 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Transfer Learning through Surrogate Alignment for Efficient Deep Neural Network Training
Paper and Code
Jul 31, 2016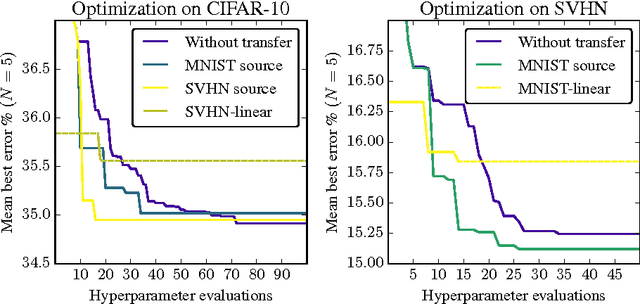
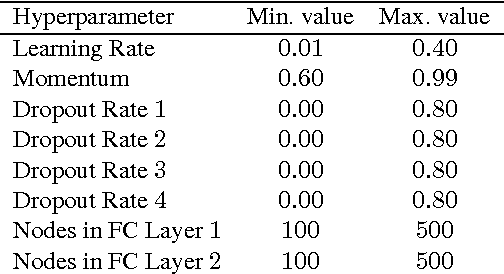
Recently, several optimization methods have been successfully applied to the hyperparameter optimization of deep neural networks (DNNs). The methods work by modeling the joint distribution of hyperparameter values and corresponding error. Those methods become less practical when applied to modern DNNs whose training may take a few days and thus one cannot collect sufficient observations to accurately model the distribution. To address this challenging issue, we propose a method that learns to transfer optimal hyperparameter values for a small source dataset to hyperparameter values with comparable performance on a dataset of interest. As opposed to existing transfer learning methods, our proposed method does not use hand-designed features. Instead, it uses surrogates to model the hyperparameter-error distributions of the two datasets and trains a neural network to learn the transfer function. Extensive experiments on three CV benchmark datasets clearly demonstrate the efficiency of our method.