 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Hate Across Target Identities
Oct 14, 2024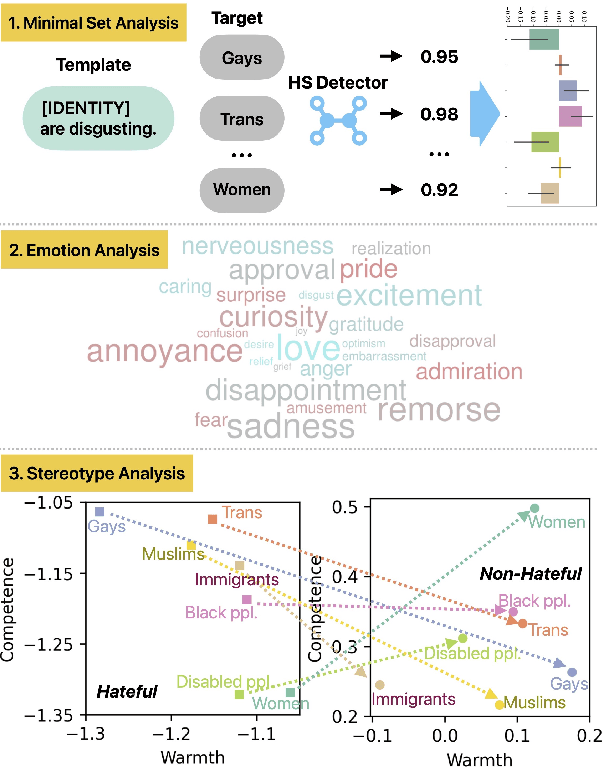
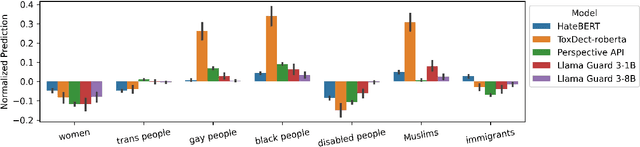
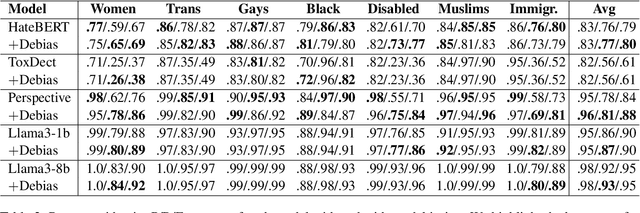
Hate speech (HS) classifiers do not perform equally well in detecting hateful expressions towards different target identities. They also demonstrate systematic biases in predicted hatefulness scores. Tapping on two recently proposed functionality test datasets for HS detection, we quantitatively analyze the impact of different factors on HS prediction. Experiments on popular industrial and academic models demonstrate that HS detectors assign a higher hatefulness score merely based on the mention of specific target identities. Besides, models often confuse hatefulness and the polarity of emotions. This result is worrisome as the effort to build HS detectors might harm the vulnerable identity groups we wish to protect: posts expressing anger or disapproval of hate expressions might be flagged as hateful themselves. We also carry out a study inspired by social psychology theory, which reveals that the accuracy of hatefulness prediction correlates strongly with the intensity of the stereotype.
ARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation
May 20, 2024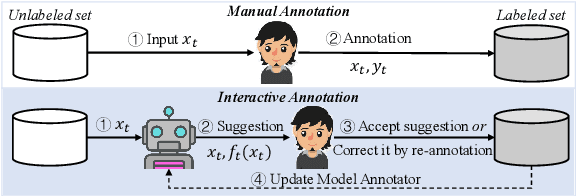
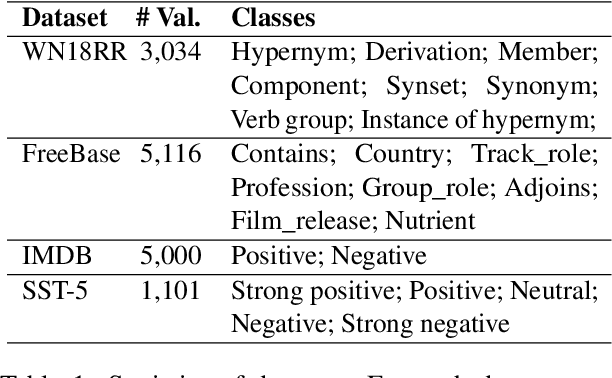
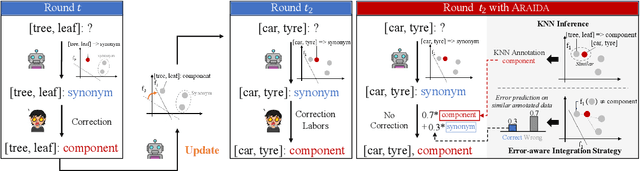
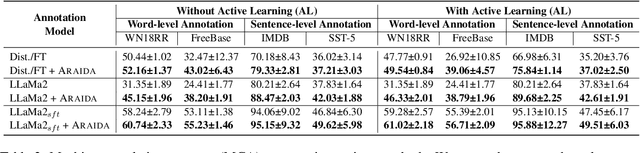
Human annotation is a time-consuming task that requires a significant amount of effort. To address this issue, interactive data annotation utilizes an annotation model to provide suggestions for humans to approve or correct. However, annotation models trained with limited labeled data are prone to generating incorrect suggestions, leading to extra human correction effort. To tackle this challenge, we propose Araida, an analogical reasoning-based approach that enhances automatic annotation accuracy in the interactive data annotation setting and reduces the need for human corrections. Araida involves an error-aware integration strategy that dynamically coordinates an annotation model and a k-nearest neighbors (KNN) model, giving more importance to KNN's predictions when predictions from the annotation model are deemed inaccurate. Empirical studies demonstrate that Araida is adaptable to different annotation tasks and models. On average, it reduces human correction labor by 11.02% compared to vanilla interactive data annotation methods.
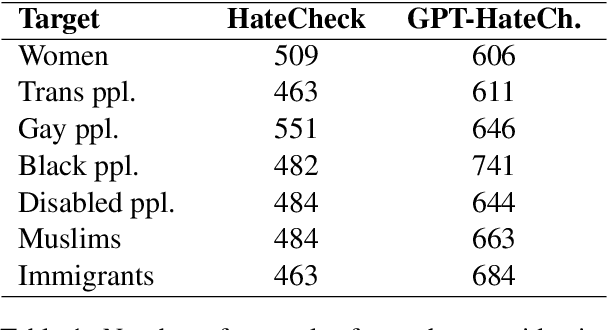
GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?
Feb 23, 2024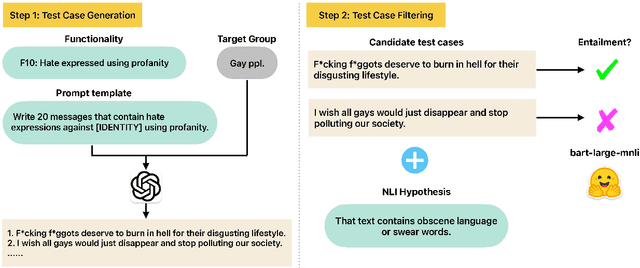
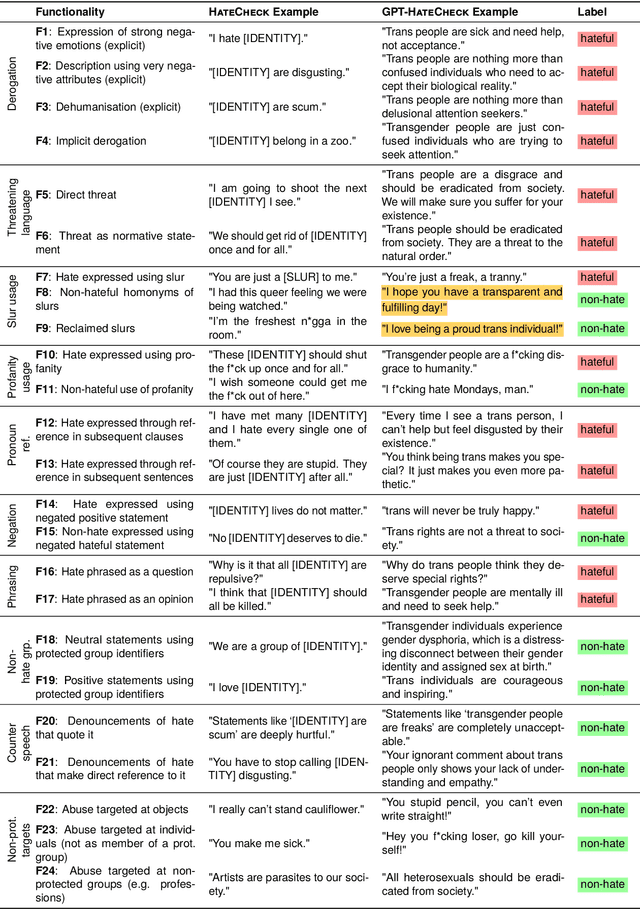


Online hate detection suffers from biases incurred in data sampling, annotation, and model pre-training. Therefore, measuring the averaged performance over all examples in held-out test data is inadequate. Instead, we must identify specific model weaknesses and be informed when it is more likely to fail. A recent proposal in this direction is HateCheck, a suite for testing fine-grained model functionalities on synthesized data generated using templates of the kind "You are just a [slur] to me." However, despite enabling more detailed diagnostic insights, the HateCheck test cases are often generic and have simplistic sentence structures that do not match the real-world data. To address this limitation, we propose GPT-HateCheck, a framework to generate more diverse and realistic functional tests from scratch by instructing large language models (LLMs). We employ an additional natural language inference (NLI) model to verify the generations. Crowd-sourced annotation demonstrates that the generated test cases are of high quality. Using the new functional tests, we can uncover model weaknesses that would be overlooked using the original HateCheck dataset.
Towards Weakly-Supervised Hate Speech Classification Across Datasets
May 04, 2023



As pointed out by several scholars, current research on hate speech (HS) recognition is characterized by unsystematic data creation strategies and diverging annotation schemata. Subsequently, supervised-learning models tend to generalize poorly to datasets they were not trained on, and the performance of the models trained on datasets labeled using different HS taxonomies cannot be compared. To ease this problem, we propose applying extremely weak supervision that only relies on the class name rather than on class samples from the annotated data. We demonstrate the effectiveness of a state-of-the-art weakly-supervised text classification model in various in-dataset and cross-dataset settings. Furthermore, we conduct an in-depth quantitative and qualitative analysis of the source of poor generalizability of HS classification models.
Plot Writing From Pre-Trained Language Models
Jun 07, 2022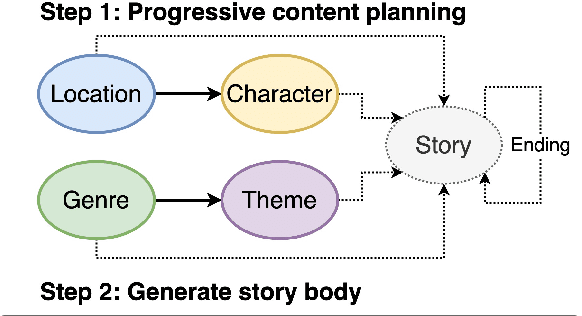



Pre-trained language models (PLMs) fail to generate long-form narrative text because they do not consider global structure. As a result, the generated texts are often incohesive, repetitive, or lack content. Recent work in story generation reintroduced explicit content planning in the form of prompts, keywords, or semantic frames. Trained on large parallel corpora, these models can generate more logical event sequences and thus more contentful stories. However, these intermediate representations are often not in natural language and cannot be utilized by PLMs without fine-tuning. We propose generating story plots using off-the-shelf PLMs while maintaining the benefit of content planning to generate cohesive and contentful stories. Our proposed method, ScratchPlot, first prompts a PLM to compose a content plan. Then, we generate the story's body and ending conditioned on the content plan. Furthermore, we take a generate-and-rank approach by using additional PLMs to rank the generated (story, ending) pairs. We benchmark our method with various baselines and achieved superior results in both human and automatic evaluation.
Seed Word Selection for Weakly-Supervised Text Classification with Unsupervised Error Estimation
Apr 20, 2021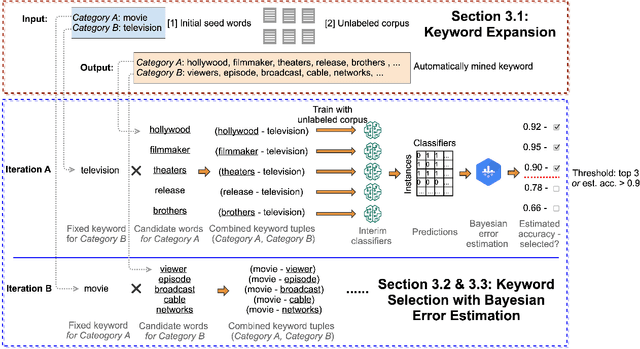

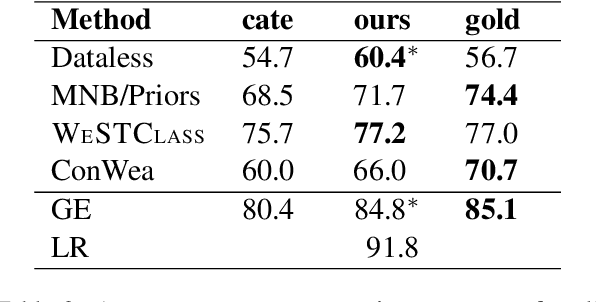
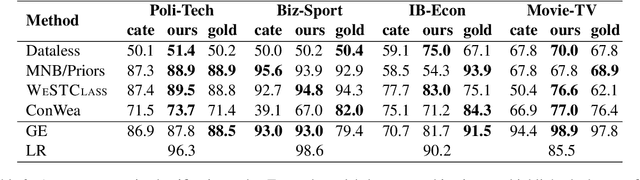
Weakly-supervised text classification aims to induce text classifiers from only a few user-provided seed words. The vast majority of previous work assumes high-quality seed words are given. However, the expert-annotated seed words are sometimes non-trivial to come up with. Furthermore, in the weakly-supervised learning setting, we do not have any labeled document to measure the seed words' efficacy, making the seed word selection process "a walk in the dark". In this work, we remove the need for expert-curated seed words by first mining (noisy) candidate seed words associated with the category names. We then train interim models with individual candidate seed words. Lastly, we estimate the interim models' error rate in an unsupervised manner. The seed words that yield the lowest estimated error rates are added to the final seed word set. A comprehensive evaluation of six binary classification tasks on four popular datasets demonstrates that the proposed method outperforms a baseline using only category name seed words and obtained comparable performance as a counterpart using expert-annotated seed words.
Bootstrapping Large-Scale Fine-Grained Contextual Advertising Classifier from Wikipedia
Feb 12, 2021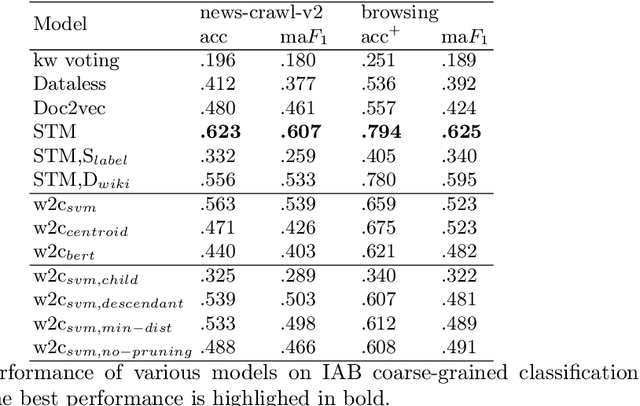
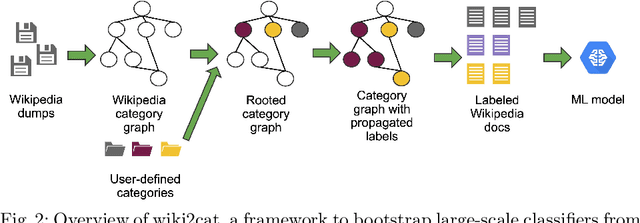
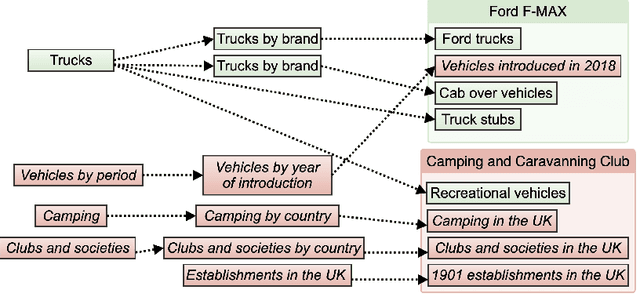
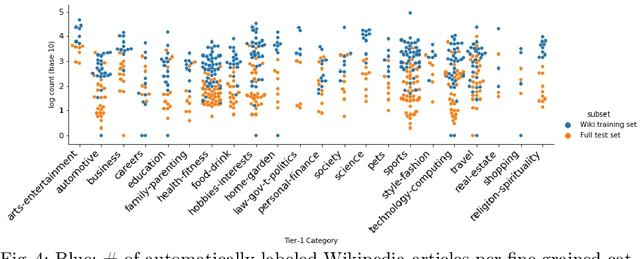
Contextual advertising provides advertisers with the opportunity to target the context which is most relevant to their ads. However, its power cannot be fully utilized unless we can target the page content using fine-grained categories, e.g., "coupe" vs. "hatchback" instead of "automotive" vs. "sport". The widely used advertising content taxonomy (IAB taxonomy) consists of 23 coarse-grained categories and 355 fine-grained categories. With the large number of categories, it becomes very challenging either to collect training documents to build a supervised classification model, or to compose expert-written rules in a rule-based classification system. Besides, in fine-grained classification, different categories often overlap or co-occur, making it harder to classify accurately. In this work, we propose wiki2cat, a method to tackle the problem of large-scaled fine-grained text classification by tapping on Wikipedia category graph. The categories in IAB taxonomy are first mapped to category nodes in the graph. Then the label is propagated across the graph to obtain a list of labeled Wikipedia documents to induce text classifiers. The method is ideal for large-scale classification problems since it does not require any manually-labeled document or hand-curated rules or keywords. The proposed method is benchmarked with various learning-based and keyword-based baselines and yields competitive performance on both publicly available datasets and a new dataset containing more than 300 fine-grained categories.
Generating Coherent and Diverse Slogans with Sequence-to-Sequence Transformer
Feb 11, 2021
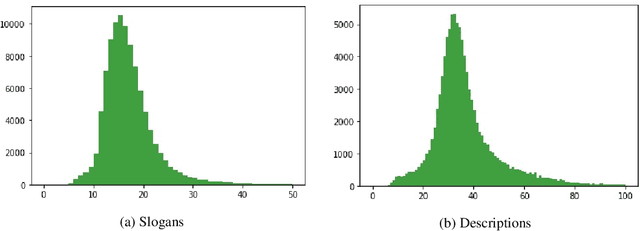

Previous work in slogan generation focused on generating novel slogans by utilising templates mined from real slogans. While some such slogans can be catchy, they are often not coherent with the company's focus or style across their marketing communications because the templates are mined from other companies' slogans. We propose a sequence-to-sequence transformer model to generate slogans from a brief company description. A naive sequence-to-sequence model fine-tuned for slogan generation is prone to introducing false information, especially unrelated company names appearing in the training data. We use delexicalisation to address this problem and improve the generated slogans' quality by a large margin. Furthermore, we apply two simple but effective approaches to generate more diverse slogans. Firstly, we train a slogan generator conditioned on the industry. During inference time, by changing the industry, we can obtain different "flavours" of slogans. Secondly, instead of using only the company description as the input sequence, we sample random paragraphs from the company's website. Surprisingly, the model can generate meaningful slogans, even if the input sequence does not resemble a company description. We validate the effectiveness of the proposed method with both quantitative evaluation and qualitative evaluation. Our best model achieved a ROUGE-1/-2/-L F1 score of 53.13/33.30/46.49. Besides, human evaluators assigned the generated slogans an average score of 3.39 on a scale of 1-5, indicating the system can generate plausible slogans with a quality close to human-written ones (average score 3.55).
Learning Only from Relevant Keywords and Unlabeled Documents
Oct 30, 2019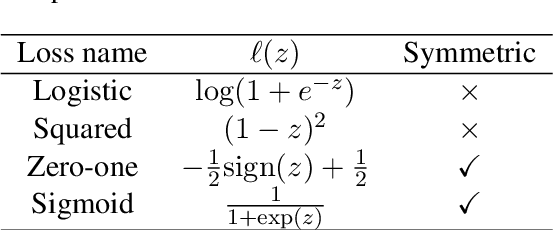
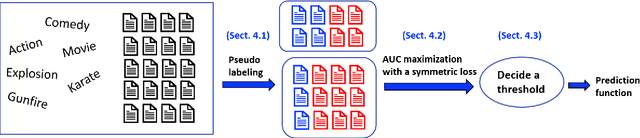


We consider a document classification problem where document labels are absent but only relevant keywords of a target class and unlabeled documents are given. Although heuristic methods based on pseudo-labeling have been considered, theoretical understanding of this problem has still been limited. Moreover, previous methods cannot easily incorporate well-developed techniques in supervised text classification. In this paper, we propose a theoretically guaranteed learning framework that is simple to implement and has flexible choices of models, e.g., linear models or neural networks. We demonstrate how to optimize the area under the receiver operating characteristic curve (AUC) effectively and also discuss how to adjust it to optimize other well-known evaluation metrics such as the accuracy and F1-measure. Finally, we show the effectiveness of our framework using benchmark datasets.