 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Focused Dynamic Attention Model for Visual Question Answering
Paper and Code
Apr 06, 2016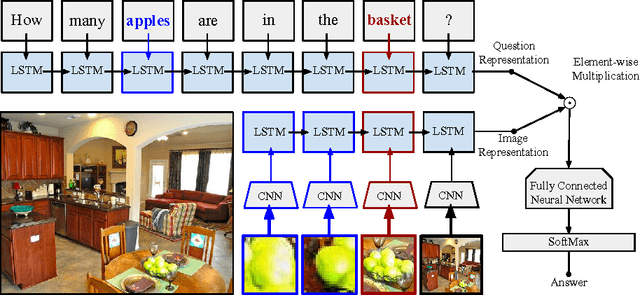
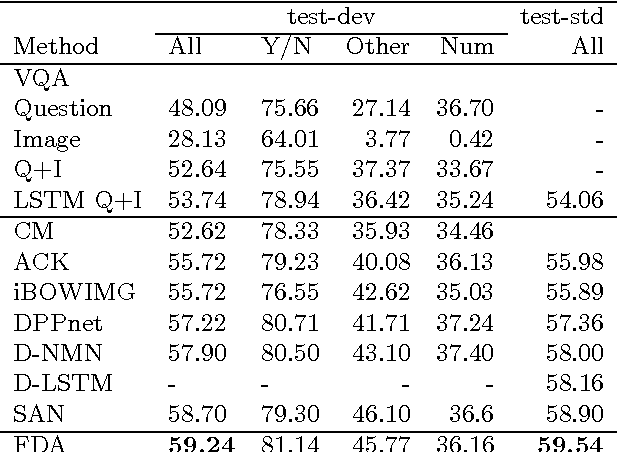
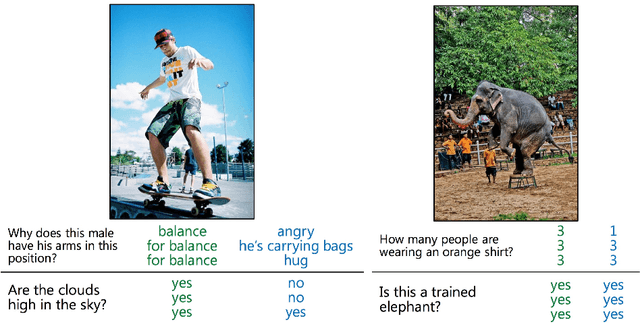
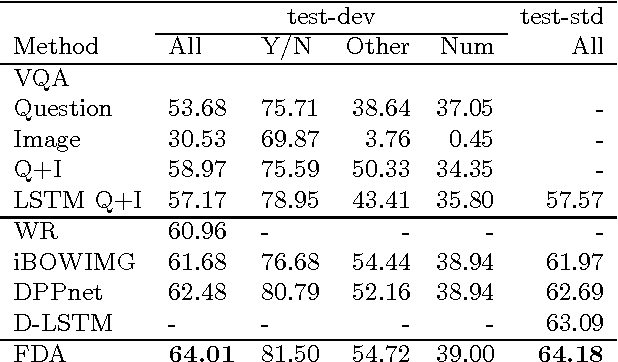
Visual Question and Answering (VQA) problems are attracting increasing interest from multiple research disciplines. Solving VQA problems requires techniques from both computer vision for understanding the visual contents of a presented image or video, as well as the ones from natural language processing for understanding semantics of the question and generating the answers. Regarding visual content modeling, most of existing VQA methods adopt the strategy of extracting global features from the image or video, which inevitably fails in capturing fine-grained information such as spatial configuration of multiple objects. Extracting features from auto-generated regions -- as some region-based image recognition methods do -- cannot essentially address this problem and may introduce some overwhelming irrelevant features with the question. In this work, we propose a novel Focused Dynamic Attention (FDA) model to provide better aligned image content representation with proposed questions. Being aware of the key words in the question, FDA employs off-the-shelf object detector to identify important regions and fuse the information from the regions and global features via an LSTM unit. Such question-driven representations are then combined with question representation and fed into a reasoning unit for generating the answers. Extensive evaluation on a large-scale benchmark dataset, VQA, clearly demonstrate the superior performance of FDA over well-established baselines.