF-like volume rendering are needed. Our method is capable of predicting the color of a target ray in a novel scene directly, just from a collection of patches sampled from the scene. We first leverage epipolar geometry to extract patches along the epipolar lines of each reference view. Each patch is linearly projected into a 1D feature vector and a sequence of transformers process the collection. For positional encoding, we parameterize rays as in a light field representation, with the crucial difference that the coordinates are canonicalized with respect to the target ray, which makes our method independent of the reference frame and improves generalization. We show that our approach outperforms the state-of-the-art on novel view synthesis of unseen scenes even when being trained with considerably less data than prior work.
Light Field Neural Rendering
Dec 17, 2021

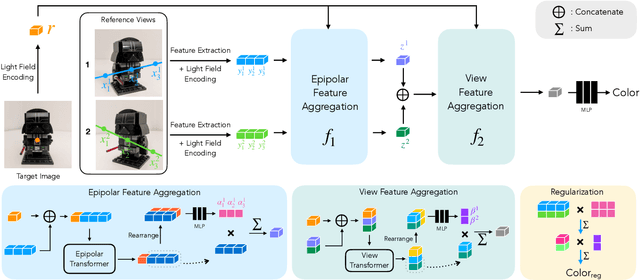
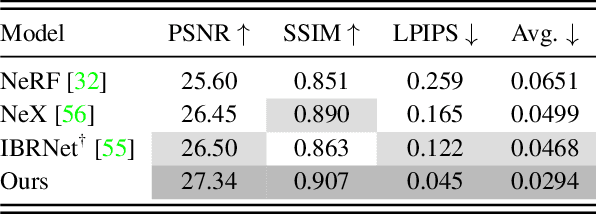
Classical light field rendering for novel view synthesis can accurately reproduce view-dependent effects such as reflection, refraction, and translucency, but requires a dense view sampling of the scene. Methods based on geometric reconstruction need only sparse views, but cannot accurately model non-Lambertian effects. We introduce a model that combines the strengths and mitigates the limitations of these two directions. By operating on a four-dimensional representation of the light field, our model learns to represent view-dependent effects accurately. By enforcing geometric constraints during training and inference, the scene geometry is implicitly learned from a sparse set of views. Concretely, we introduce a two-stage transformer-based model that first aggregates features along epipolar lines, then aggregates features along reference views to produce the color of a target ray. Our model outperforms the state-of-the-art on multiple forward-facing and 360{\deg} datasets, with larger margins on scenes with severe view-dependent variations.
Segmentation-grounded Scene Graph Generation
Apr 29, 2021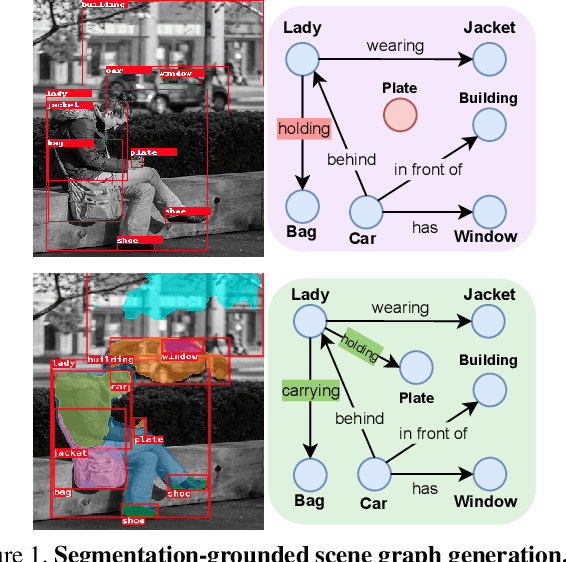
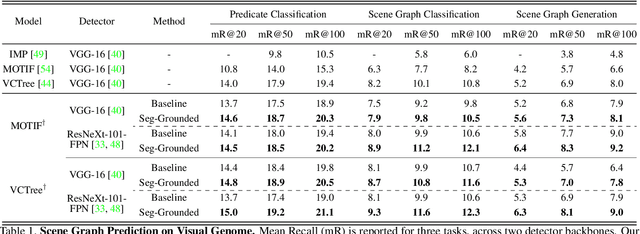
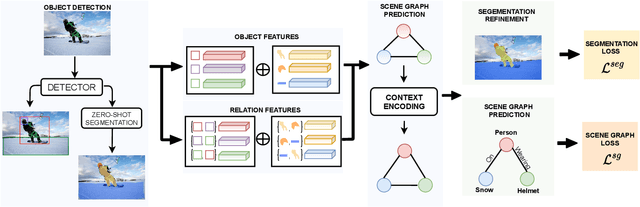
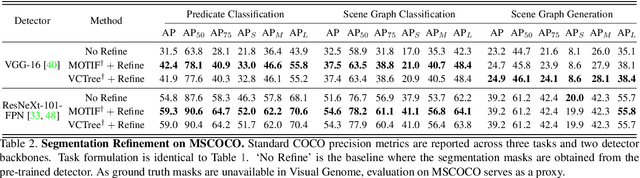
Scene graph generation has emerged as an important problem in computer vision. While scene graphs provide a grounded representation of objects, their locations and relations in an image, they do so only at the granularity of proposal bounding boxes. In this work, we propose the first, to our knowledge, framework for pixel-level segmentation-grounded scene graph generation. Our framework is agnostic to the underlying scene graph generation method and address the lack of segmentation annotations in target scene graph datasets (e.g., Visual Genome) through transfer and multi-task learning from, and with, an auxiliary dataset (e.g., MS COCO). Specifically, each target object being detected is endowed with a segmentation mask, which is expressed as a lingual-similarity weighted linear combination over categories that have annotations present in an auxiliary dataset. These inferred masks, along with a novel Gaussian attention mechanism which grounds the relations at a pixel-level within the image, allow for improved relation prediction. The entire framework is end-to-end trainable and is learned in a multi-task manner with both target and auxiliary datasets.
Energy-Based Learning for Scene Graph Generation
Mar 03, 2021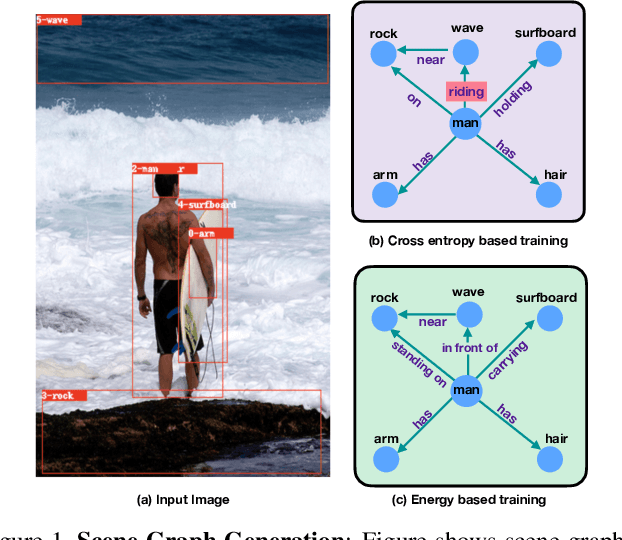

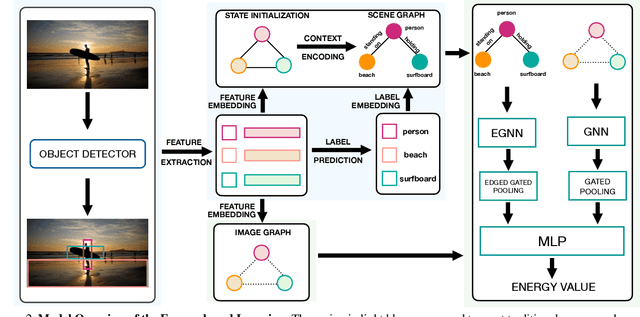
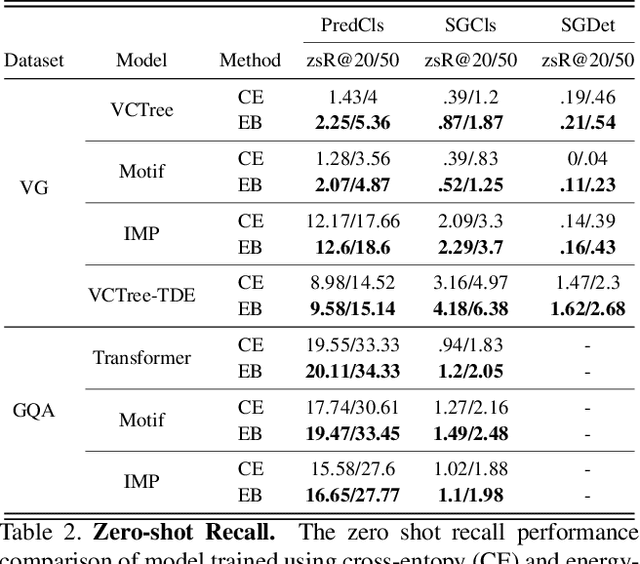
Traditional scene graph generation methods are trained using cross-entropy losses that treat objects and relationships as independent entities. Such a formulation, however, ignores the structure in the output space, in an inherently structured prediction problem. In this work, we introduce a novel energy-based learning framework for generating scene graphs. The proposed formulation allows for efficiently incorporating the structure of scene graphs in the output space. This additional constraint in the learning framework acts as an inductive bias and allows models to learn efficiently from a small number of labels. We use the proposed energy-based framework to train existing state-of-the-art models and obtain a significant performance improvement, of up to 21% and 27%, on the Visual Genome and GQA benchmark datasets, respectively. Furthermore, we showcase the learning efficiency of the proposed framework by demonstrating superior performance in the zero- and few-shot settings where data is scarce.