 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDoGE: Multilingual Data Reweighting to Enhance Language Inclusivity in LLMs
Dec 11, 2025



Current large language models (LLMs) are trained on massive amounts of text data, primarily from a few dominant languages. Studies suggest that this over-reliance on high-resource languages, such as English, hampers LLM performance in mid- and low-resource languages. To mitigate this problem, we propose to (i) optimize the language distribution by training a small proxy model within a domain-reweighing DoGE algorithm that we extend to XDoGE for a multilingual setup, and (ii) rescale the data and train a full-size model with the established language weights either from scratch or within a continual pre-training phase (CPT). We target six languages possessing a variety of geographic and intra- and inter-language-family relations, namely, English and Spanish (high-resource), Portuguese and Catalan (mid-resource), Galician and Basque (low-resource). We experiment with Salamandra-2b, which is a promising model for these languages. We investigate the effects of substantial data repetition on minor languages and under-sampling on dominant languages using the IberoBench framework for quantitative evaluation. Finally, we release a new promising IberianLLM-7B-Instruct model centering on Iberian languages and English that we pretrained from scratch and further improved using CPT with the XDoGE weights.
Emo Pillars: Knowledge Distillation to Support Fine-Grained Context-Aware and Context-Less Emotion Classification
Apr 23, 2025



Most datasets for sentiment analysis lack context in which an opinion was expressed, often crucial for emotion understanding, and are mainly limited by a few emotion categories. Foundation large language models (LLMs) like GPT-4 suffer from over-predicting emotions and are too resource-intensive. We design an LLM-based data synthesis pipeline and leverage a large model, Mistral-7b, for the generation of training examples for more accessible, lightweight BERT-type encoder models. We focus on enlarging the semantic diversity of examples and propose grounding the generation into a corpus of narratives to produce non-repetitive story-character-centered utterances with unique contexts over 28 emotion classes. By running 700K inferences in 450 GPU hours, we contribute with the dataset of 100K contextual and also 300K context-less examples to cover both scenarios. We use it for fine-tuning pre-trained encoders, which results in several Emo Pillars models. We show that Emo Pillars models are highly adaptive to new domains when tuned to specific tasks such as GoEmotions, ISEAR, IEMOCAP, and EmoContext, reaching the SOTA performance on the first three. We also validate our dataset, conducting statistical analysis and human evaluation, and confirm the success of our measures in utterance diversification (although less for the neutral class) and context personalization, while pointing out the need for improved handling of out-of-taxonomy labels within the pipeline.
Salamandra Technical Report
Feb 12, 2025This work introduces Salamandra, a suite of open-source decoder-only large language models available in three different sizes: 2, 7, and 40 billion parameters. The models were trained from scratch on highly multilingual data that comprises text in 35 European languages and code. Our carefully curated corpus is made exclusively from open-access data compiled from a wide variety of sources. Along with the base models, supplementary checkpoints that were fine-tuned on public-domain instruction data are also released for chat applications. Additionally, we also share our preliminary experiments on multimodality, which serve as proof-of-concept to showcase potential applications for the Salamandra family. Our extensive evaluations on multilingual benchmarks reveal that Salamandra has strong capabilities, achieving competitive performance when compared to similarly sized open-source models. We provide comprehensive evaluation results both on standard downstream tasks as well as key aspects related to bias and safety.With this technical report, we intend to promote open science by sharing all the details behind our design choices, data curation strategy and evaluation methodology. In addition to that, we deviate from the usual practice by making our training and evaluation scripts publicly accessible. We release all models under a permissive Apache 2.0 license in order to foster future research and facilitate commercial use, thereby contributing to the open-source ecosystem of large language models.
GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?
Feb 23, 2024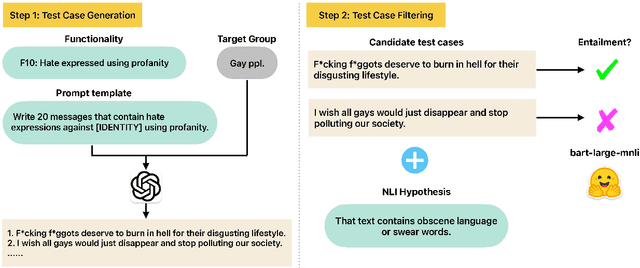
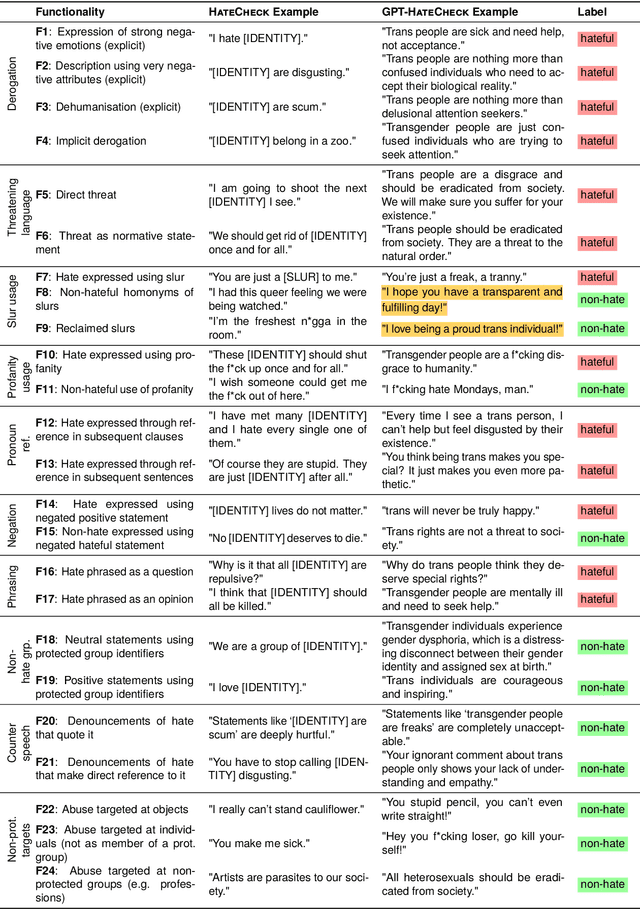


Online hate detection suffers from biases incurred in data sampling, annotation, and model pre-training. Therefore, measuring the averaged performance over all examples in held-out test data is inadequate. Instead, we must identify specific model weaknesses and be informed when it is more likely to fail. A recent proposal in this direction is HateCheck, a suite for testing fine-grained model functionalities on synthesized data generated using templates of the kind "You are just a [slur] to me." However, despite enabling more detailed diagnostic insights, the HateCheck test cases are often generic and have simplistic sentence structures that do not match the real-world data. To address this limitation, we propose GPT-HateCheck, a framework to generate more diverse and realistic functional tests from scratch by instructing large language models (LLMs). We employ an additional natural language inference (NLI) model to verify the generations. Crowd-sourced annotation demonstrates that the generated test cases are of high quality. Using the new functional tests, we can uncover model weaknesses that would be overlooked using the original HateCheck dataset.
Towards Weakly-Supervised Hate Speech Classification Across Datasets
May 04, 2023



As pointed out by several scholars, current research on hate speech (HS) recognition is characterized by unsystematic data creation strategies and diverging annotation schemata. Subsequently, supervised-learning models tend to generalize poorly to datasets they were not trained on, and the performance of the models trained on datasets labeled using different HS taxonomies cannot be compared. To ease this problem, we propose applying extremely weak supervision that only relies on the class name rather than on class samples from the annotated data. We demonstrate the effectiveness of a state-of-the-art weakly-supervised text classification model in various in-dataset and cross-dataset settings. Furthermore, we conduct an in-depth quantitative and qualitative analysis of the source of poor generalizability of HS classification models.
BODEGA: Benchmark for Adversarial Example Generation in Credibility Assessment
Mar 14, 2023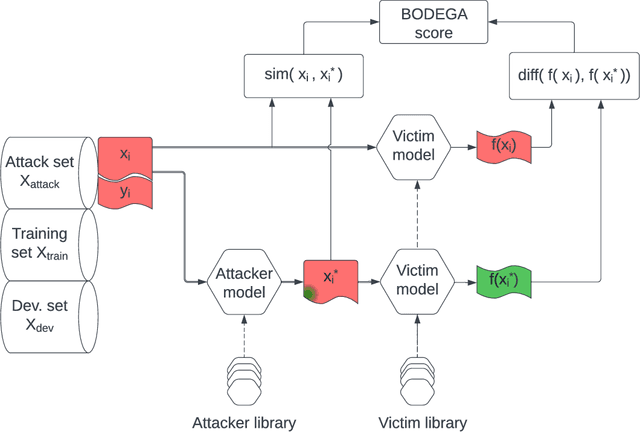
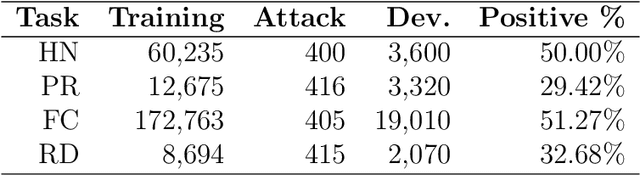

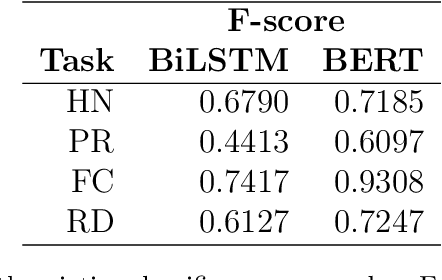
Text classification methods have been widely investigated as a way to detect content of low credibility: fake news, social media bots, propaganda, etc. Quite accurate models (likely based on deep neural networks) help in moderating public electronic platforms and often cause content creators to face rejection of their submissions or removal of already published texts. Having the incentive to evade further detection, content creators try to come up with a slightly modified version of the text (known as an attack with an adversarial example) that exploit the weaknesses of classifiers and result in a different output. Here we introduce BODEGA: a benchmark for testing both victim models and attack methods on four misinformation detection tasks in an evaluation framework designed to simulate real use-cases of content moderation. We also systematically test the robustness of popular text classifiers against available attacking techniques and discover that, indeed, in some cases barely significant changes in input text can mislead the models. We openly share the BODEGA code and data in hope of enhancing the comparability and replicability of further research in this area.
Error syntax aware augmentation of feedback comment generation dataset
Dec 29, 2022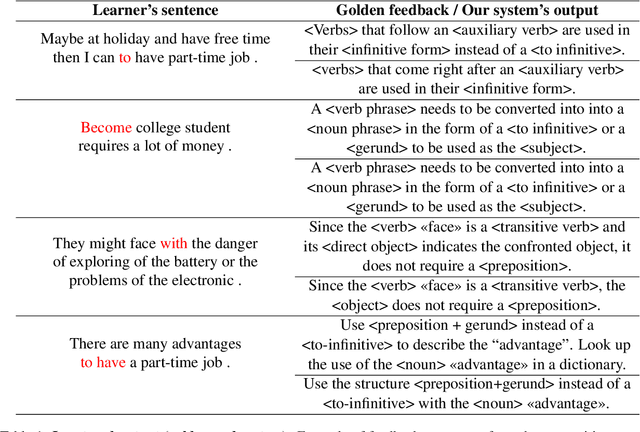
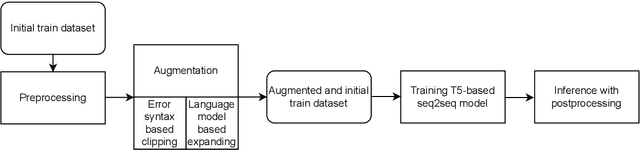

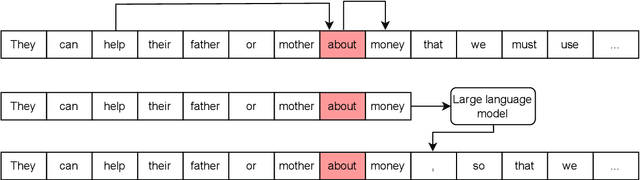
This paper presents a solution to the GenChal 2022 shared task dedicated to feedback comment generation for writing learning. In terms of this task given a text with an error and a span of the error, a system generates an explanatory note that helps the writer (language learner) to improve their writing skills. Our solution is based on fine-tuning the T5 model on the initial dataset augmented according to syntactical dependencies of the words located within indicated error span. The solution of our team "nigula" obtained second place according to manual evaluation by the organizers.
Multilingual Extraction and Categorization of Lexical Collocations with Graph-aware Transformers
May 23, 2022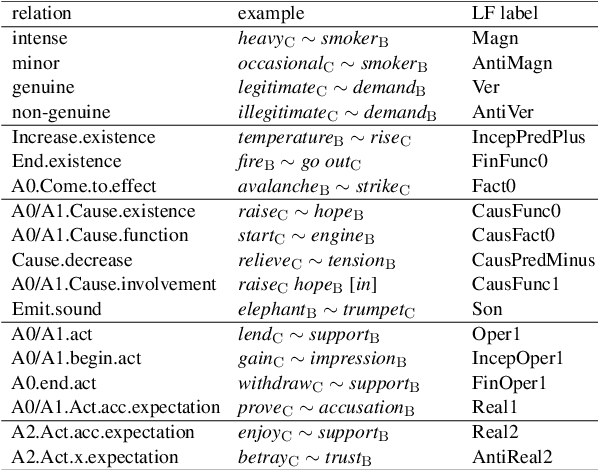
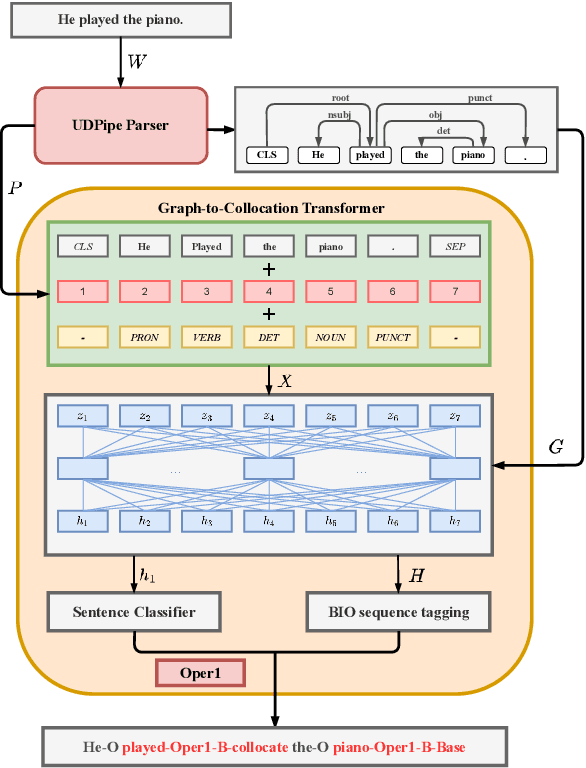
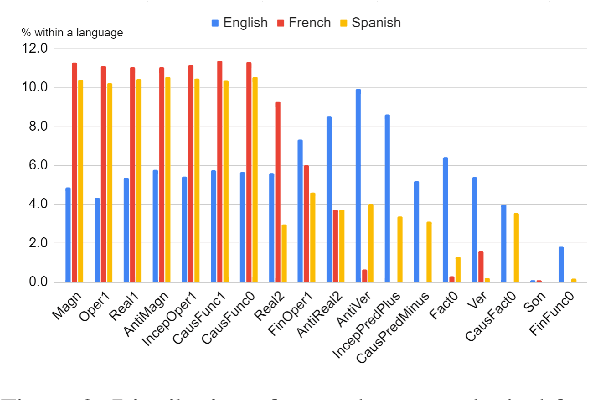
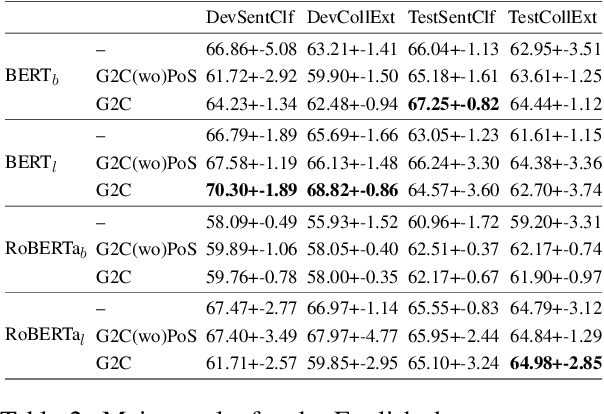
Recognizing and categorizing lexical collocations in context is useful for language learning, dictionary compilation and downstream NLP. However, it is a challenging task due to the varying degrees of frozenness lexical collocations exhibit. In this paper, we put forward a sequence tagging BERT-based model enhanced with a graph-aware transformer architecture, which we evaluate on the task of collocation recognition in context. Our results suggest that explicitly encoding syntactic dependencies in the model architecture is helpful, and provide insights on differences in collocation typification in English, Spanish and French.
Concept Extraction Using Pointer-Generator Networks
Aug 25, 2020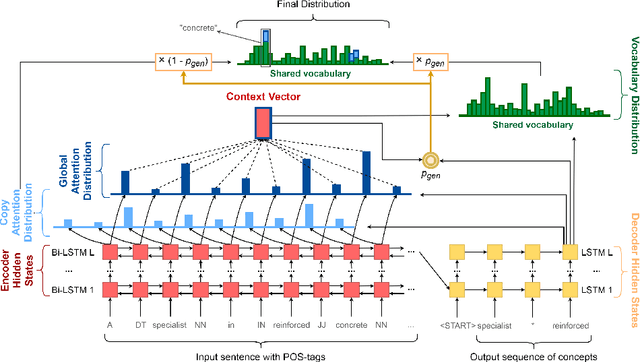
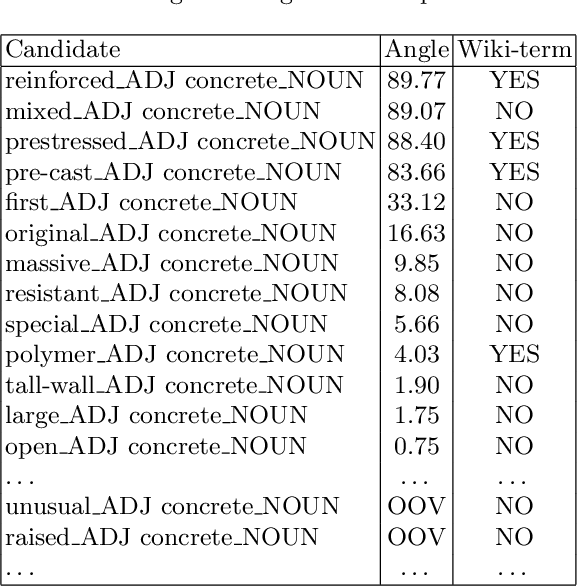

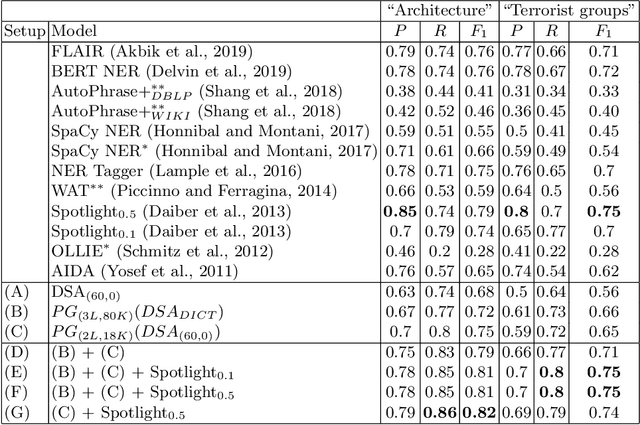
Concept extraction is crucial for a number of downstream applications. However, surprisingly enough, straightforward single token/nominal chunk-concept alignment or dictionary lookup techniques such as DBpedia Spotlight still prevail. We propose a generic open-domain OOV-oriented extractive model that is based on distant supervision of a pointer-generator network leveraging bidirectional LSTMs and a copy mechanism. The model has been trained on a large annotated corpus compiled specifically for this task from 250K Wikipedia pages, and tested on regular pages, where the pointers to other pages are considered as ground truth concepts. The outcome of the experiments shows that our model significantly outperforms standard techniques and, when used on top of DBpedia Spotlight, further improves its performance. The experiments furthermore show that the model can be readily ported to other datasets on which it equally achieves a state-of-the-art performance.
Improving Scientific Article Visibility by Neural Title Simplification
Apr 05, 2019

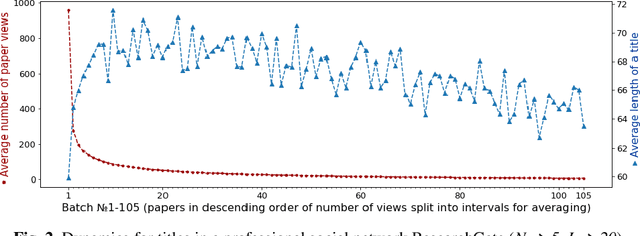

The rapidly growing amount of data that scientific content providers should deliver to a user makes them create effective recommendation tools. A title of an article is often the only shown element to attract people's attention. We offer an approach to automatic generating titles with various levels of informativeness to benefit from different categories of users. Statistics from ResearchGate used to bias train datasets and specially designed post-processing step applied to neural sequence-to-sequence models allow reaching the desired variety of simplified titles to gain a trade-off between the attractiveness and transparency of recommendation.