 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
Token-Level Density-Based Uncertainty Quantification Methods for Eliciting Truthfulness of Large Language Models
Feb 20, 2025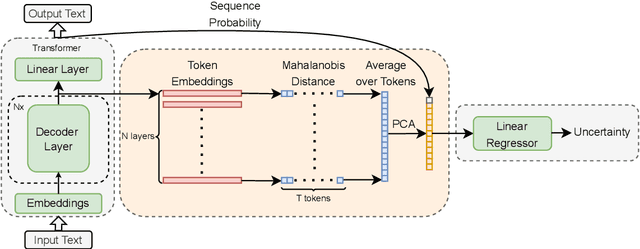

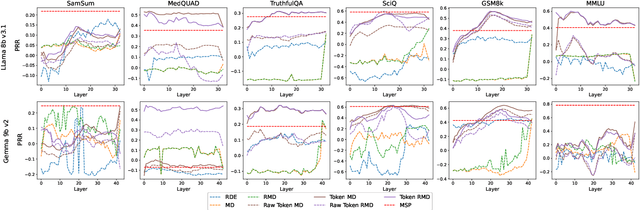
Uncertainty quantification (UQ) is a prominent approach for eliciting truthful answers from large language models (LLMs). To date, information-based and consistency-based UQ have been the dominant UQ methods for text generation via LLMs. Density-based methods, despite being very effective for UQ in text classification with encoder-based models, have not been very successful with generative LLMs. In this work, we adapt Mahalanobis Distance (MD) - a well-established UQ technique in classification tasks - for text generation and introduce a new supervised UQ method. Our method extracts token embeddings from multiple layers of LLMs, computes MD scores for each token, and uses linear regression trained on these features to provide robust uncertainty scores. Through extensive experiments on eleven datasets, we demonstrate that our approach substantially improves over existing UQ methods, providing accurate and computationally efficient uncertainty scores for both sequence-level selective generation and claim-level fact-checking tasks. Our method also exhibits strong generalization to out-of-domain data, making it suitable for a wide range of LLM-based applications.
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Jun 21, 2024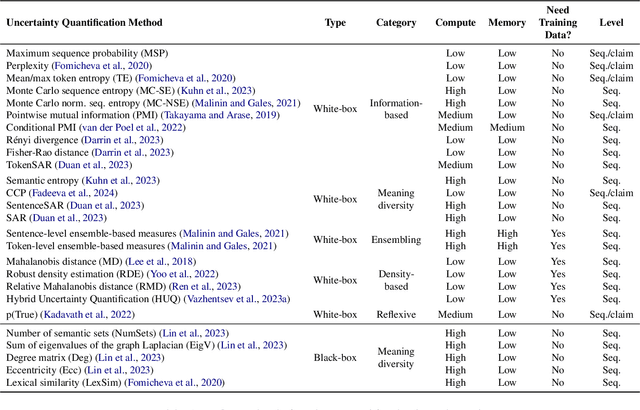
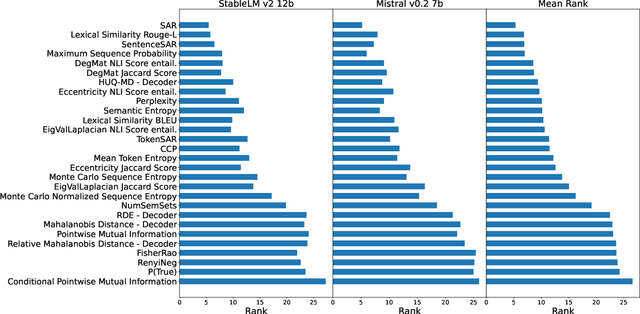
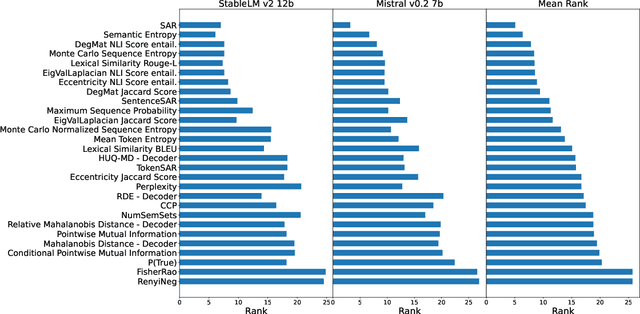
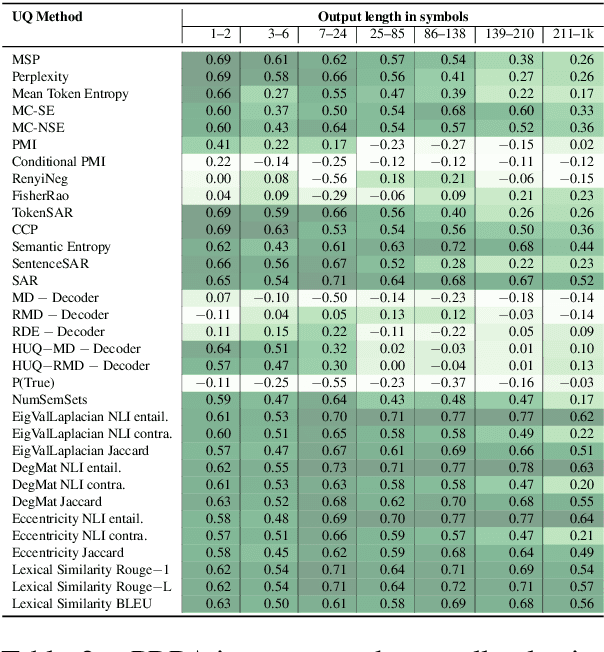
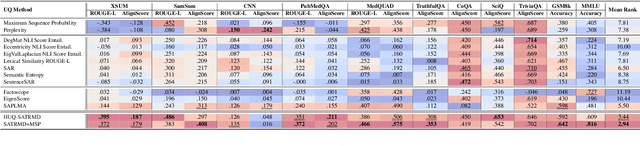
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.