 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA prism hierarchy of learning regimes in large linear autoencoders
Jun 03, 2026Theoretical studies of machine learning models commonly consider different limiting regimes in which the learning dynamics of gradient descent becomes theoretically tractable. It is, however, desirable to have a systematically obtained picture of all qualitatively different extreme learning regimes for a particular type of models. In this paper we propose such a picture for large weight-tied linear autoencoders characterized by input and latent dimensions, initialization magnitude, and training set size. This model is nonlinear in the weights and its gradient flow does not have a general theoretical solution. We show that at the level of the formal loss-expansion hierarchy, its extreme regimes are naturally associated with faces of a triangular prism. In particular, there are five basic extreme regimes associated with the 2-faces of the prism: (1) large-data, (2) small-data, (3) mean-field, (4) narrow-latent, and (5) free. For regimes (1,2,3,4), we derive explicit expressions for both train and population limiting loss evolutions under gradient flow, obtaining very good agreement with experimental results.
Gradient Flow Through Diagram Expansions: Learning Regimes and Explicit Solutions
Feb 04, 2026We develop a general mathematical framework to analyze scaling regimes and derive explicit analytic solutions for gradient flow (GF) in large learning problems. Our key innovation is a formal power series expansion of the loss evolution, with coefficients encoded by diagrams akin to Feynman diagrams. We show that this expansion has a well-defined large-size limit that can be used to reveal different learning phases and, in some cases, to obtain explicit solutions of the nonlinear GF. We focus on learning Canonical Polyadic (CP) decompositions of high-order tensors, and show that this model has several distinct extreme lazy and rich GF regimes such as free evolution, NTK and under- and over-parameterized mean-field. We show that these regimes depend on the parameter scaling, tensor order, and symmetry of the model in a specific and subtle way. Moreover, we propose a general approach to summing the formal loss expansion by reducing it to a PDE; in a wide range of scenarios, it turns out to be 1st order and solvable by the method of characteristics. We observe a very good agreement of our theoretical predictions with experiment.
Corner Gradient Descent
Apr 16, 2025



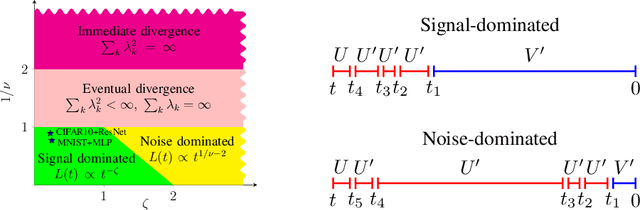
We consider SGD-type optimization on infinite-dimensional quadratic problems with power law spectral conditions. It is well-known that on such problems deterministic GD has loss convergence rates $L_t=O(t^{-\zeta})$, which can be improved to $L_t=O(t^{-2\zeta})$ by using Heavy Ball with a non-stationary Jacobi-based schedule (and the latter rate is optimal among fixed schedules). However, in the mini-batch Stochastic GD setting, the sampling noise causes the Jacobi HB to diverge; accordingly no $O(t^{-2\zeta})$ algorithm is known. In this paper we show that rates up to $O(t^{-2\zeta})$ can be achieved by a generalized stationary SGD with infinite memory. We start by identifying generalized (S)GD algorithms with contours in the complex plane. We then show that contours that have a corner with external angle $\theta\pi$ accelerate the plain GD rate $O(t^{-\zeta})$ to $O(t^{-\theta\zeta})$. For deterministic GD, increasing $\theta$ allows to achieve rates arbitrarily close to $O(t^{-2\zeta})$. However, in Stochastic GD, increasing $\theta$ also amplifies the sampling noise, so in general $\theta$ needs to be optimized by balancing the acceleration and noise effects. We prove that the optimal rate is given by $\theta_{\max}=\min(2,\nu,\tfrac{2}{\zeta+1/\nu})$, where $\nu,\zeta$ are the exponents appearing in the capacity and source spectral conditions. Furthermore, using fast rational approximations of the power functions, we show that ideal corner algorithms can be efficiently approximated by finite-memory algorithms, and demonstrate their practical efficiency on a synthetic problem and MNIST.
SGD with memory: fundamental properties and stochastic acceleration
Oct 05, 2024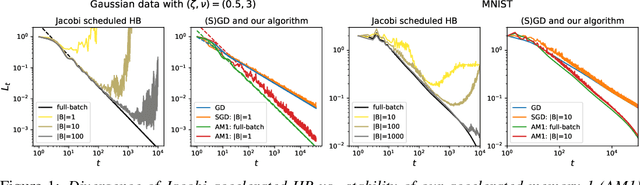
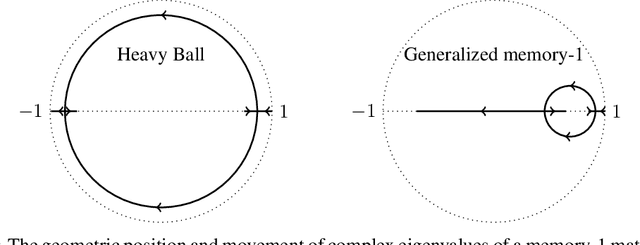
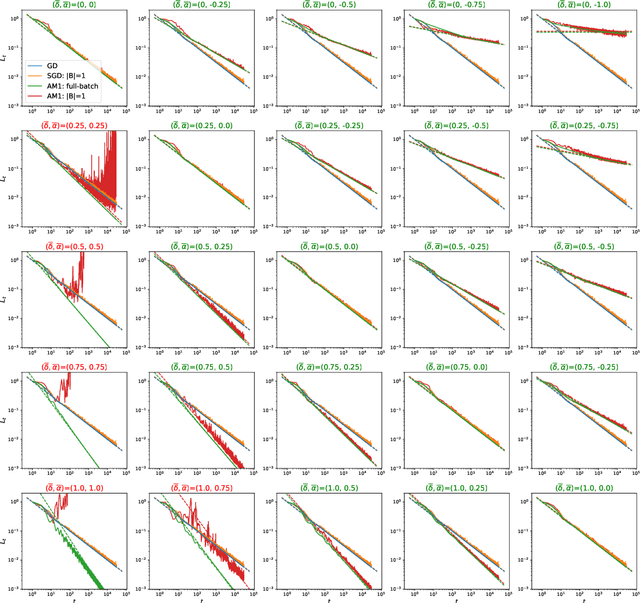
An important open problem is the theoretically feasible acceleration of mini-batch SGD-type algorithms on quadratic problems with power-law spectrum. In the non-stochastic setting, the optimal exponent $\xi$ in the loss convergence $L_t\sim C_Lt^{-\xi}$ is double that in plain GD and is achievable using Heavy Ball (HB) with a suitable schedule; this no longer works in the presence of mini-batch noise. We address this challenge by considering first-order methods with an arbitrary fixed number $M$ of auxiliary velocity vectors (*memory-$M$ algorithms*). We first prove an equivalence between two forms of such algorithms and describe them in terms of suitable characteristic polynomials. Then we develop a general expansion of the loss in terms of signal and noise propagators. Using it, we show that losses of stationary stable memory-$M$ algorithms always retain the exponent $\xi$ of plain GD, but can have different constants $C_L$ depending on their effective learning rate that generalizes that of HB. We prove that in memory-1 algorithms we can make $C_L$ arbitrarily small while maintaining stability. As a consequence, we propose a memory-1 algorithm with a time-dependent schedule that we show heuristically and experimentally to improve the exponent $\xi$ of plain SGD.
Generalization error of spectral algorithms
Mar 18, 2024
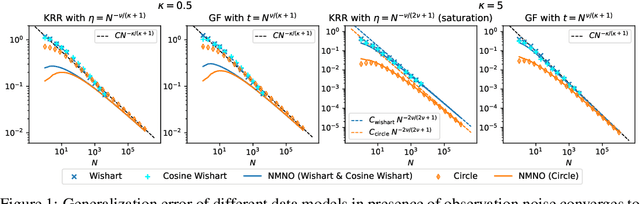
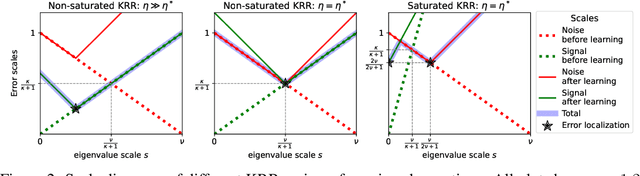
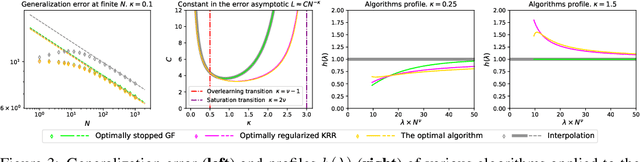
The asymptotically precise estimation of the generalization of kernel methods has recently received attention due to the parallels between neural networks and their associated kernels. However, prior works derive such estimates for training by kernel ridge regression (KRR), whereas neural networks are typically trained with gradient descent (GD). In the present work, we consider the training of kernels with a family of $\textit{spectral algorithms}$ specified by profile $h(\lambda)$, and including KRR and GD as special cases. Then, we derive the generalization error as a functional of learning profile $h(\lambda)$ for two data models: high-dimensional Gaussian and low-dimensional translation-invariant model. Under power-law assumptions on the spectrum of the kernel and target, we use our framework to (i) give full loss asymptotics for both noisy and noiseless observations (ii) show that the loss localizes on certain spectral scales, giving a new perspective on the KRR saturation phenomenon (iii) conjecture, and demonstrate for the considered data models, the universality of the loss w.r.t. non-spectral details of the problem, but only in case of noisy observation.
Learning high-dimensional targets by two-parameter models and gradient flow
Feb 26, 2024


We explore the theoretical possibility of learning $d$-dimensional targets with $W$-parameter models by gradient flow (GF) when $W<d$. Our main result shows that if the targets are described by a particular $d$-dimensional probability distribution, then there exist models with as few as two parameters that can learn the targets with arbitrarily high success probability. On the other hand, we show that for $W<d$ there is necessarily a large subset of GF-non-learnable targets. In particular, the set of learnable targets is not dense in $\mathbb R^d$, and any subset of $\mathbb R^d$ homeomorphic to the $W$-dimensional sphere contains non-learnable targets. Finally, we observe that the model in our main theorem on almost guaranteed two-parameter learning is constructed using a hierarchical procedure and as a result is not expressible by a single elementary function. We show that this limitation is essential in the sense that such learnability can be ruled out for a large class of elementary functions.
Structure of universal formulas
Nov 07, 2023By universal formulas we understand parameterized analytic expressions that have a fixed complexity, but nevertheless can approximate any continuous function on a compact set. There exist various examples of such formulas, including some in the form of neural networks. In this paper we analyze the essential structural elements of these highly expressive models. We introduce a hierarchy of expressiveness classes connecting the global approximability property to the weaker property of infinite VC dimension, and prove a series of classification results for several increasingly complex functional families. In particular, we introduce a general family of polynomially-exponentially-algebraic functions that, as we prove, is subject to polynomial constraints. As a consequence, we show that fixed-size neural networks with not more than one layer of neurons having transcendental activations (e.g., sine or standard sigmoid) cannot in general approximate functions on arbitrary finite sets. On the other hand, we give examples of functional families, including two-hidden-layer neural networks, that approximate functions on arbitrary finite sets, but fail to do that on the whole domain of definition.
A view of mini-batch SGD via generating functions: conditions of convergence, phase transitions, benefit from negative momenta
Jun 22, 2022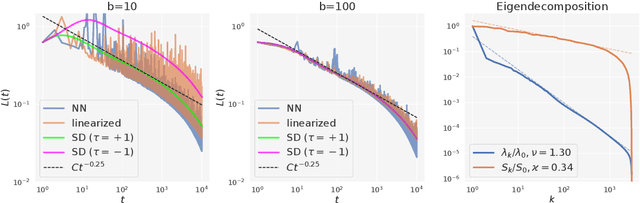
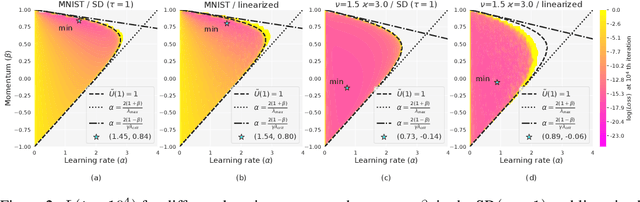
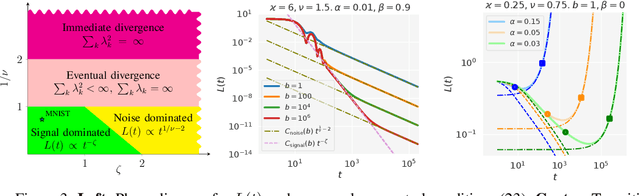

Mini-batch SGD with momentum is a fundamental algorithm for learning large predictive models. In this paper we develop a new analytic framework to analyze mini-batch SGD for linear models at different momenta and sizes of batches. Our key idea is to describe the loss value sequence in terms of its generating function, which can be written in a compact form assuming a diagonal approximation for the second moments of model weights. By analyzing this generating function, we deduce various conclusions on the convergence conditions, phase structure of the model, and optimal learning settings. As a few examples, we show that 1) the optimization trajectory can generally switch from the "signal-dominated" to the "noise-dominated" phase, at a time scale that can be predicted analytically; 2) in the "signal-dominated" (but not the "noise-dominated") phase it is favorable to choose a large effective learning rate, however its value must be limited for any finite batch size to avoid divergence; 3) optimal convergence rate can be achieved at a negative momentum. We verify our theoretical predictions by extensive experiments with MNIST and synthetic problems, and find a good quantitative agreement.
Embedded Ensembles: Infinite Width Limit and Operating Regimes
Feb 24, 2022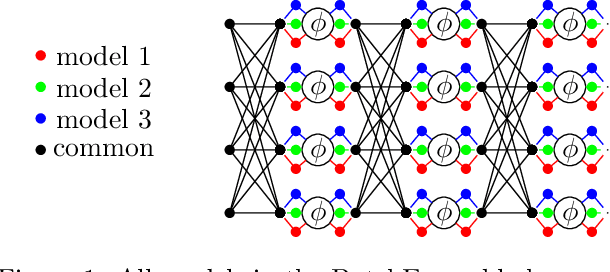
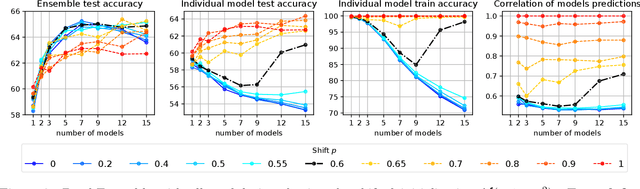
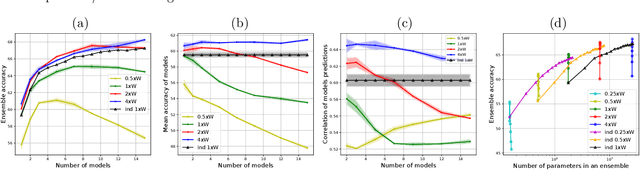
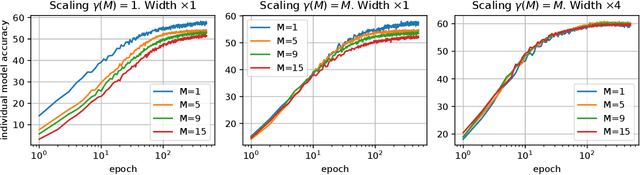
A memory efficient approach to ensembling neural networks is to share most weights among the ensembled models by means of a single reference network. We refer to this strategy as Embedded Ensembling (EE); its particular examples are BatchEnsembles and Monte-Carlo dropout ensembles. In this paper we perform a systematic theoretical and empirical analysis of embedded ensembles with different number of models. Theoretically, we use a Neural-Tangent-Kernel-based approach to derive the wide network limit of the gradient descent dynamics. In this limit, we identify two ensemble regimes - independent and collective - depending on the architecture and initialization strategy of ensemble models. We prove that in the independent regime the embedded ensemble behaves as an ensemble of independent models. We confirm our theoretical prediction with a wide range of experiments with finite networks, and further study empirically various effects such as transition between the two regimes, scaling of ensemble performance with the network width and number of models, and dependence of performance on a number of architecture and hyperparameter choices.
Tight Convergence Rate Bounds for Optimization Under Power Law Spectral Conditions
Feb 02, 2022



Performance of optimization on quadratic problems sensitively depends on the low-lying part of the spectrum. For large (effectively infinite-dimensional) problems, this part of the spectrum can often be naturally represented or approximated by power law distributions. In this paper we perform a systematic study of a range of classical single-step and multi-step first order optimization algorithms, with adaptive and non-adaptive, constant and non-constant learning rates: vanilla Gradient Descent, Steepest Descent, Heavy Ball, and Conjugate Gradients. For each of these, we prove that a power law spectral assumption entails a power law for convergence rate of the algorithm, with the convergence rate exponent given by a specific multiple of the spectral exponent. We establish both upper and lower bounds, showing that the results are tight. Finally, we demonstrate applications of these results to kernel learning and training of neural networks in the NTK regime.