 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Self-Consistency with Ranking
Jun 03, 2026Self-consistency improves large language models by sampling multiple reasoning paths and selecting the most frequent answer, but majority voting often fails to recover correct answers that are already present among the samples. We address this limitation with Ranking-Improved Self-Consistency (RISC), which reformulates answer selection in self-consistency as a ranking problem. Instead of relying on a single uncertainty or confidence signal, RISC uses a lightweight LambdaRank model to score candidate answers with five carefully designed features that capture answer frequency, semantic centrality, and reasoning-trace consistency. We evaluate RISC on three datasets under a range of test-time budgets. Across datasets, RISC consistently achieves a better accuracy-efficiency trade-off than standard self-consistency and strong baselines, with particularly large gains on question answering benchmarks. Further analysis shows that the proposed features are individually useful and, more importantly, complementary, highlighting the value of learning to combine multiple informative signals for test-time answer selection.
Leveraging LLM Parametric Knowledge for Fact Checking without Retrieval
Mar 05, 2026Trustworthiness is a core research challenge for agentic AI systems built on Large Language Models (LLMs). To enhance trust, natural language claims from diverse sources, including human-written text, web content, and model outputs, are commonly checked for factuality by retrieving external knowledge and using an LLM to verify the faithfulness of claims to the retrieved evidence. As a result, such methods are constrained by retrieval errors and external data availability, while leaving the models intrinsic fact-verification capabilities largely unused. We propose the task of fact-checking without retrieval, focusing on the verification of arbitrary natural language claims, independent of their source. To study this setting, we introduce a comprehensive evaluation framework focused on generalization, testing robustness to (i) long-tail knowledge, (ii) variation in claim sources, (iii) multilinguality, and (iv) long-form generation. Across 9 datasets, 18 methods and 3 models, our experiments indicate that logit-based approaches often underperform compared to those that leverage internal model representations. Building on this finding, we introduce INTRA, a method that exploits interactions between internal representations and achieves state-of-the-art performance with strong generalization. More broadly, our work establishes fact-checking without retrieval as a promising research direction that can complement retrieval-based frameworks, improve scalability, and enable the use of such systems as reward signals during training or as components integrated into the generation process.
<think> So let's replace this phrase with insult... </think> Lessons learned from generation of toxic texts with LLMs
Sep 10, 2025



Modern Large Language Models (LLMs) are excellent at generating synthetic data. However, their performance in sensitive domains such as text detoxification has not received proper attention from the scientific community. This paper explores the possibility of using LLM-generated synthetic toxic data as an alternative to human-generated data for training models for detoxification. Using Llama 3 and Qwen activation-patched models, we generated synthetic toxic counterparts for neutral texts from ParaDetox and SST-2 datasets. Our experiments show that models fine-tuned on synthetic data consistently perform worse than those trained on human data, with a drop in performance of up to 30% in joint metrics. The root cause is identified as a critical lexical diversity gap: LLMs generate toxic content using a small, repetitive vocabulary of insults that fails to capture the nuances and variety of human toxicity. These findings highlight the limitations of current LLMs in this domain and emphasize the continued importance of diverse, human-annotated data for building robust detoxification systems.
Will It Still Be True Tomorrow? Multilingual Evergreen Question Classification to Improve Trustworthy QA
May 27, 2025

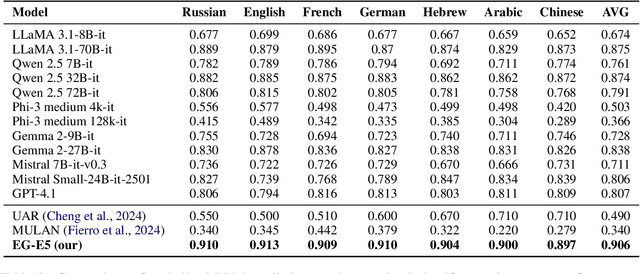
Large Language Models (LLMs) often hallucinate in question answering (QA) tasks. A key yet underexplored factor contributing to this is the temporality of questions -- whether they are evergreen (answers remain stable over time) or mutable (answers change). In this work, we introduce EverGreenQA, the first multilingual QA dataset with evergreen labels, supporting both evaluation and training. Using EverGreenQA, we benchmark 12 modern LLMs to assess whether they encode question temporality explicitly (via verbalized judgments) or implicitly (via uncertainty signals). We also train EG-E5, a lightweight multilingual classifier that achieves SoTA performance on this task. Finally, we demonstrate the practical utility of evergreen classification across three applications: improving self-knowledge estimation, filtering QA datasets, and explaining GPT-4o retrieval behavior.
LLM-Independent Adaptive RAG: Let the Question Speak for Itself
May 07, 2025



Large Language Models~(LLMs) are prone to hallucinations, and Retrieval-Augmented Generation (RAG) helps mitigate this, but at a high computational cost while risking misinformation. Adaptive retrieval aims to retrieve only when necessary, but existing approaches rely on LLM-based uncertainty estimation, which remain inefficient and impractical. In this study, we introduce lightweight LLM-independent adaptive retrieval methods based on external information. We investigated 27 features, organized into 7 groups, and their hybrid combinations. We evaluated these methods on 6 QA datasets, assessing the QA performance and efficiency. The results show that our approach matches the performance of complex LLM-based methods while achieving significant efficiency gains, demonstrating the potential of external information for adaptive retrieval.
How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
Feb 20, 2025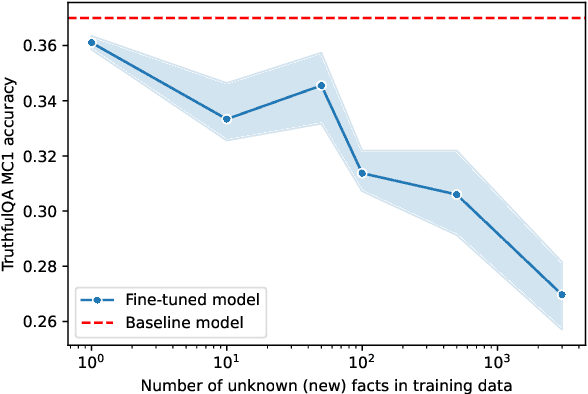

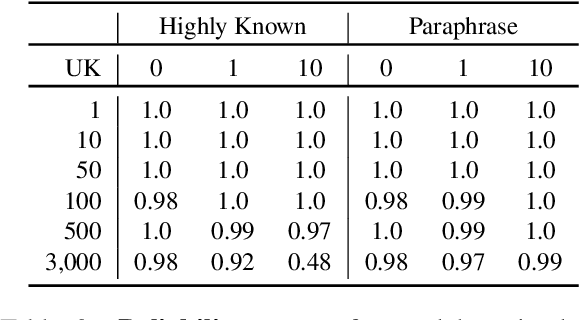
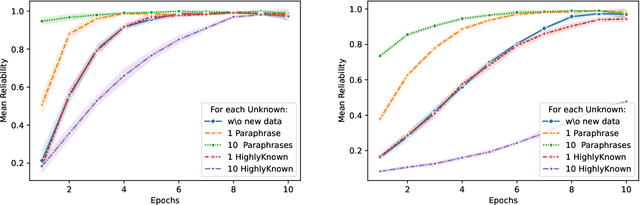
The performance of Large Language Models (LLMs) on many tasks is greatly limited by the knowledge learned during pre-training and stored in the model's parameters. Low-rank adaptation (LoRA) is a popular and efficient training technique for updating or domain-specific adaptation of LLMs. In this study, we investigate how new facts can be incorporated into the LLM using LoRA without compromising the previously learned knowledge. We fine-tuned Llama-3.1-8B-instruct using LoRA with varying amounts of new knowledge. Our experiments have shown that the best results are obtained when the training data contains a mixture of known and new facts. However, this approach is still potentially harmful because the model's performance on external question-answering benchmarks declines after such fine-tuning. When the training data is biased towards certain entities, the model tends to regress to few overrepresented answers. In addition, we found that the model becomes more confident and refuses to provide an answer in only few cases. These findings highlight the potential pitfalls of LoRA-based LLM updates and underscore the importance of training data composition and tuning parameters to balance new knowledge integration and general model capabilities.
SynthDetoxM: Modern LLMs are Few-Shot Parallel Detoxification Data Annotators
Feb 10, 2025



Existing approaches to multilingual text detoxification are hampered by the scarcity of parallel multilingual datasets. In this work, we introduce a pipeline for the generation of multilingual parallel detoxification data. We also introduce SynthDetoxM, a manually collected and synthetically generated multilingual parallel text detoxification dataset comprising 16,000 high-quality detoxification sentence pairs across German, French, Spanish and Russian. The data was sourced from different toxicity evaluation datasets and then rewritten with nine modern open-source LLMs in few-shot setting. Our experiments demonstrate that models trained on the produced synthetic datasets have superior performance to those trained on the human-annotated MultiParaDetox dataset even in data limited setting. Models trained on SynthDetoxM outperform all evaluated LLMs in few-shot setting. We release our dataset and code to help further research in multilingual text detoxification.