 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmurfCat at PAN 2024 TextDetox: Alignment of Multilingual Transformers for Text Detoxification
Jul 10, 2024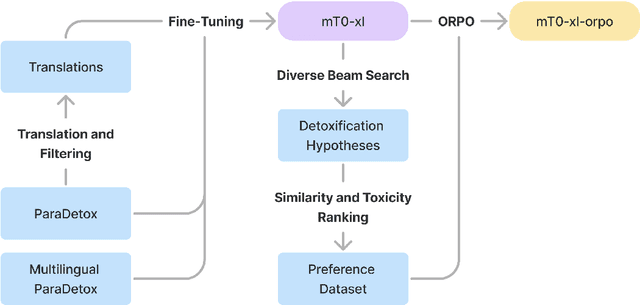

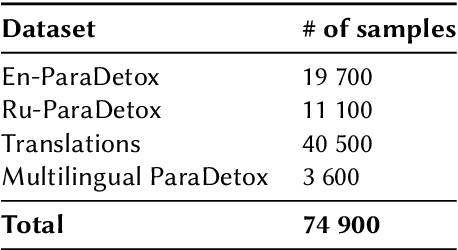
This paper presents a solution for the Multilingual Text Detoxification task in the PAN-2024 competition of the SmurfCat team. Using data augmentation through machine translation and a special filtering procedure, we collected an additional multilingual parallel dataset for text detoxification. Using the obtained data, we fine-tuned several multilingual sequence-to-sequence models, such as mT0 and Aya, on a text detoxification task. We applied the ORPO alignment technique to the final model. Our final model has only 3.7 billion parameters and achieves state-of-the-art results for the Ukrainian language and near state-of-the-art results for other languages. In the competition, our team achieved first place in the automated evaluation with a score of 0.52 and second place in the final human evaluation with a score of 0.74.