 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFour-Plane Factorized Video Autoencoders
Paper and Code
Dec 05, 2024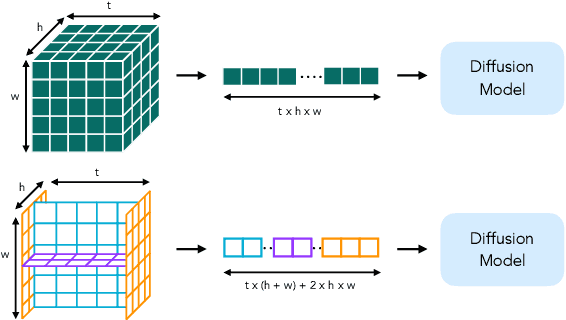
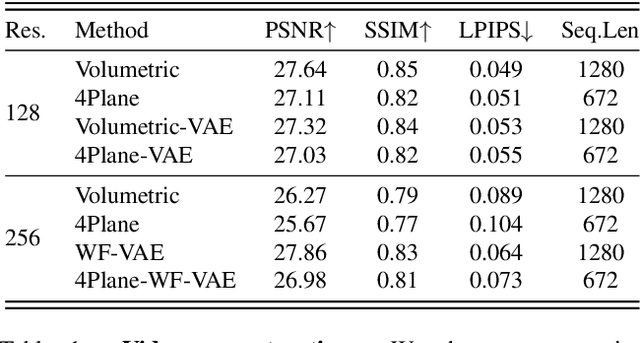
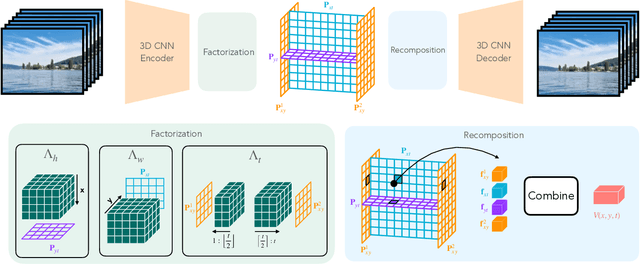

Latent variable generative models have emerged as powerful tools for generative tasks including image and video synthesis. These models are enabled by pretrained autoencoders that map high resolution data into a compressed lower dimensional latent space, where the generative models can subsequently be developed while requiring fewer computational resources. Despite their effectiveness, the direct application of latent variable models to higher dimensional domains such as videos continues to pose challenges for efficient training and inference. In this paper, we propose an autoencoder that projects volumetric data onto a four-plane factorized latent space that grows sublinearly with the input size, making it ideal for higher dimensional data like videos. The design of our factorized model supports straightforward adoption in a number of conditional generation tasks with latent diffusion models (LDMs), such as class-conditional generation, frame prediction, and video interpolation. Our results show that the proposed four-plane latent space retains a rich representation needed for high-fidelity reconstructions despite the heavy compression, while simultaneously enabling LDMs to operate with significant improvements in speed and memory.