Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generative Modeling: A Single Model is Not All You Need
Paper and Code
Feb 02, 2024

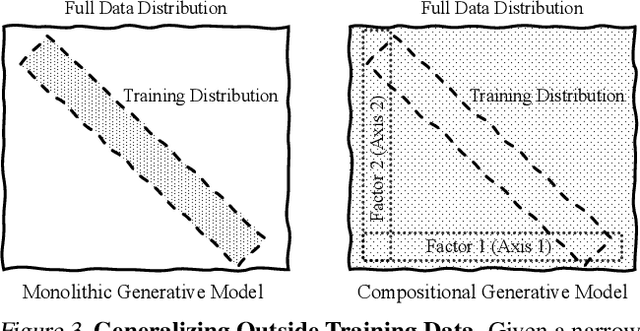

Large monolithic generative models trained on massive amounts of data have become an increasingly dominant approach in AI research. In this paper, we argue that we should instead construct large generative systems by composing smaller generative models together. We show how such a compositional generative approach enables us to learn distributions in a more data-efficient manner, enabling generalization to parts of the data distribution unseen at training time. We further show how this enables us to program and construct new generative models for tasks completely unseen at training. Finally, we show that in many cases, we can discover separate compositional components from data.
View paper on