 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Selective LLM Autonomy from Copilot Feedback in Enterprise Customer Support Workflows
Apr 26, 2026We present a deployed system that automates end-to-end customer support workflows inside an enterprise Business Process Management (BPM) platform. The approach is scalable in production and reaches selective automation within two weeks for a new process, leveraging supervision already generated at scale: structured per-case UI interaction traces and low-overhead copilot feedback, where operators either accept a suggestion or provide a correction. A staged deployment pipeline trains a next UI action policy, learns a critic from copilot feedback to calibrate abstention, and executes only high-confidence steps in the background while deferring uncertain decisions to operators and resuming from the updated UI state. This setup lets one operator supervise multiple concurrent sessions and be interrupted only when the system is uncertain. The system operates on a schema-driven view of the BPM interface and includes monitoring and safe fallbacks for production. In production, it automated 45% of sessions and reduced average handling time by 39% without degrading support quality level.
Multimodal Evaluation of Russian-language Architectures
Nov 19, 2025Multimodal large language models (MLLMs) are currently at the center of research attention, showing rapid progress in scale and capabilities, yet their intelligence, limitations, and risks remain insufficiently understood. To address these issues, particularly in the context of the Russian language, where no multimodal benchmarks currently exist, we introduce Mera Multi, an open multimodal evaluation framework for Russian-spoken architectures. The benchmark is instruction-based and encompasses default text, image, audio, and video modalities, comprising 18 newly constructed evaluation tasks for both general-purpose models and modality-specific architectures (image-to-text, video-to-text, and audio-to-text). Our contributions include: (i) a universal taxonomy of multimodal abilities; (ii) 18 datasets created entirely from scratch with attention to Russian cultural and linguistic specificity, unified prompts, and metrics; (iii) baseline results for both closed-source and open-source models; (iv) a methodology for preventing benchmark leakage, including watermarking and licenses for private sets. While our current focus is on Russian, the proposed benchmark provides a replicable methodology for constructing multimodal benchmarks in typologically diverse languages, particularly within the Slavic language family.
When Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA
Oct 06, 2025Hallucination detection remains a fundamental challenge for the safe and reliable deployment of large language models (LLMs), especially in applications requiring factual accuracy. Existing hallucination benchmarks often operate at the sequence level and are limited to English, lacking the fine-grained, multilingual supervision needed for a comprehensive evaluation. In this work, we introduce PsiloQA, a large-scale, multilingual dataset annotated with span-level hallucinations across 14 languages. PsiloQA is constructed through an automated three-stage pipeline: generating question-answer pairs from Wikipedia using GPT-4o, eliciting potentially hallucinated answers from diverse LLMs in a no-context setting, and automatically annotating hallucinated spans using GPT-4o by comparing against golden answers and retrieved context. We evaluate a wide range of hallucination detection methods -- including uncertainty quantification, LLM-based tagging, and fine-tuned encoder models -- and show that encoder-based models achieve the strongest performance across languages. Furthermore, PsiloQA demonstrates effective cross-lingual generalization and supports robust knowledge transfer to other benchmarks, all while being significantly more cost-efficient than human-annotated datasets. Our dataset and results advance the development of scalable, fine-grained hallucination detection in multilingual settings.
Through the Looking Glass: Common Sense Consistency Evaluation of Weird Images
May 12, 2025Measuring how real images look is a complex task in artificial intelligence research. For example, an image of a boy with a vacuum cleaner in a desert violates common sense. We introduce a novel method, which we call Through the Looking Glass (TLG), to assess image common sense consistency using Large Vision-Language Models (LVLMs) and Transformer-based encoder. By leveraging LVLMs to extract atomic facts from these images, we obtain a mix of accurate facts. We proceed by fine-tuning a compact attention-pooling classifier over encoded atomic facts. Our TLG has achieved a new state-of-the-art performance on the WHOOPS! and WEIRD datasets while leveraging a compact fine-tuning component.
Don't Fight Hallucinations, Use Them: Estimating Image Realism using NLI over Atomic Facts
Mar 20, 2025Quantifying the realism of images remains a challenging problem in the field of artificial intelligence. For example, an image of Albert Einstein holding a smartphone violates common-sense because modern smartphone were invented after Einstein's death. We introduce a novel method for assessing image realism using Large Vision-Language Models (LVLMs) and Natural Language Inference (NLI). Our approach is based on the premise that LVLMs may generate hallucinations when confronted with images that defy common sense. Using LVLM to extract atomic facts from these images, we obtain a mix of accurate facts and erroneous hallucinations. We proceed by calculating pairwise entailment scores among these facts, subsequently aggregating these values to yield a singular reality score. This process serves to identify contradictions between genuine facts and hallucinatory elements, signaling the presence of images that violate common sense. Our approach has achieved a new state-of-the-art performance in zero-shot mode on the WHOOPS! dataset.
SmurfCat at PAN 2024 TextDetox: Alignment of Multilingual Transformers for Text Detoxification
Jul 10, 2024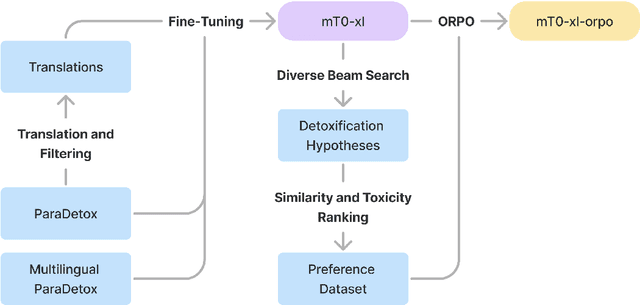

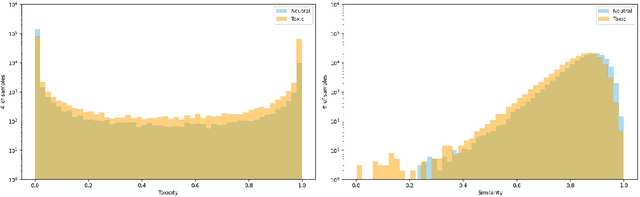
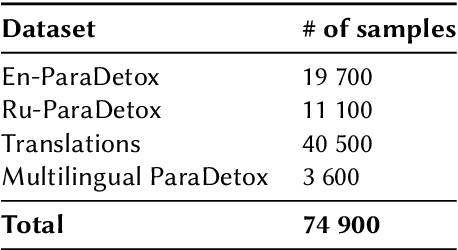
This paper presents a solution for the Multilingual Text Detoxification task in the PAN-2024 competition of the SmurfCat team. Using data augmentation through machine translation and a special filtering procedure, we collected an additional multilingual parallel dataset for text detoxification. Using the obtained data, we fine-tuned several multilingual sequence-to-sequence models, such as mT0 and Aya, on a text detoxification task. We applied the ORPO alignment technique to the final model. Our final model has only 3.7 billion parameters and achieves state-of-the-art results for the Ukrainian language and near state-of-the-art results for other languages. In the competition, our team achieved first place in the automated evaluation with a score of 0.52 and second place in the final human evaluation with a score of 0.74.
S3: A Simple Strong Sample-effective Multimodal Dialog System
Jun 26, 2024



In this work, we present a conceptually simple yet powerful baseline for the multimodal dialog task, an S3 model, that achieves near state-of-the-art results on two compelling leaderboards: MMMU and AI Journey Contest 2023. The system is based on a pre-trained large language model, pre-trained modality encoders for image and audio, and a trainable modality projector. The proposed effective data mixture for training such an architecture demonstrates that a multimodal model based on a strong language model and trained on a small amount of multimodal data can perform efficiently in the task of multimodal dialog.
SmurfCat at SemEval-2024 Task 6: Leveraging Synthetic Data for Hallucination Detection
Apr 09, 2024In this paper, we present our novel systems developed for the SemEval-2024 hallucination detection task. Our investigation spans a range of strategies to compare model predictions with reference standards, encompassing diverse baselines, the refinement of pre-trained encoders through supervised learning, and an ensemble approaches utilizing several high-performing models. Through these explorations, we introduce three distinct methods that exhibit strong performance metrics. To amplify our training data, we generate additional training samples from unlabelled training subset. Furthermore, we provide a detailed comparative analysis of our approaches. Notably, our premier method achieved a commendable 9th place in the competition's model-agnostic track and 17th place in model-aware track, highlighting its effectiveness and potential.