 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUSSE'2020: Findings of the First Taxonomy Enrichment Task for the Russian language
Paper and Code
May 22, 2020
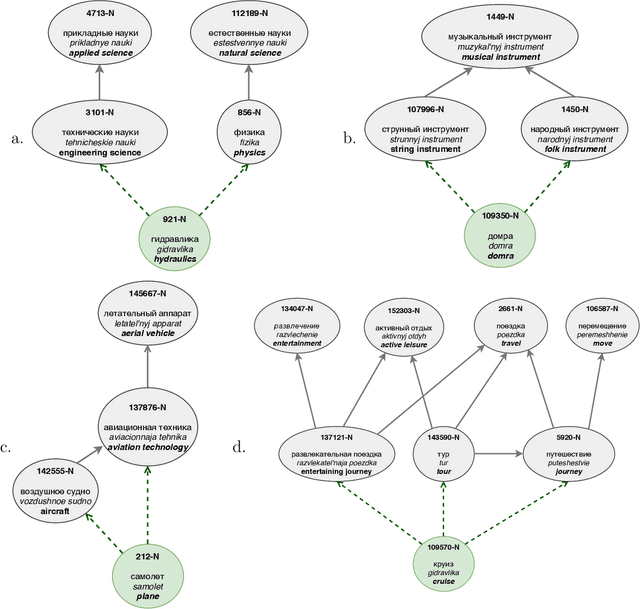
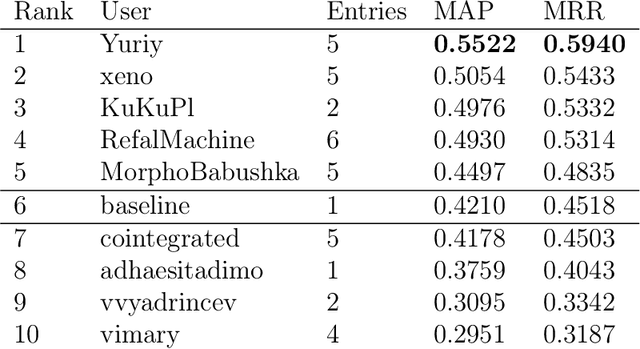
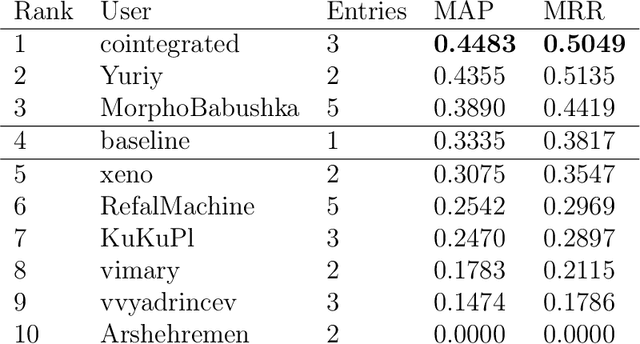
This paper describes the results of the first shared task on taxonomy enrichment for the Russian language. The participants were asked to extend an existing taxonomy with previously unseen words: for each new word their systems should provide a ranked list of possible (candidate) hypernyms. In comparison to the previous tasks for other languages, our competition has a more realistic task setting: new words were provided without definitions. Instead, we provided a textual corpus where these new terms occurred. For this evaluation campaign, we developed a new evaluation dataset based on unpublished RuWordNet data. The shared task features two tracks: "nouns" and "verbs". 16 teams participated in the task demonstrating high results with more than half of them outperforming the provided baseline.