 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleFace: Uncertainty-aware Deep Metric Learning
Sep 12, 2022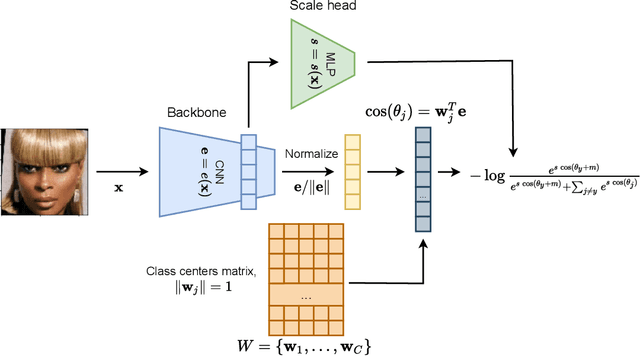
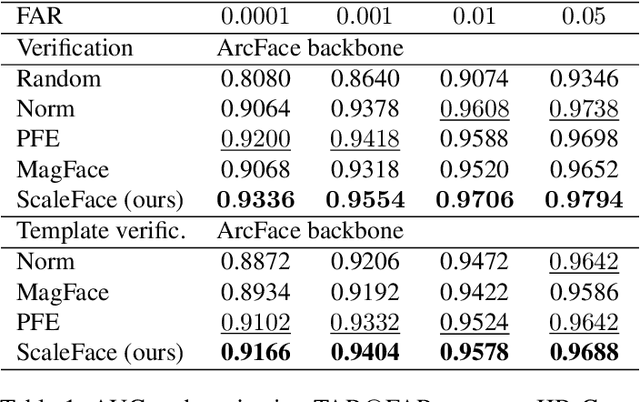

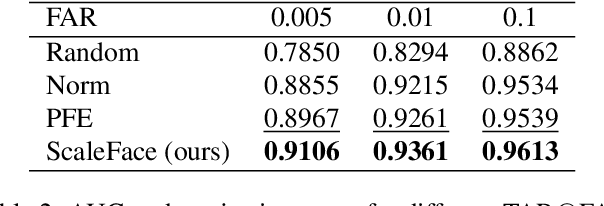
The performance of modern deep learning-based systems dramatically depends on the quality of input objects. For example, face recognition quality would be lower for blurry or corrupted inputs. However, it is hard to predict the influence of input quality on the resulting accuracy in more complex scenarios. We propose an approach for deep metric learning that allows direct estimation of the uncertainty with almost no additional computational cost. The developed \textit{ScaleFace} algorithm uses trainable scale values that modify similarities in the space of embeddings. These input-dependent scale values represent a measure of confidence in the recognition result, thus allowing uncertainty estimation. We provide comprehensive experiments on face recognition tasks that show the superior performance of ScaleFace compared to other uncertainty-aware face recognition approaches. We also extend the results to the task of text-to-image retrieval showing that the proposed approach beats the competitors with significant margin.
Embedded Ensembles: Infinite Width Limit and Operating Regimes
Feb 24, 2022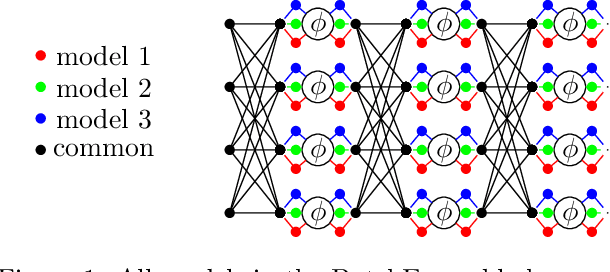
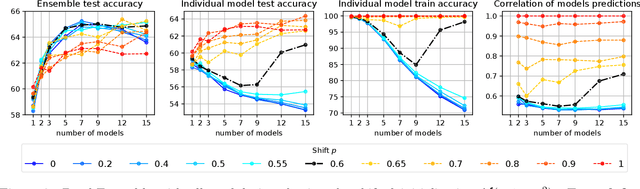
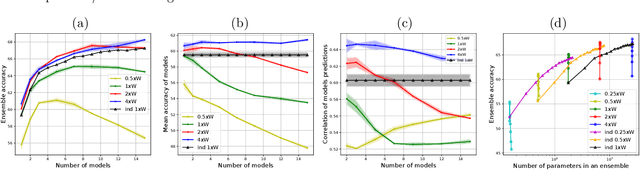
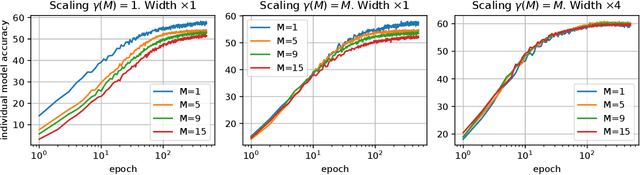
A memory efficient approach to ensembling neural networks is to share most weights among the ensembled models by means of a single reference network. We refer to this strategy as Embedded Ensembling (EE); its particular examples are BatchEnsembles and Monte-Carlo dropout ensembles. In this paper we perform a systematic theoretical and empirical analysis of embedded ensembles with different number of models. Theoretically, we use a Neural-Tangent-Kernel-based approach to derive the wide network limit of the gradient descent dynamics. In this limit, we identify two ensemble regimes - independent and collective - depending on the architecture and initialization strategy of ensemble models. We prove that in the independent regime the embedded ensemble behaves as an ensemble of independent models. We confirm our theoretical prediction with a wide range of experiments with finite networks, and further study empirically various effects such as transition between the two regimes, scaling of ensemble performance with the network width and number of models, and dependence of performance on a number of architecture and hyperparameter choices.
Recurrent Convolutional Neural Networks help to predict location of Earthquakes
May 21, 2020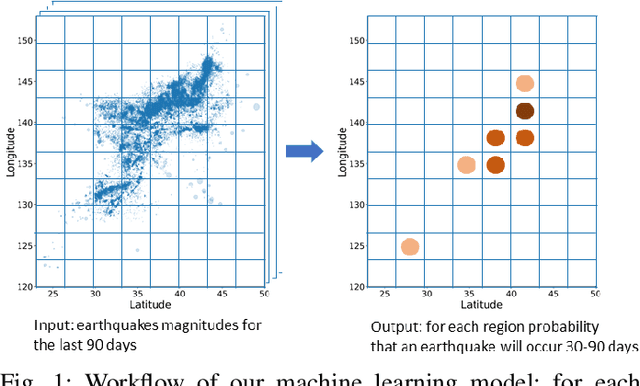
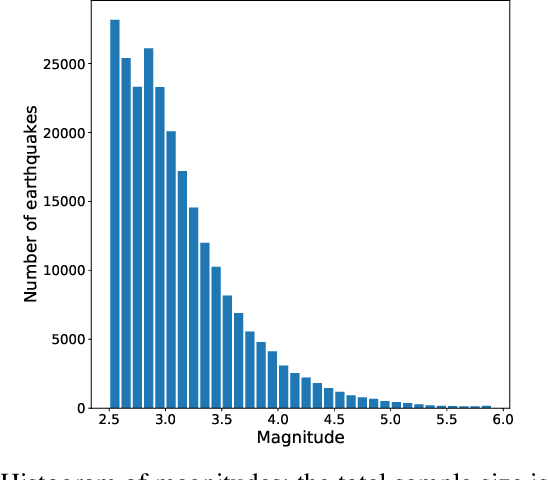
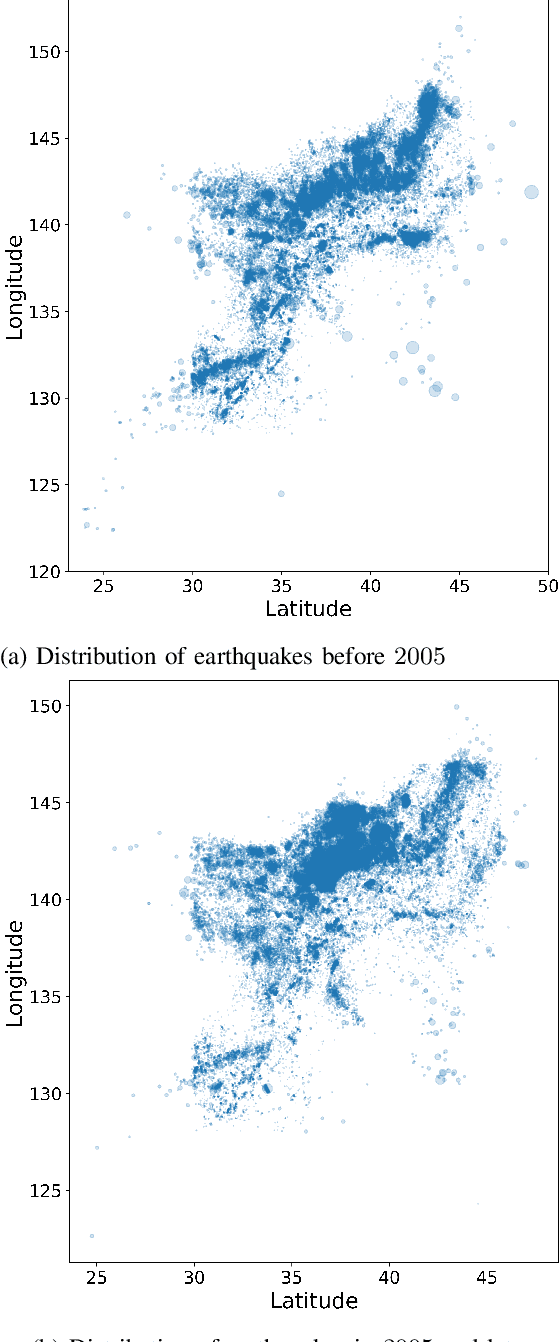
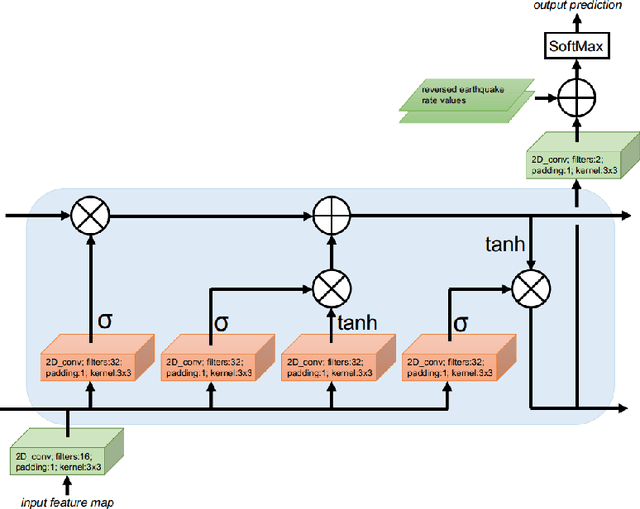
We examine the applicability of modern neural network architectures to the midterm prediction of earthquakes. Our data-based classification model aims to predict if an earthquake with the magnitude above a threshold takes place at a given area of size $10 \times 10$ kilometers in $30$-$180$ days from a given moment. Our deep neural network model has a recurrent part (LSTM) that accounts for time dependencies between earthquakes and a convolutional part that accounts for spatial dependencies. Obtained results show that neural networks-based models beat baseline feature-based models that also account for spatio-temporal dependencies between different earthquakes. For historical data on Japan earthquakes $1990$-$2016$ our best model predicts earthquakes with magnitude $M_c > 5$ with quality metrics ROC AUC $0.975$ and PR AUC $0.0890$, making $1.18 \cdot 10^3$ correct predictions, while missing $2.09 \cdot 10^3$ earthquakes and making $192 \cdot 10^3$ false alarms. The baseline approach has similar ROC AUC $0.992$, the number of correct predictions $1.19 \cdot 10^3$, and missing $2.07 \cdot 10^3$ earthquakes, but significantly worse PR AUC $0.00911$, and the number of false alarms $1004 \cdot 10^3$.