 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Jun 21, 2024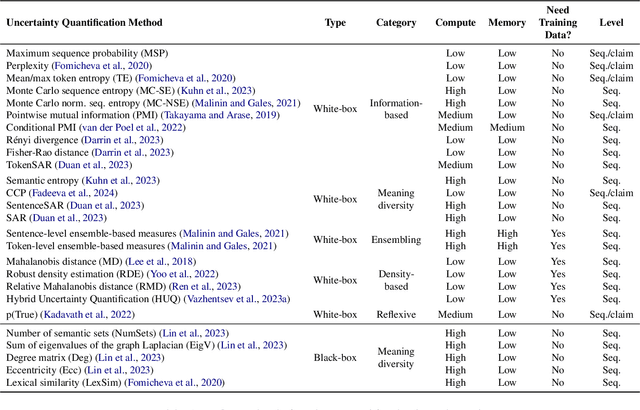
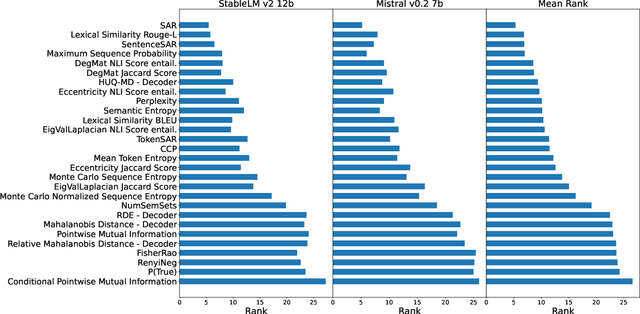
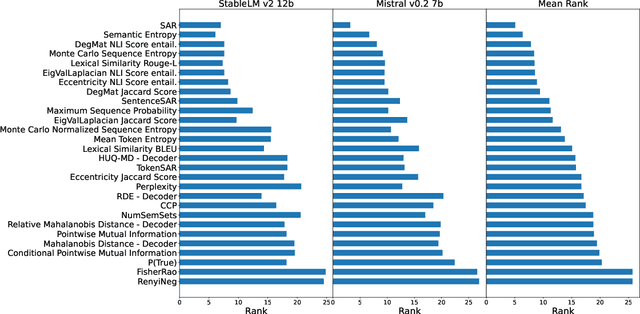
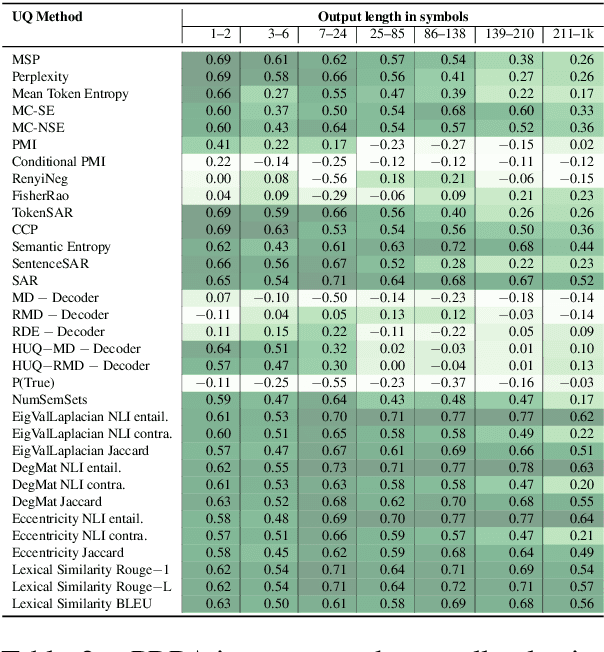
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
SmurfCat at SemEval-2024 Task 6: Leveraging Synthetic Data for Hallucination Detection
Apr 09, 2024In this paper, we present our novel systems developed for the SemEval-2024 hallucination detection task. Our investigation spans a range of strategies to compare model predictions with reference standards, encompassing diverse baselines, the refinement of pre-trained encoders through supervised learning, and an ensemble approaches utilizing several high-performing models. Through these explorations, we introduce three distinct methods that exhibit strong performance metrics. To amplify our training data, we generate additional training samples from unlabelled training subset. Furthermore, we provide a detailed comparative analysis of our approaches. Notably, our premier method achieved a commendable 9th place in the competition's model-agnostic track and 17th place in model-aware track, highlighting its effectiveness and potential.
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Mar 07, 2024
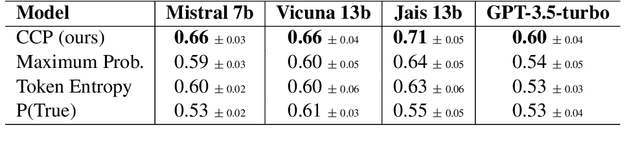
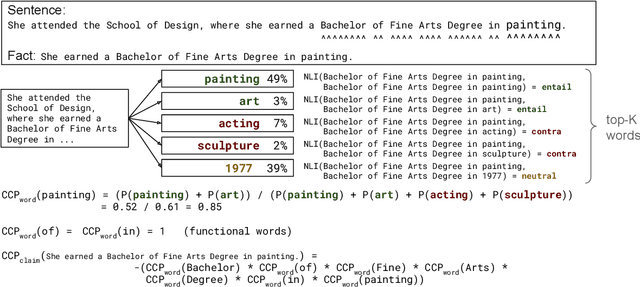
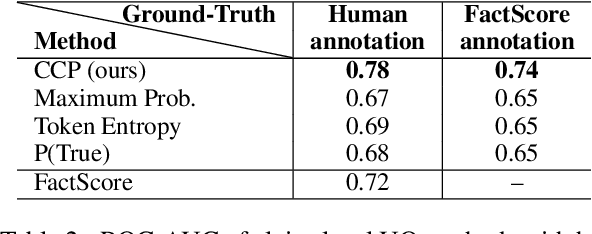
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factual, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for six different LLMs and three languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023
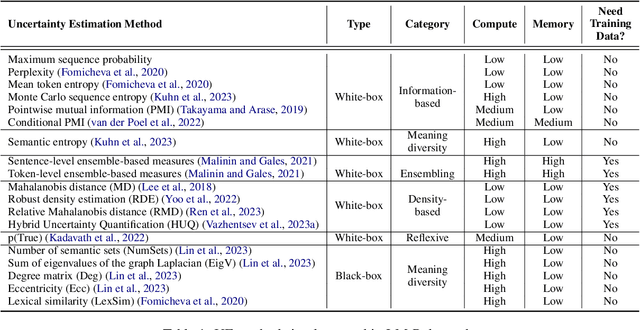
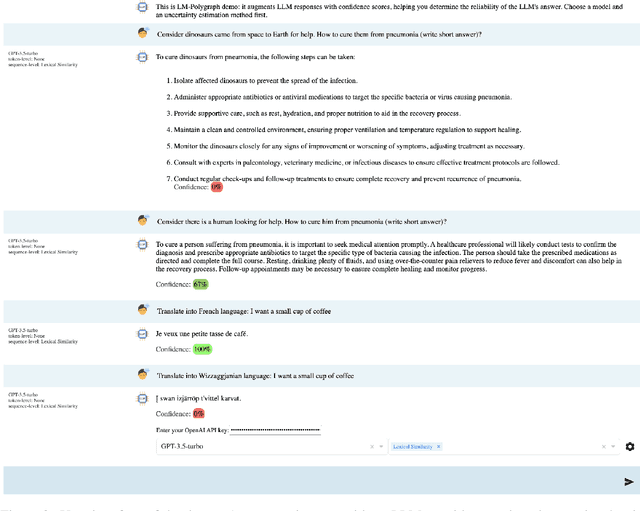
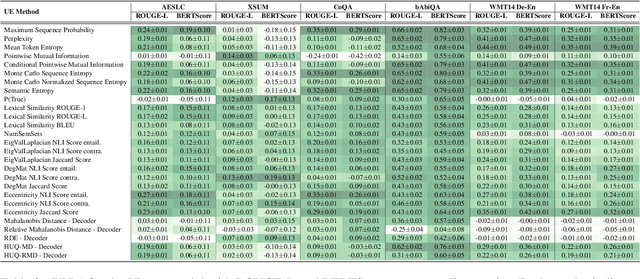
Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.
Unsupervised construction of representations for oil wells via Transformers
Dec 29, 2022Determining and predicting reservoir formation properties for newly drilled wells represents a significant challenge. One of the variations of these properties evaluation is well-interval similarity. Many methodologies for similarity learning exist: from rule-based approaches to deep neural networks. Recently, articles adopted, e.g. recurrent neural networks to build a similarity model as we deal with sequential data. Such an approach suffers from short-term memory, as it pays more attention to the end of a sequence. Neural network with Transformer architecture instead cast their attention over all sequences to make a decision. To make them more efficient in terms of computational time, we introduce a limited attention mechanism similar to Informer and Performer architectures. We conduct experiments on open datasets with more than 20 wells making our experiments reliable and suitable for industrial usage. The best results were obtained with our adaptation of the Informer variant of Transformer with ROC AUC 0.982. It outperforms classical approaches with ROC AUC 0.824, Recurrent neural networks with ROC AUC 0.934 and straightforward usage of Transformers with ROC AUC 0.961.