 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Extraction Using Pointer-Generator Networks
Paper and Code
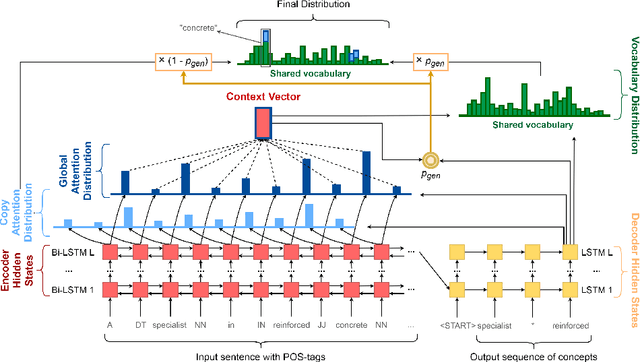
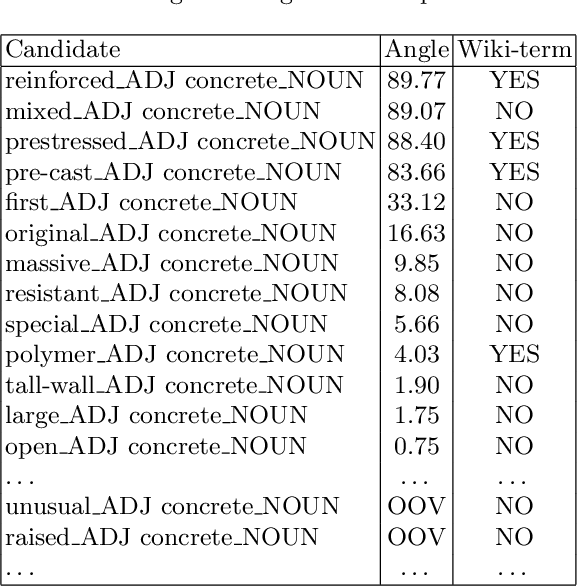

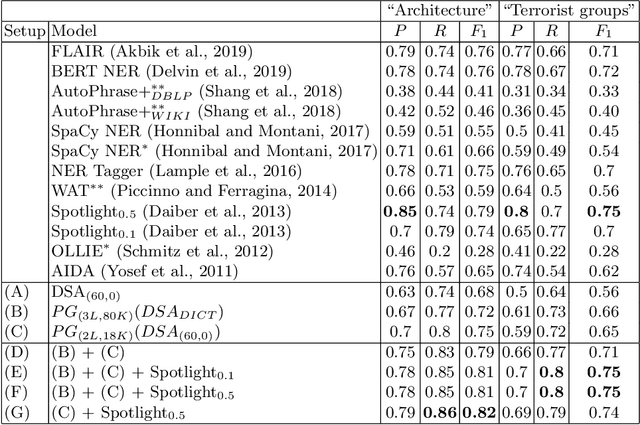
Concept extraction is crucial for a number of downstream applications. However, surprisingly enough, straightforward single token/nominal chunk-concept alignment or dictionary lookup techniques such as DBpedia Spotlight still prevail. We propose a generic open-domain OOV-oriented extractive model that is based on distant supervision of a pointer-generator network leveraging bidirectional LSTMs and a copy mechanism. The model has been trained on a large annotated corpus compiled specifically for this task from 250K Wikipedia pages, and tested on regular pages, where the pointers to other pages are considered as ground truth concepts. The outcome of the experiments shows that our model significantly outperforms standard techniques and, when used on top of DBpedia Spotlight, further improves its performance. The experiments furthermore show that the model can be readily ported to other datasets on which it equally achieves a state-of-the-art performance.