 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Throw Away Your Beams: Improving Consistency-based Uncertainties in LLMs via Beam Search
Dec 10, 2025Consistency-based methods have emerged as an effective approach to uncertainty quantification (UQ) in large language models. These methods typically rely on several generations obtained via multinomial sampling, measuring their agreement level. However, in short-form QA, multinomial sampling is prone to producing duplicates due to peaked distributions, and its stochasticity introduces considerable variance in uncertainty estimates across runs. We introduce a new family of methods that employ beam search to generate candidates for consistency-based UQ, yielding improved performance and reduced variance compared to multinomial sampling. We also provide a theoretical lower bound on the beam set probability mass under which beam search achieves a smaller error than multinomial sampling. We empirically evaluate our approach on six QA datasets and find that its consistent improvements over multinomial sampling lead to state-of-the-art UQ performance.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking the Output of Retrieval Augmented Generation
May 28, 2025Large Language Models (LLMs) enhanced with external knowledge retrieval, an approach known as Retrieval-Augmented Generation (RAG), have shown strong performance in open-domain question answering. However, RAG systems remain susceptible to hallucinations: factually incorrect outputs that may arise either from inconsistencies in the model's internal knowledge or incorrect use of the retrieved context. Existing approaches often conflate factuality with faithfulness to the retrieved context, misclassifying factually correct statements as hallucinations if they are not directly supported by the retrieval. In this paper, we introduce FRANQ (Faithfulness-based Retrieval Augmented UNcertainty Quantification), a novel method for hallucination detection in RAG outputs. FRANQ applies different Uncertainty Quantification (UQ) techniques to estimate factuality based on whether a statement is faithful to the retrieved context or not. To evaluate FRANQ and other UQ techniques for RAG, we present a new long-form Question Answering (QA) dataset annotated for both factuality and faithfulness, combining automated labeling with manual validation of challenging examples. Extensive experiments on long- and short-form QA across multiple datasets and LLMs show that FRANQ achieves more accurate detection of factual errors in RAG-generated responses compared to existing methods.
UNCERTAINTY-LINE: Length-Invariant Estimation of Uncertainty for Large Language Models
May 25, 2025Large Language Models (LLMs) have become indispensable tools across various applications, making it more important than ever to ensure the quality and the trustworthiness of their outputs. This has led to growing interest in uncertainty quantification (UQ) methods for assessing the reliability of LLM outputs. Many existing UQ techniques rely on token probabilities, which inadvertently introduces a bias with respect to the length of the output. While some methods attempt to account for this, we demonstrate that such biases persist even in length-normalized approaches. To address the problem, here we propose UNCERTAINTY-LINE: (Length-INvariant Estimation), a simple debiasing procedure that regresses uncertainty scores on output length and uses the residuals as corrected, length-invariant estimates. Our method is post-hoc, model-agnostic, and applicable to a range of UQ measures. Through extensive evaluation on machine translation, summarization, and question-answering tasks, we demonstrate that UNCERTAINTY-LINE: consistently improves over even nominally length-normalized UQ methods uncertainty estimates across multiple metrics and models.
CoCoA: A Generalized Approach to Uncertainty Quantification by Integrating Confidence and Consistency of LLM Outputs
Feb 07, 2025Uncertainty quantification (UQ) methods for Large Language Models (LLMs) encompasses a variety of approaches, with two major types being particularly prominent: information-based, which focus on model confidence expressed as token probabilities, and consistency-based, which assess the semantic relationship between multiple outputs generated using repeated sampling. Several recent methods have combined these two approaches and shown impressive performance in various applications. However, they sometimes fail to outperform much simpler baseline methods. Our investigation reveals distinctive characteristics of LLMs as probabilistic models, which help to explain why these UQ methods underperform in certain tasks. Based on these findings, we propose a new way of synthesizing model confidence and output consistency that leads to a family of efficient and robust UQ methods. We evaluate our approach across a variety of tasks such as question answering, abstractive summarization, and machine translation, demonstrating sizable improvements over state-of-the-art UQ approaches.
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Jun 21, 2024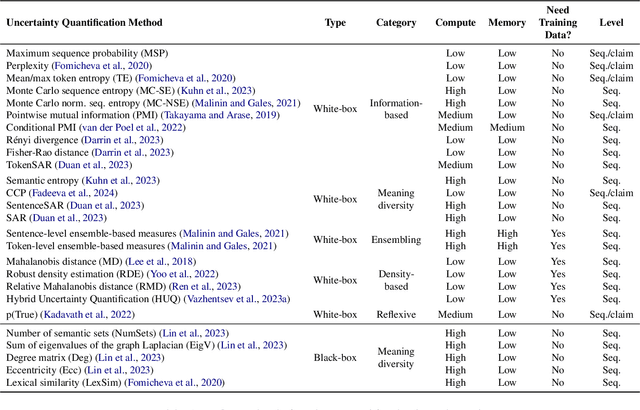
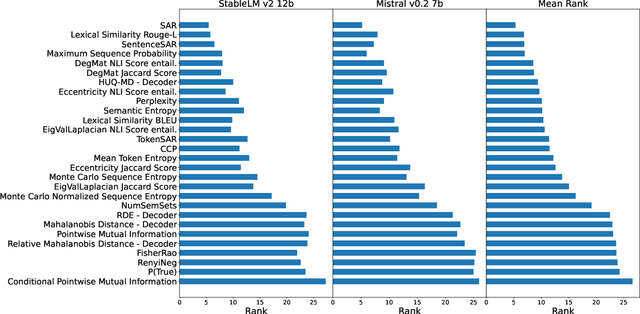
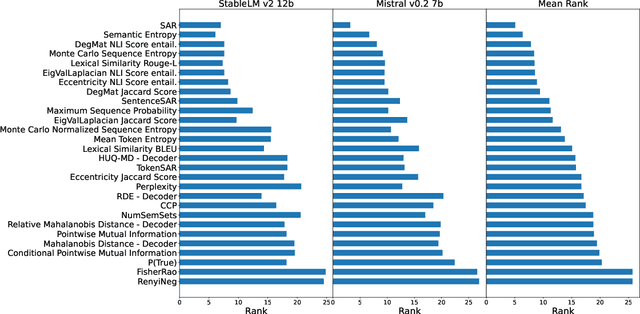
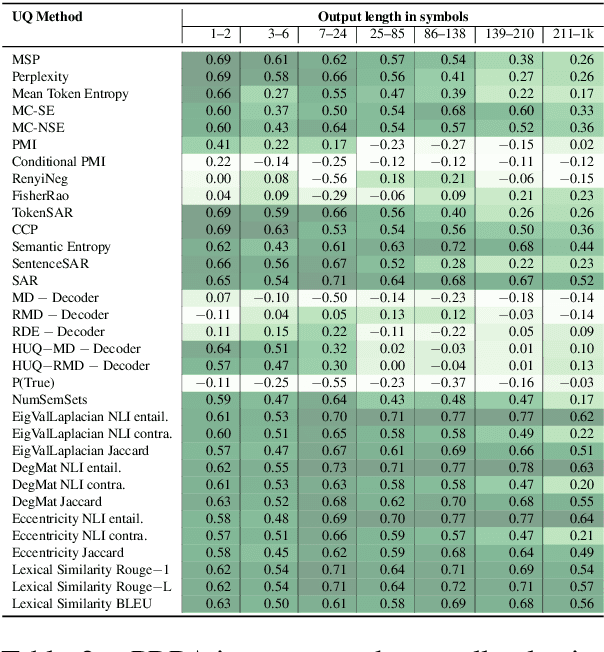
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023
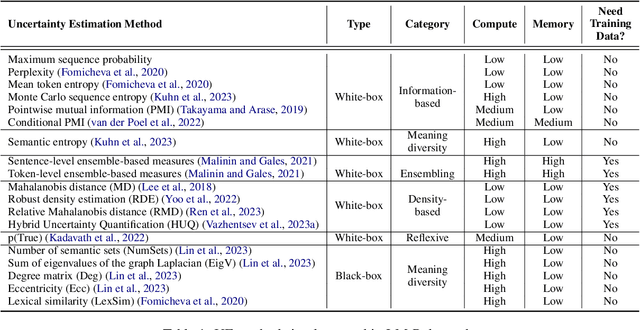
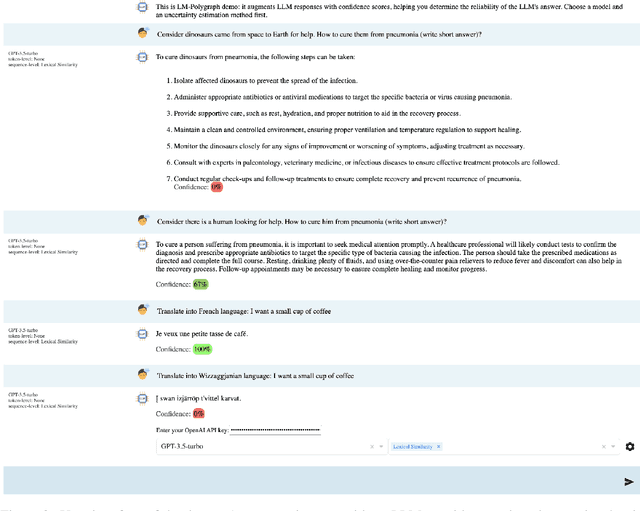
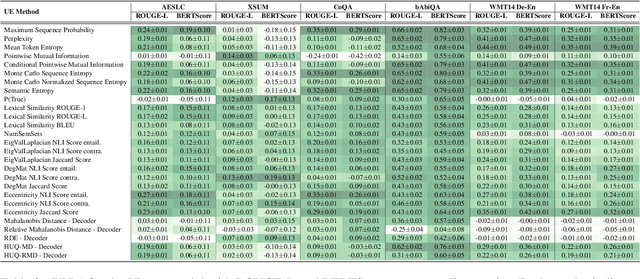
Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.
Embedded Ensembles: Infinite Width Limit and Operating Regimes
Feb 24, 2022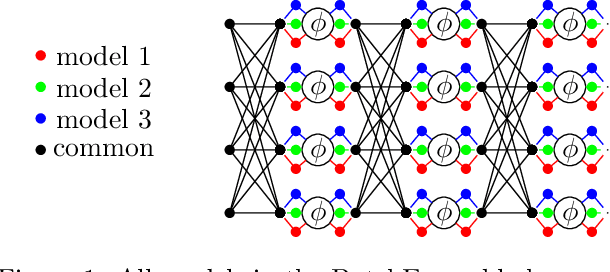
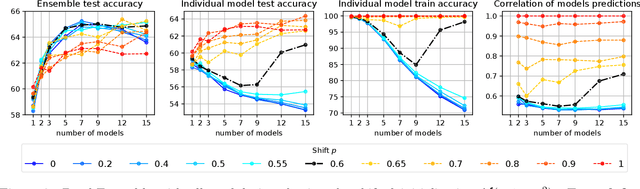
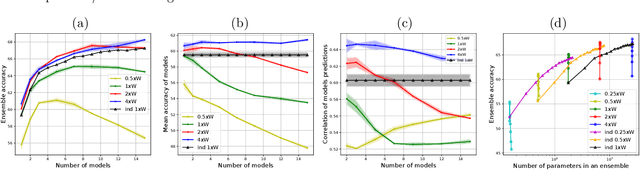
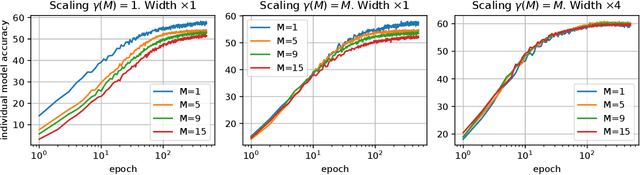
A memory efficient approach to ensembling neural networks is to share most weights among the ensembled models by means of a single reference network. We refer to this strategy as Embedded Ensembling (EE); its particular examples are BatchEnsembles and Monte-Carlo dropout ensembles. In this paper we perform a systematic theoretical and empirical analysis of embedded ensembles with different number of models. Theoretically, we use a Neural-Tangent-Kernel-based approach to derive the wide network limit of the gradient descent dynamics. In this limit, we identify two ensemble regimes - independent and collective - depending on the architecture and initialization strategy of ensemble models. We prove that in the independent regime the embedded ensemble behaves as an ensemble of independent models. We confirm our theoretical prediction with a wide range of experiments with finite networks, and further study empirically various effects such as transition between the two regimes, scaling of ensemble performance with the network width and number of models, and dependence of performance on a number of architecture and hyperparameter choices.