 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Simple but Effective Zero-shot Detection and Segmentation: Analysis and a Strong Baseline
Feb 14, 2023Methods for object detection and segmentation often require abundant instance-level annotations for training, which are time-consuming and expensive to collect. To address this, the task of zero-shot object detection (or segmentation) aims at learning effective methods for identifying and localizing object instances for the categories that have no supervision available. Constructing architectures for these tasks requires choosing from a myriad of design options, ranging from the form of the class encoding used to transfer information from seen to unseen categories, to the nature of the function being optimized for learning. In this work, we extensively study these design choices, and carefully construct a simple yet extremely effective zero-shot recognition method. Through extensive experiments on the MSCOCO dataset on object detection and segmentation, we highlight that our proposed method outperforms existing, considerably more complex, architectures. Our findings and method, which we propose as a competitive future baseline, point towards the need to revisit some of the recent design trends in zero-shot detection / segmentation.
Efficient Video Instance Segmentation via Tracklet Query and Proposal
Mar 03, 2022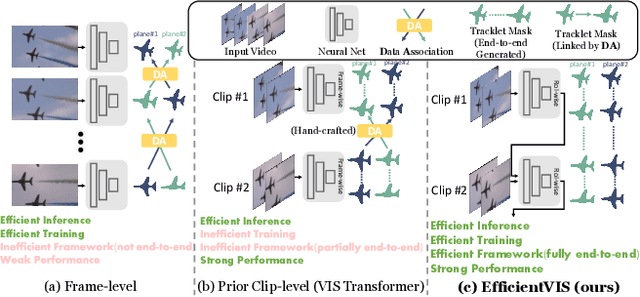
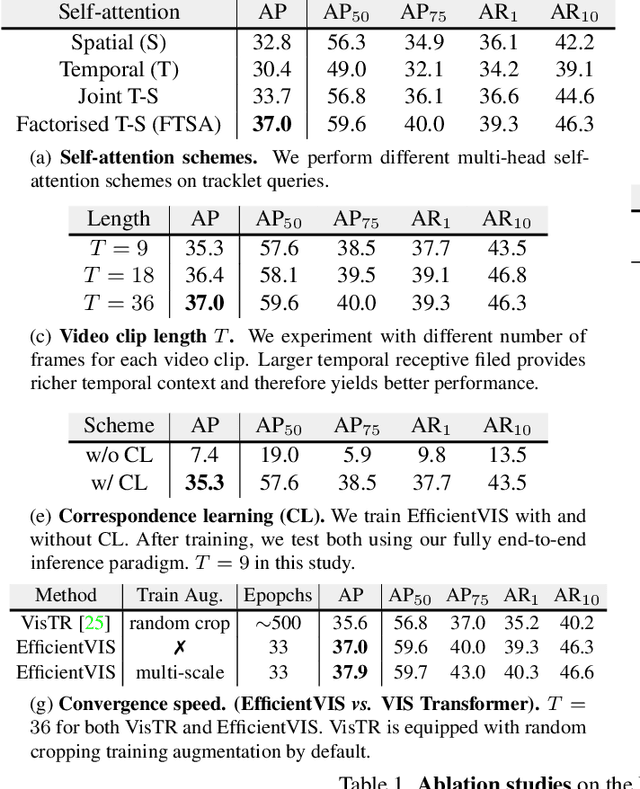
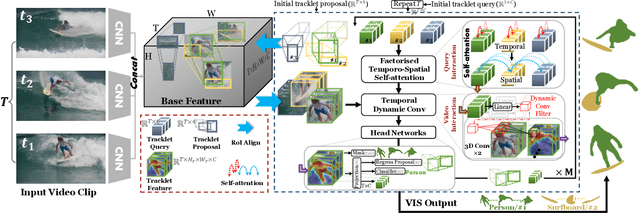
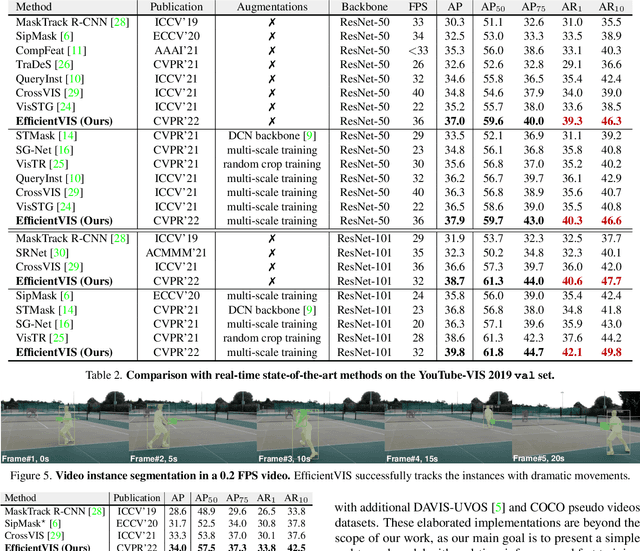
Video Instance Segmentation (VIS) aims to simultaneously classify, segment, and track multiple object instances in videos. Recent clip-level VIS takes a short video clip as input each time showing stronger performance than frame-level VIS (tracking-by-segmentation), as more temporal context from multiple frames is utilized. Yet, most clip-level methods are neither end-to-end learnable nor real-time. These limitations are addressed by the recent VIS transformer (VisTR) which performs VIS end-to-end within a clip. However, VisTR suffers from long training time due to its frame-wise dense attention. In addition, VisTR is not fully end-to-end learnable in multiple video clips as it requires a hand-crafted data association to link instance tracklets between successive clips. This paper proposes EfficientVIS, a fully end-to-end framework with efficient training and inference. At the core are tracklet query and tracklet proposal that associate and segment regions-of-interest (RoIs) across space and time by an iterative query-video interaction. We further propose a correspondence learning that makes tracklets linking between clips end-to-end learnable. Compared to VisTR, EfficientVIS requires 15x fewer training epochs while achieving state-of-the-art accuracy on the YouTube-VIS benchmark. Meanwhile, our method enables whole video instance segmentation in a single end-to-end pass without data association at all.
Energy-Based Learning for Scene Graph Generation
Mar 03, 2021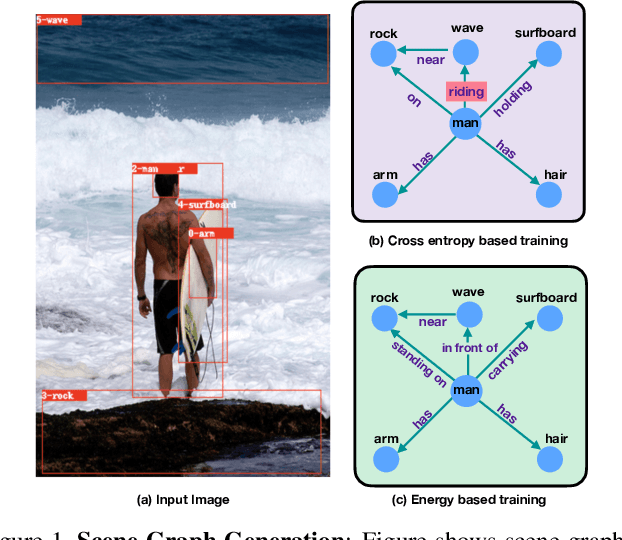

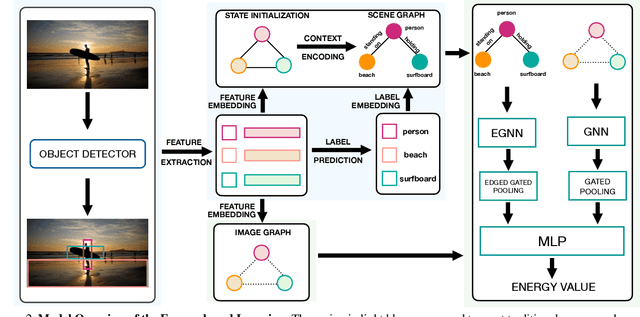
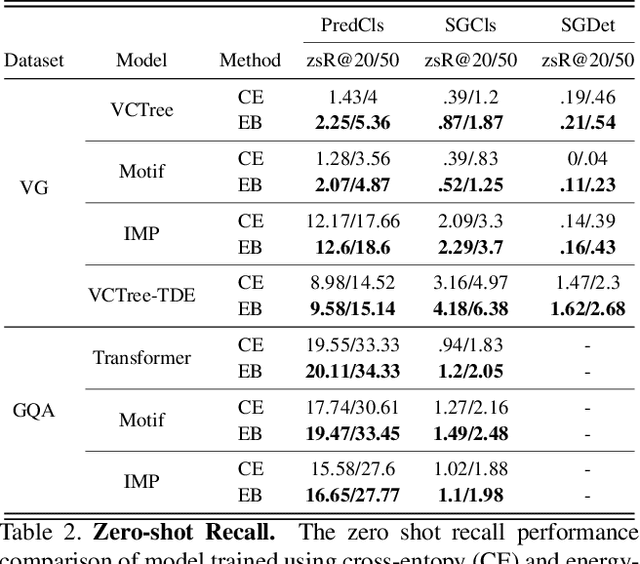
Traditional scene graph generation methods are trained using cross-entropy losses that treat objects and relationships as independent entities. Such a formulation, however, ignores the structure in the output space, in an inherently structured prediction problem. In this work, we introduce a novel energy-based learning framework for generating scene graphs. The proposed formulation allows for efficiently incorporating the structure of scene graphs in the output space. This additional constraint in the learning framework acts as an inductive bias and allows models to learn efficiently from a small number of labels. We use the proposed energy-based framework to train existing state-of-the-art models and obtain a significant performance improvement, of up to 21% and 27%, on the Visual Genome and GQA benchmark datasets, respectively. Furthermore, we showcase the learning efficiency of the proposed framework by demonstrating superior performance in the zero- and few-shot settings where data is scarce.
Multi-Task Learning from Videos via Efficient Inter-Frame Attention
Feb 18, 2020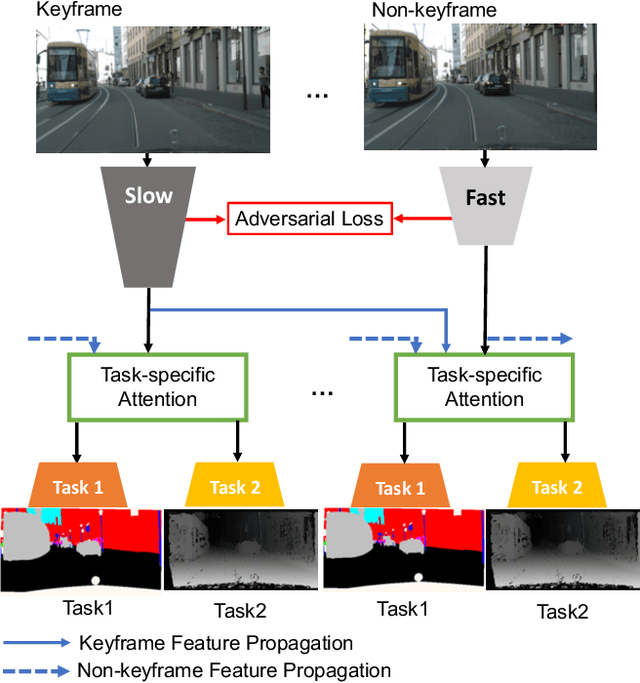
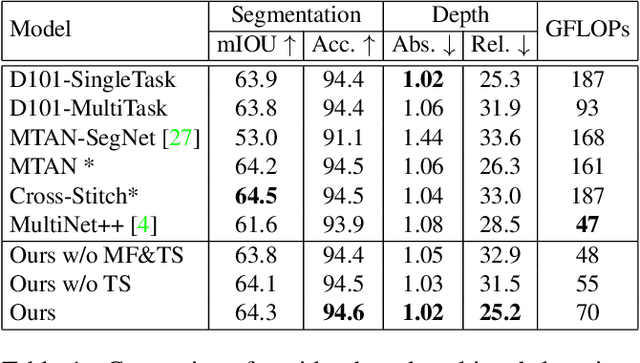
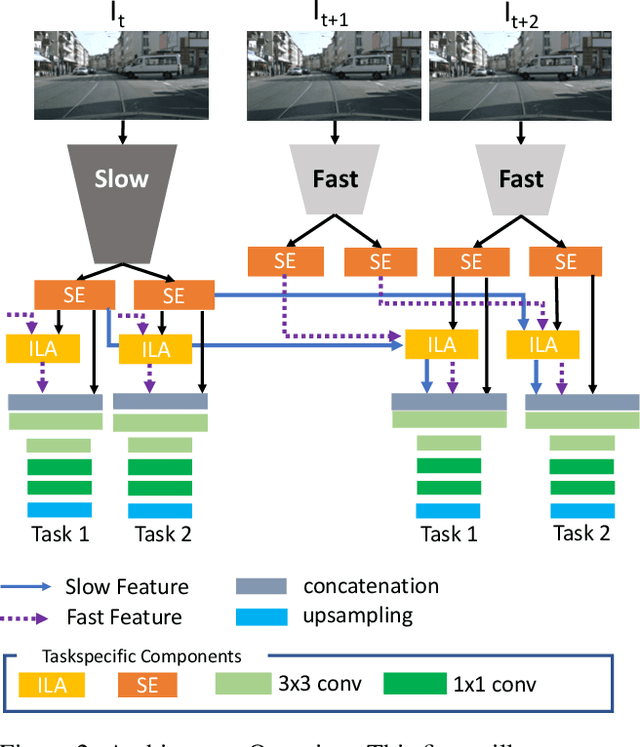
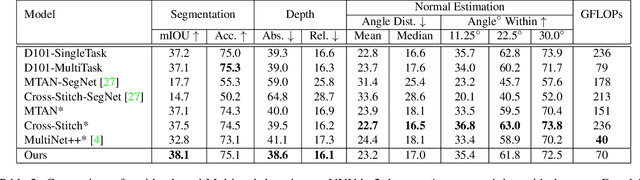
Prior work in multi-task learning has mainly focused on predictions on a single image. In this work, we present a new approach for multi-task learning from videos. Our approach contains a novel inter-frame attention module which allows learning of task-specific attention across frames. We embed the attention module in a "slow-fast" architecture, where the slower network runs on sparsely sampled keyframes and the lightweight shallow network runs on non-key frames at a high frame rate. We further propose an effective adversarial learning strategy to encourage the slow and fast network to learn similar features. The proposed architecture ensures low-latency multi-task learning while maintaining high quality prediction. Experiments show competitive accuracy compared to state-of-the-art on two multi-task learning benchmarks while reducing the number of floating point operations (FLOPs) by 70%. Meanwhile, our attention based feature propagation outperforms other feature propagation methods in accuracy by up to 90% reduction of FLOPs.