 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARAIDA: Analogical Reasoning-Augmented Interactive Data Annotation
May 20, 2024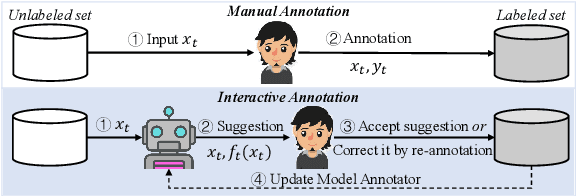
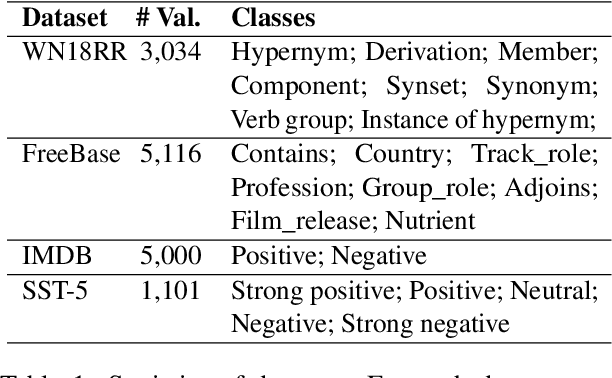
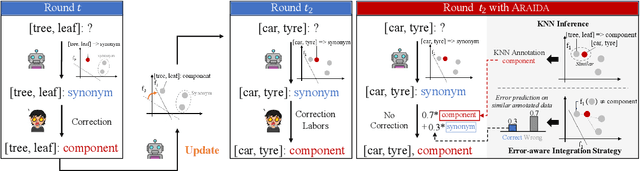
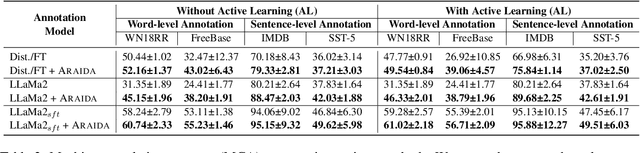
Human annotation is a time-consuming task that requires a significant amount of effort. To address this issue, interactive data annotation utilizes an annotation model to provide suggestions for humans to approve or correct. However, annotation models trained with limited labeled data are prone to generating incorrect suggestions, leading to extra human correction effort. To tackle this challenge, we propose Araida, an analogical reasoning-based approach that enhances automatic annotation accuracy in the interactive data annotation setting and reduces the need for human corrections. Araida involves an error-aware integration strategy that dynamically coordinates an annotation model and a k-nearest neighbors (KNN) model, giving more importance to KNN's predictions when predictions from the annotation model are deemed inaccurate. Empirical studies demonstrate that Araida is adaptable to different annotation tasks and models. On average, it reduces human correction labor by 11.02% compared to vanilla interactive data annotation methods.
Learning Active Subspaces and Discovering Important Features with Gaussian Radial Basis Functions Neural Networks
Jul 11, 2023


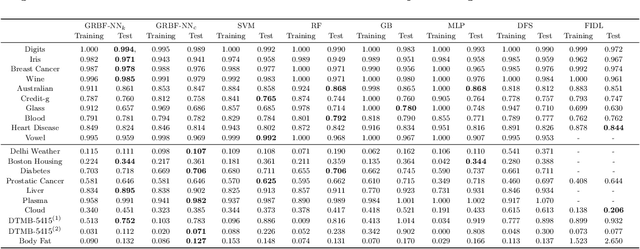
Providing a model that achieves a strong predictive performance and at the same time is interpretable by humans is one of the most difficult challenges in machine learning research due to the conflicting nature of these two objectives. To address this challenge, we propose a modification of the Radial Basis Function Neural Network model by equipping its Gaussian kernel with a learnable precision matrix. We show that precious information is contained in the spectrum of the precision matrix that can be extracted once the training of the model is completed. In particular, the eigenvectors explain the directions of maximum sensitivity of the model revealing the active subspace and suggesting potential applications for supervised dimensionality reduction. At the same time, the eigenvectors highlight the relationship in terms of absolute variation between the input and the latent variables, thereby allowing us to extract a ranking of the input variables based on their importance to the prediction task enhancing the model interpretability. We conducted numerical experiments for regression, classification, and feature selection tasks, comparing our model against popular machine learning models and the state-of-the-art deep learning-based embedding feature selection techniques. Our results demonstrate that the proposed model does not only yield an attractive prediction performance with respect to the competitors but also provides meaningful and interpretable results that potentially could assist the decision-making process in real-world applications. A PyTorch implementation of the model is available on GitHub at the following link. https://github.com/dannyzx/GRBF-NNs
WATTNet: Learning to Trade FX via Hierarchical Spatio-Temporal Representation of Highly Multivariate Time Series
Sep 24, 2019
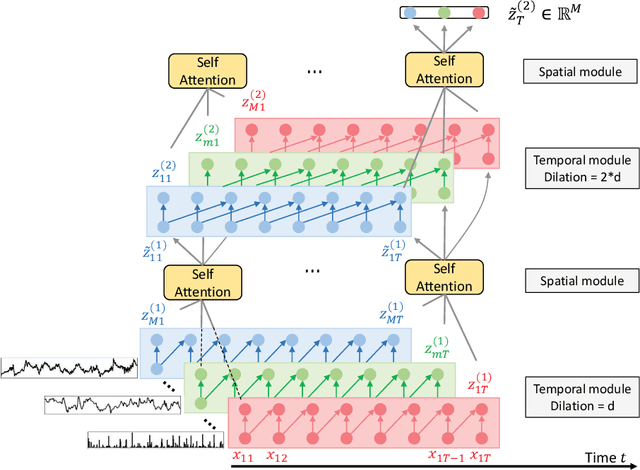
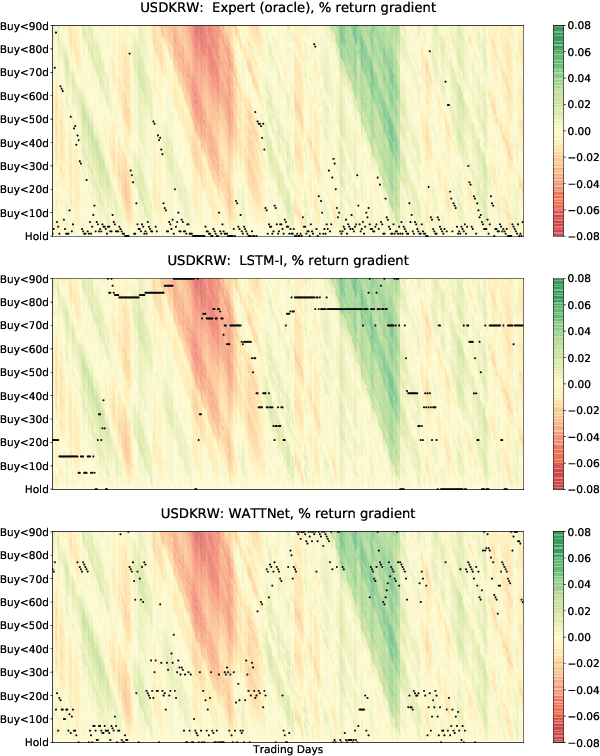
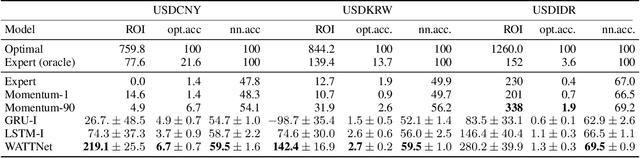
Finance is a particularly challenging application area for deep learning models due to low noise-to-signal ratio, non-stationarity, and partial observability. Non-deliverable-forwards (NDF), a derivatives contract used in foreign exchange (FX) trading, presents additional difficulty in the form of long-term planning required for an effective selection of start and end date of the contract. In this work, we focus on tackling the problem of NDF tenor selection by leveraging high-dimensional sequential data consisting of spot rates, technical indicators and expert tenor patterns. To this end, we construct a dataset from the Depository Trust & Clearing Corporation (DTCC) NDF data that includes a comprehensive list of NDF volumes and daily spot rates for 64 FX pairs. We introduce WaveATTentionNet (WATTNet), a novel temporal convolution (TCN) model for spatio-temporal modeling of highly multivariate time series, and validate it across NDF markets with varying degrees of dissimilarity between the training and test periods in terms of volatility and general market regimes. The proposed method achieves a significant positive return on investment (ROI) in all NDF markets under analysis, outperforming recurrent and classical baselines by a wide margin. Finally, we propose two orthogonal interpretability approaches to verify noise stability and detect the driving factors of the learned tenor selection strategy.
A Simple Loss Function for Improving the Convergence and Accuracy of Visual Question Answering Models
Aug 02, 2017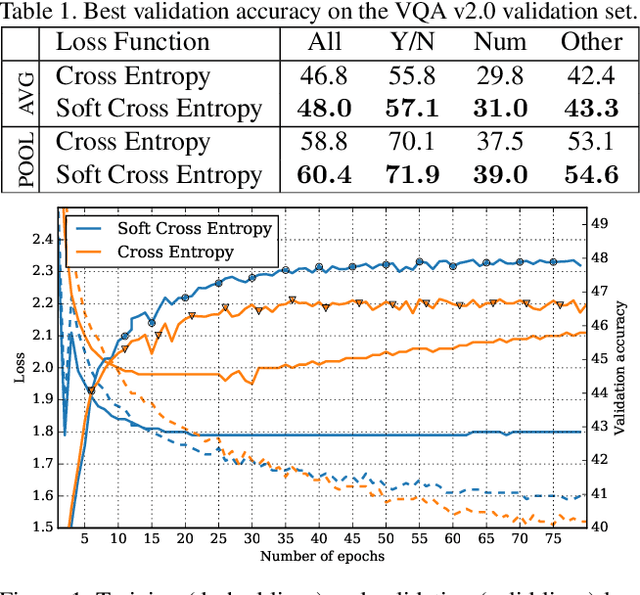
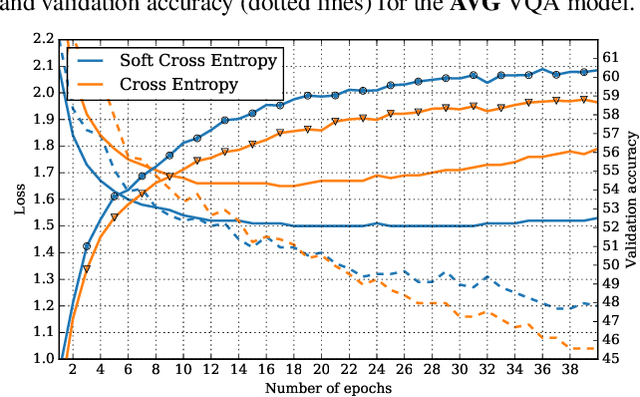
Visual question answering as recently proposed multimodal learning task has enjoyed wide attention from the deep learning community. Lately, the focus was on developing new representation fusion methods and attention mechanisms to achieve superior performance. On the other hand, very little focus has been put on the models' loss function, arguably one of the most important aspects of training deep learning models. The prevailing practice is to use cross entropy loss function that penalizes the probability given to all the answers in the vocabulary except the single most common answer for the particular question. However, the VQA evaluation function compares the predicted answer with all the ground-truth answers for the given question and if there is a matching, a partial point is given. This causes a discrepancy between the model's cross entropy loss and the model's accuracy as calculated by the VQA evaluation function. In this work, we propose a novel loss, termed as soft cross entropy, that considers all ground-truth answers and thus reduces the loss-accuracy discrepancy. The proposed loss leads to an improved training convergence of VQA models and an increase in accuracy as much as 1.6%.
Efficient Hyperparameter Optimization of Deep Learning Algorithms Using Deterministic RBF Surrogates
Jan 21, 2017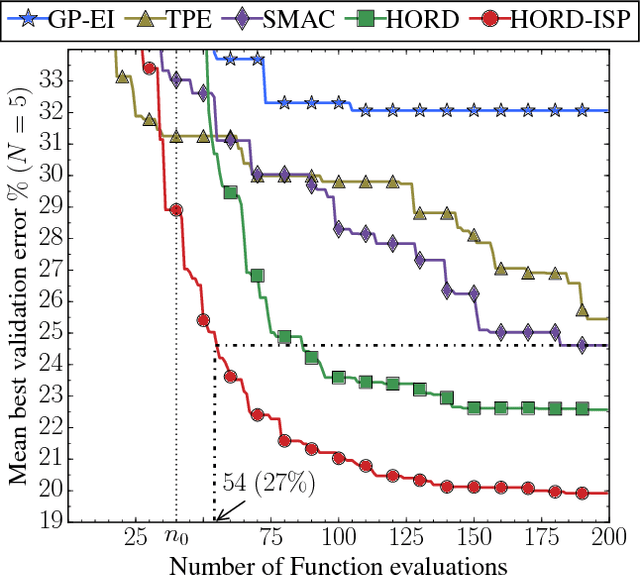
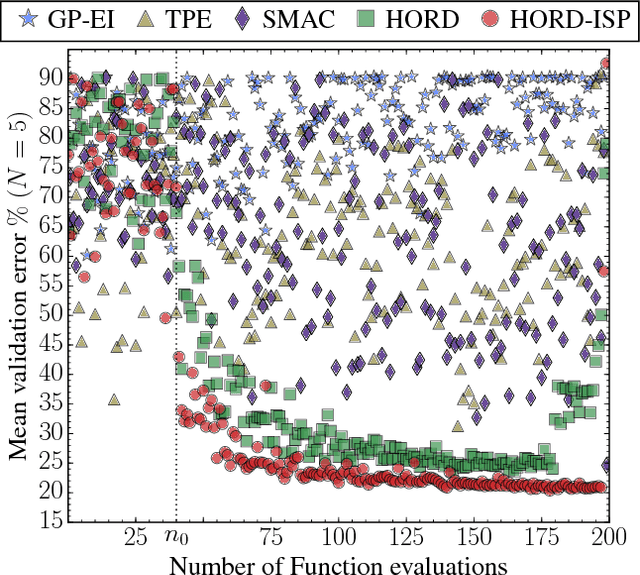
Automatically searching for optimal hyperparameter configurations is of crucial importance for applying deep learning algorithms in practice. Recently, Bayesian optimization has been proposed for optimizing hyperparameters of various machine learning algorithms. Those methods adopt probabilistic surrogate models like Gaussian processes to approximate and minimize the validation error function of hyperparameter values. However, probabilistic surrogates require accurate estimates of sufficient statistics (e.g., covariance) of the error distribution and thus need many function evaluations with a sizeable number of hyperparameters. This makes them inefficient for optimizing hyperparameters of deep learning algorithms, which are highly expensive to evaluate. In this work, we propose a new deterministic and efficient hyperparameter optimization method that employs radial basis functions as error surrogates. The proposed mixed integer algorithm, called HORD, searches the surrogate for the most promising hyperparameter values through dynamic coordinate search and requires many fewer function evaluations. HORD does well in low dimensions but it is exceptionally better in higher dimensions. Extensive evaluations on MNIST and CIFAR-10 for four deep neural networks demonstrate HORD significantly outperforms the well-established Bayesian optimization methods such as GP, SMAC, and TPE. For instance, on average, HORD is more than 6 times faster than GP-EI in obtaining the best configuration of 19 hyperparameters.
Hyperparameter Transfer Learning through Surrogate Alignment for Efficient Deep Neural Network Training
Jul 31, 2016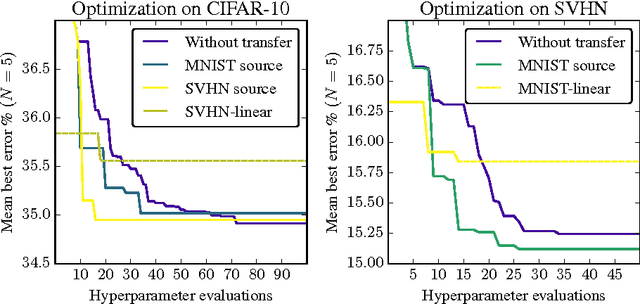
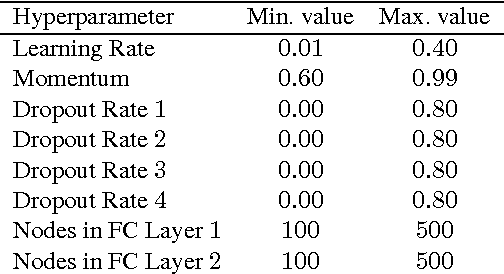
Recently, several optimization methods have been successfully applied to the hyperparameter optimization of deep neural networks (DNNs). The methods work by modeling the joint distribution of hyperparameter values and corresponding error. Those methods become less practical when applied to modern DNNs whose training may take a few days and thus one cannot collect sufficient observations to accurately model the distribution. To address this challenging issue, we propose a method that learns to transfer optimal hyperparameter values for a small source dataset to hyperparameter values with comparable performance on a dataset of interest. As opposed to existing transfer learning methods, our proposed method does not use hand-designed features. Instead, it uses surrogates to model the hyperparameter-error distributions of the two datasets and trains a neural network to learn the transfer function. Extensive experiments on three CV benchmark datasets clearly demonstrate the efficiency of our method.
A Focused Dynamic Attention Model for Visual Question Answering
Apr 06, 2016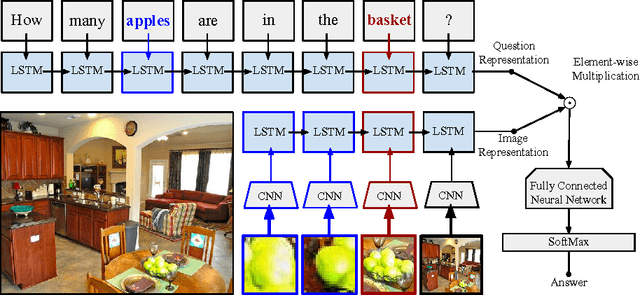
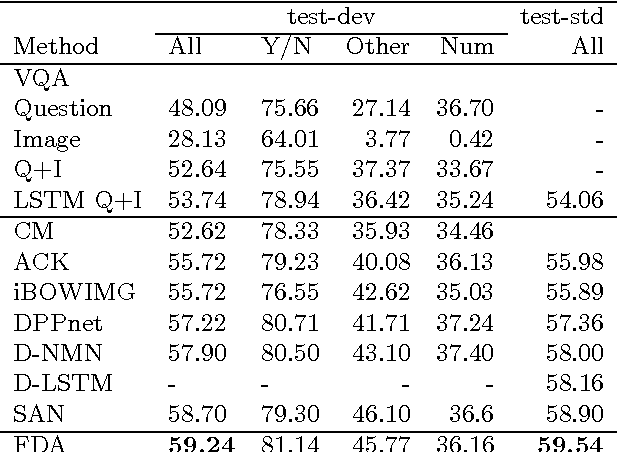
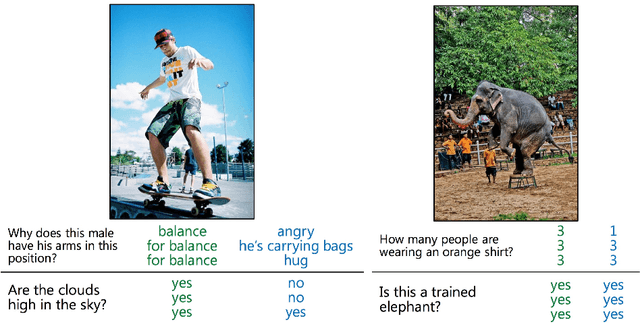
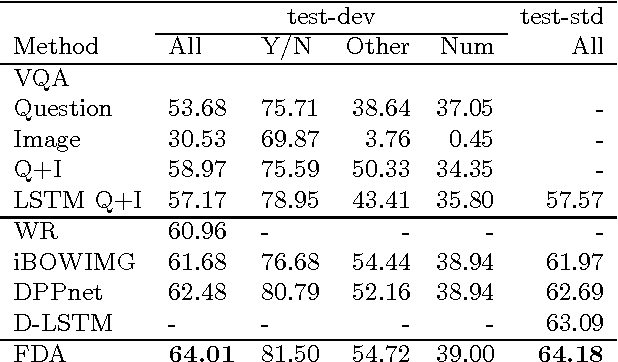
Visual Question and Answering (VQA) problems are attracting increasing interest from multiple research disciplines. Solving VQA problems requires techniques from both computer vision for understanding the visual contents of a presented image or video, as well as the ones from natural language processing for understanding semantics of the question and generating the answers. Regarding visual content modeling, most of existing VQA methods adopt the strategy of extracting global features from the image or video, which inevitably fails in capturing fine-grained information such as spatial configuration of multiple objects. Extracting features from auto-generated regions -- as some region-based image recognition methods do -- cannot essentially address this problem and may introduce some overwhelming irrelevant features with the question. In this work, we propose a novel Focused Dynamic Attention (FDA) model to provide better aligned image content representation with proposed questions. Being aware of the key words in the question, FDA employs off-the-shelf object detector to identify important regions and fuse the information from the regions and global features via an LSTM unit. Such question-driven representations are then combined with question representation and fed into a reasoning unit for generating the answers. Extensive evaluation on a large-scale benchmark dataset, VQA, clearly demonstrate the superior performance of FDA over well-established baselines.