 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKonstruktor: A Strong Baseline for Simple Knowledge Graph Question Answering
Sep 24, 2024While being one of the most popular question types, simple questions such as "Who is the author of Cinderella?", are still not completely solved. Surprisingly, even the most powerful modern Large Language Models are prone to errors when dealing with such questions, especially when dealing with rare entities. At the same time, as an answer may be one hop away from the question entity, one can try to develop a method that uses structured knowledge graphs (KGs) to answer such questions. In this paper, we introduce Konstruktor - an efficient and robust approach that breaks down the problem into three steps: (i) entity extraction and entity linking, (ii) relation prediction, and (iii) querying the knowledge graph. Our approach integrates language models and knowledge graphs, exploiting the power of the former and the interpretability of the latter. We experiment with two named entity recognition and entity linking methods and several relation detection techniques. We show that for relation detection, the most challenging step of the workflow, a combination of relation classification/generation and ranking outperforms other methods. We report Konstruktor's strong results on four datasets.
* 18 pages, 2 figures, 7 tables
Answer Candidate Type Selection: Text-to-Text Language Model for Closed Book Question Answering Meets Knowledge Graphs
Oct 10, 2023Pre-trained Text-to-Text Language Models (LMs), such as T5 or BART yield promising results in the Knowledge Graph Question Answering (KGQA) task. However, the capacity of the models is limited and the quality decreases for questions with less popular entities. In this paper, we present a novel approach which works on top of the pre-trained Text-to-Text QA system to address this issue. Our simple yet effective method performs filtering and re-ranking of generated candidates based on their types derived from Wikidata "instance_of" property.
Error syntax aware augmentation of feedback comment generation dataset
Dec 29, 2022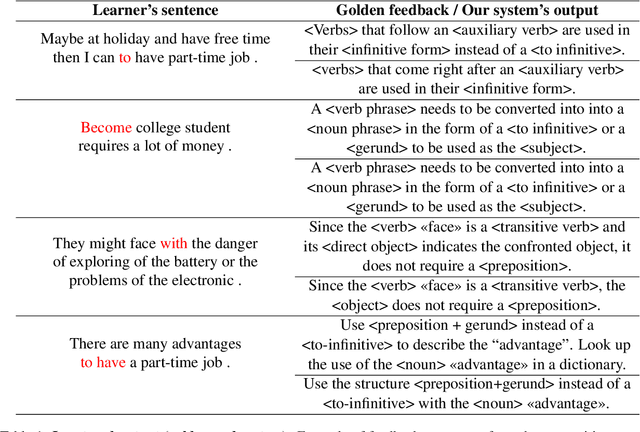
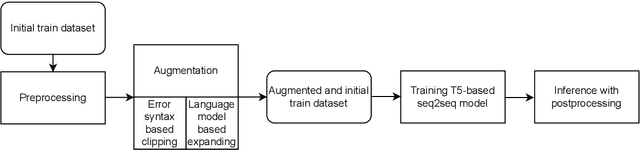

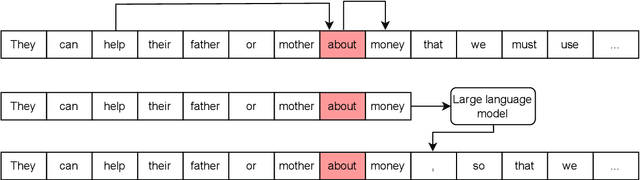
This paper presents a solution to the GenChal 2022 shared task dedicated to feedback comment generation for writing learning. In terms of this task given a text with an error and a span of the error, a system generates an explanatory note that helps the writer (language learner) to improve their writing skills. Our solution is based on fine-tuning the T5 model on the initial dataset augmented according to syntactical dependencies of the words located within indicated error span. The solution of our team "nigula" obtained second place according to manual evaluation by the organizers.
Tensor-based Collaborative Filtering With Smooth Ratings Scale
May 10, 2022
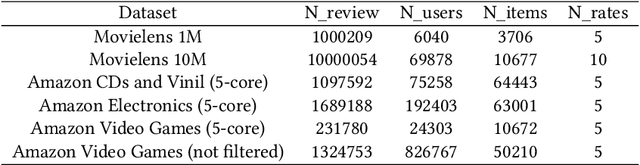
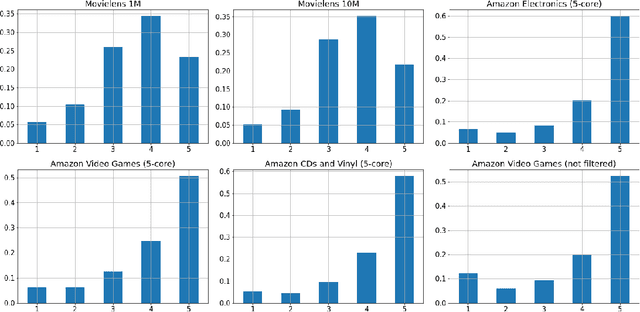
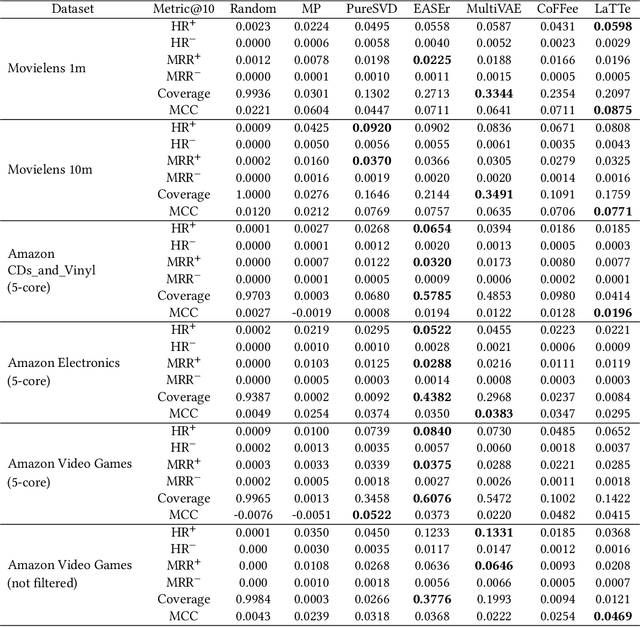
Conventional collaborative filtering techniques don't take into consideration the effect of discrepancy in users' rating perception. Some users may rarely give 5 stars to items while others almost always assign 5 stars to the chosen item. Even if they had experience with the same items this systematic discrepancy in their evaluation style will lead to the systematic errors in the ability of recommender system to effectively extract right patterns from data. To mitigate this problem we introduce the ratings' similarity matrix which represents the dependency between different values of ratings on the population level. Hence, if on average the correlations between ratings exist, it is possible to improve the quality of proposed recommendations by off-setting the effect of either shifted down or shifted up users' rates.