 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Evaluation of Russian-language Architectures
Nov 19, 2025Multimodal large language models (MLLMs) are currently at the center of research attention, showing rapid progress in scale and capabilities, yet their intelligence, limitations, and risks remain insufficiently understood. To address these issues, particularly in the context of the Russian language, where no multimodal benchmarks currently exist, we introduce Mera Multi, an open multimodal evaluation framework for Russian-spoken architectures. The benchmark is instruction-based and encompasses default text, image, audio, and video modalities, comprising 18 newly constructed evaluation tasks for both general-purpose models and modality-specific architectures (image-to-text, video-to-text, and audio-to-text). Our contributions include: (i) a universal taxonomy of multimodal abilities; (ii) 18 datasets created entirely from scratch with attention to Russian cultural and linguistic specificity, unified prompts, and metrics; (iii) baseline results for both closed-source and open-source models; (iv) a methodology for preventing benchmark leakage, including watermarking and licenses for private sets. While our current focus is on Russian, the proposed benchmark provides a replicable methodology for constructing multimodal benchmarks in typologically diverse languages, particularly within the Slavic language family.
When Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA
Oct 06, 2025Hallucination detection remains a fundamental challenge for the safe and reliable deployment of large language models (LLMs), especially in applications requiring factual accuracy. Existing hallucination benchmarks often operate at the sequence level and are limited to English, lacking the fine-grained, multilingual supervision needed for a comprehensive evaluation. In this work, we introduce PsiloQA, a large-scale, multilingual dataset annotated with span-level hallucinations across 14 languages. PsiloQA is constructed through an automated three-stage pipeline: generating question-answer pairs from Wikipedia using GPT-4o, eliciting potentially hallucinated answers from diverse LLMs in a no-context setting, and automatically annotating hallucinated spans using GPT-4o by comparing against golden answers and retrieved context. We evaluate a wide range of hallucination detection methods -- including uncertainty quantification, LLM-based tagging, and fine-tuned encoder models -- and show that encoder-based models achieve the strongest performance across languages. Furthermore, PsiloQA demonstrates effective cross-lingual generalization and supports robust knowledge transfer to other benchmarks, all while being significantly more cost-efficient than human-annotated datasets. Our dataset and results advance the development of scalable, fine-grained hallucination detection in multilingual settings.
Will It Still Be True Tomorrow? Multilingual Evergreen Question Classification to Improve Trustworthy QA
May 27, 2025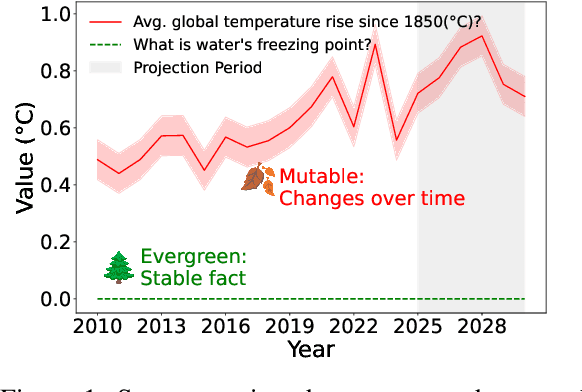

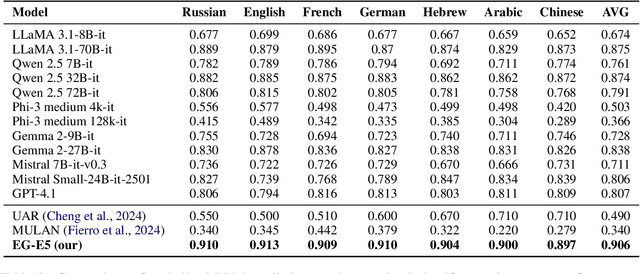
Large Language Models (LLMs) often hallucinate in question answering (QA) tasks. A key yet underexplored factor contributing to this is the temporality of questions -- whether they are evergreen (answers remain stable over time) or mutable (answers change). In this work, we introduce EverGreenQA, the first multilingual QA dataset with evergreen labels, supporting both evaluation and training. Using EverGreenQA, we benchmark 12 modern LLMs to assess whether they encode question temporality explicitly (via verbalized judgments) or implicitly (via uncertainty signals). We also train EG-E5, a lightweight multilingual classifier that achieves SoTA performance on this task. Finally, we demonstrate the practical utility of evergreen classification across three applications: improving self-knowledge estimation, filtering QA datasets, and explaining GPT-4o retrieval behavior.
Through the Looking Glass: Common Sense Consistency Evaluation of Weird Images
May 12, 2025Measuring how real images look is a complex task in artificial intelligence research. For example, an image of a boy with a vacuum cleaner in a desert violates common sense. We introduce a novel method, which we call Through the Looking Glass (TLG), to assess image common sense consistency using Large Vision-Language Models (LVLMs) and Transformer-based encoder. By leveraging LVLMs to extract atomic facts from these images, we obtain a mix of accurate facts. We proceed by fine-tuning a compact attention-pooling classifier over encoded atomic facts. Our TLG has achieved a new state-of-the-art performance on the WHOOPS! and WEIRD datasets while leveraging a compact fine-tuning component.
LLM-Independent Adaptive RAG: Let the Question Speak for Itself
May 07, 2025



Large Language Models~(LLMs) are prone to hallucinations, and Retrieval-Augmented Generation (RAG) helps mitigate this, but at a high computational cost while risking misinformation. Adaptive retrieval aims to retrieve only when necessary, but existing approaches rely on LLM-based uncertainty estimation, which remain inefficient and impractical. In this study, we introduce lightweight LLM-independent adaptive retrieval methods based on external information. We investigated 27 features, organized into 7 groups, and their hybrid combinations. We evaluated these methods on 6 QA datasets, assessing the QA performance and efficiency. The results show that our approach matches the performance of complex LLM-based methods while achieving significant efficiency gains, demonstrating the potential of external information for adaptive retrieval.
Don't Fight Hallucinations, Use Them: Estimating Image Realism using NLI over Atomic Facts
Mar 20, 2025Quantifying the realism of images remains a challenging problem in the field of artificial intelligence. For example, an image of Albert Einstein holding a smartphone violates common-sense because modern smartphone were invented after Einstein's death. We introduce a novel method for assessing image realism using Large Vision-Language Models (LVLMs) and Natural Language Inference (NLI). Our approach is based on the premise that LVLMs may generate hallucinations when confronted with images that defy common sense. Using LVLM to extract atomic facts from these images, we obtain a mix of accurate facts and erroneous hallucinations. We proceed by calculating pairwise entailment scores among these facts, subsequently aggregating these values to yield a singular reality score. This process serves to identify contradictions between genuine facts and hallucinatory elements, signaling the presence of images that violate common sense. Our approach has achieved a new state-of-the-art performance in zero-shot mode on the WHOOPS! dataset.
How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
Feb 20, 2025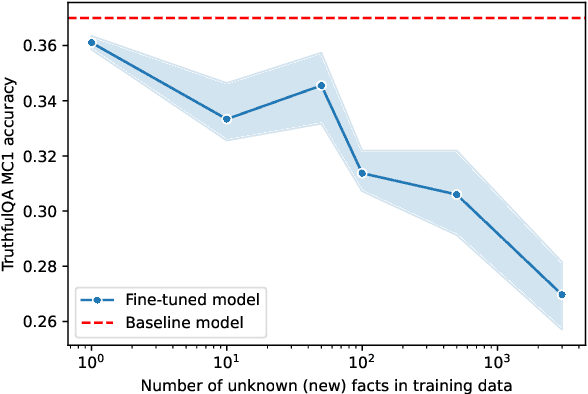

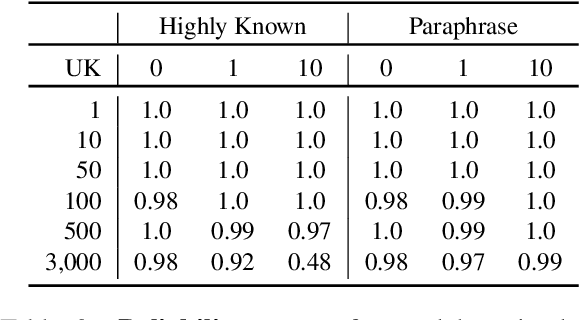
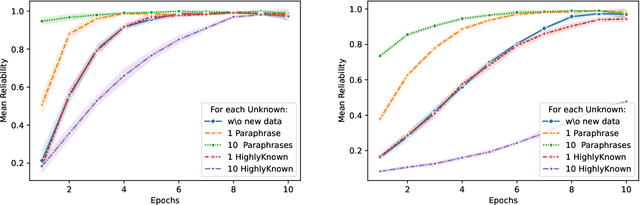
The performance of Large Language Models (LLMs) on many tasks is greatly limited by the knowledge learned during pre-training and stored in the model's parameters. Low-rank adaptation (LoRA) is a popular and efficient training technique for updating or domain-specific adaptation of LLMs. In this study, we investigate how new facts can be incorporated into the LLM using LoRA without compromising the previously learned knowledge. We fine-tuned Llama-3.1-8B-instruct using LoRA with varying amounts of new knowledge. Our experiments have shown that the best results are obtained when the training data contains a mixture of known and new facts. However, this approach is still potentially harmful because the model's performance on external question-answering benchmarks declines after such fine-tuning. When the training data is biased towards certain entities, the model tends to regress to few overrepresented answers. In addition, we found that the model becomes more confident and refuses to provide an answer in only few cases. These findings highlight the potential pitfalls of LoRA-based LLM updates and underscore the importance of training data composition and tuning parameters to balance new knowledge integration and general model capabilities.
DeepPavlov at SemEval-2024 Task 8: Leveraging Transfer Learning for Detecting Boundaries of Machine-Generated Texts
May 17, 2024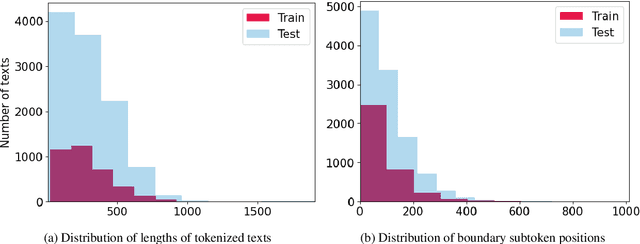



The Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection shared task in the SemEval-2024 competition aims to tackle the problem of misusing collaborative human-AI writing. Although there are a lot of existing detectors of AI content, they are often designed to give a binary answer and thus may not be suitable for more nuanced problem of finding the boundaries between human-written and machine-generated texts, while hybrid human-AI writing becomes more and more popular. In this paper, we address the boundary detection problem. Particularly, we present a pipeline for augmenting data for supervised fine-tuning of DeBERTaV3. We receive new best MAE score, according to the leaderboard of the competition, with this pipeline.
Knowledge Distillation of Russian Language Models with Reduction of Vocabulary
May 04, 2022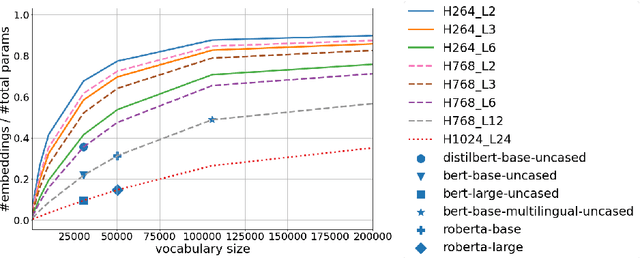
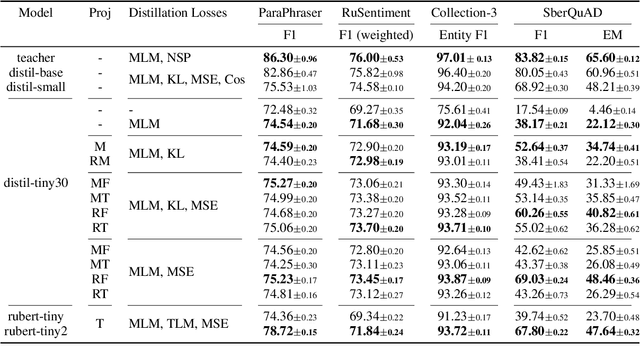

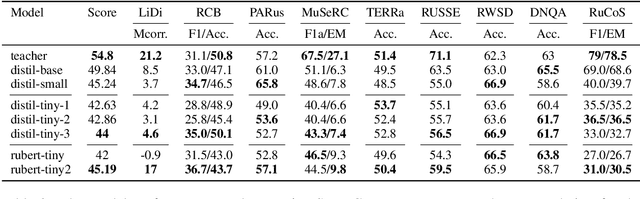
Today, transformer language models serve as a core component for majority of natural language processing tasks. Industrial application of such models requires minimization of computation time and memory footprint. Knowledge distillation is one of approaches to address this goal. Existing methods in this field are mainly focused on reducing the number of layers or dimension of embeddings/hidden representations. Alternative option is to reduce the number of tokens in vocabulary and therefore the embeddings matrix of the student model. The main problem with vocabulary minimization is mismatch between input sequences and output class distributions of a teacher and a student models. As a result, it is impossible to directly apply KL-based knowledge distillation. We propose two simple yet effective alignment techniques to make knowledge distillation to the students with reduced vocabulary. Evaluation of distilled models on a number of common benchmarks for Russian such as Russian SuperGLUE, SberQuAD, RuSentiment, ParaPhaser, Collection-3 demonstrated that our techniques allow to achieve compression from $17\times$ to $49\times$, while maintaining quality of $1.7\times$ compressed student with the full-sized vocabulary, but reduced number of Transformer layers only. We make our code and distilled models available.
Goal-Oriented Multi-Task BERT-Based Dialogue State Tracker
Feb 05, 2020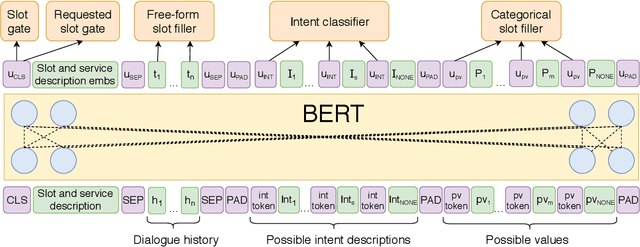

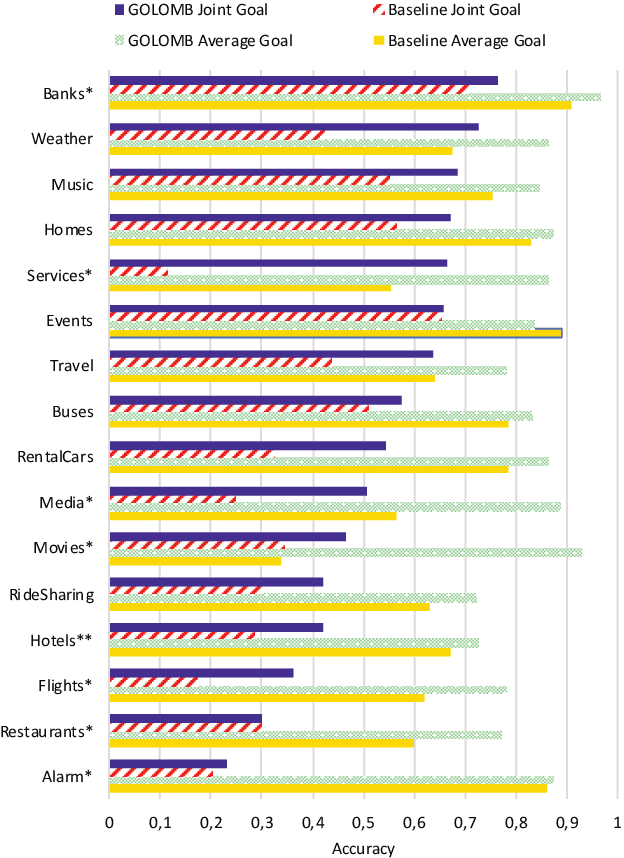
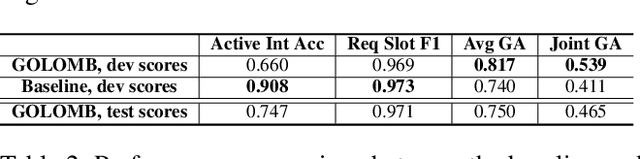
Dialogue State Tracking (DST) is a core component of virtual assistants such as Alexa or Siri. To accomplish various tasks, these assistants need to support an increasing number of services and APIs. The Schema-Guided State Tracking track of the 8th Dialogue System Technology Challenge highlighted the DST problem for unseen services. The organizers introduced the Schema-Guided Dialogue (SGD) dataset with multi-domain conversations and released a zero-shot dialogue state tracking model. In this work, we propose a GOaL-Oriented Multi-task BERT-based dialogue state tracker (GOLOMB) inspired by architectures for reading comprehension question answering systems. The model "queries" dialogue history with descriptions of slots and services as well as possible values of slots. This allows to transfer slot values in multi-domain dialogues and have a capability to scale to unseen slot types. Our model achieves a joint goal accuracy of 53.97% on the SGD dataset, outperforming the baseline model.