 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed Word Selection for Weakly-Supervised Text Classification with Unsupervised Error Estimation
Apr 20, 2021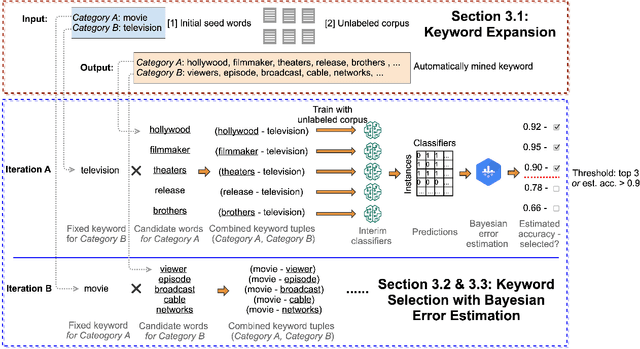

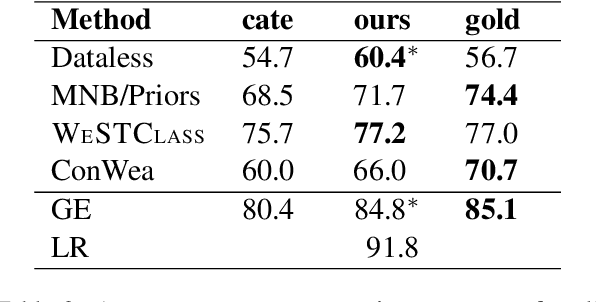
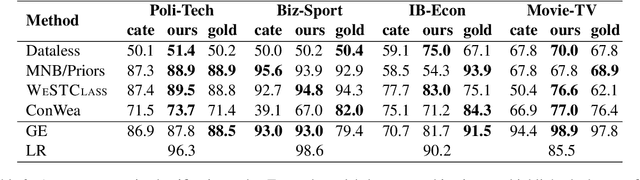
Weakly-supervised text classification aims to induce text classifiers from only a few user-provided seed words. The vast majority of previous work assumes high-quality seed words are given. However, the expert-annotated seed words are sometimes non-trivial to come up with. Furthermore, in the weakly-supervised learning setting, we do not have any labeled document to measure the seed words' efficacy, making the seed word selection process "a walk in the dark". In this work, we remove the need for expert-curated seed words by first mining (noisy) candidate seed words associated with the category names. We then train interim models with individual candidate seed words. Lastly, we estimate the interim models' error rate in an unsupervised manner. The seed words that yield the lowest estimated error rates are added to the final seed word set. A comprehensive evaluation of six binary classification tasks on four popular datasets demonstrates that the proposed method outperforms a baseline using only category name seed words and obtained comparable performance as a counterpart using expert-annotated seed words.
Generating Coherent and Diverse Slogans with Sequence-to-Sequence Transformer
Feb 11, 2021
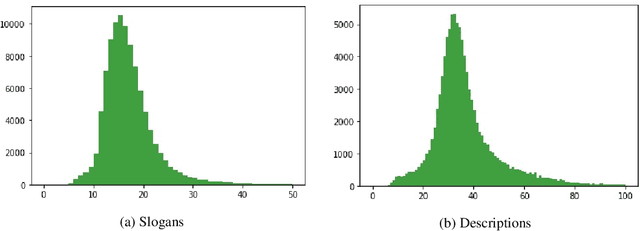

Previous work in slogan generation focused on generating novel slogans by utilising templates mined from real slogans. While some such slogans can be catchy, they are often not coherent with the company's focus or style across their marketing communications because the templates are mined from other companies' slogans. We propose a sequence-to-sequence transformer model to generate slogans from a brief company description. A naive sequence-to-sequence model fine-tuned for slogan generation is prone to introducing false information, especially unrelated company names appearing in the training data. We use delexicalisation to address this problem and improve the generated slogans' quality by a large margin. Furthermore, we apply two simple but effective approaches to generate more diverse slogans. Firstly, we train a slogan generator conditioned on the industry. During inference time, by changing the industry, we can obtain different "flavours" of slogans. Secondly, instead of using only the company description as the input sequence, we sample random paragraphs from the company's website. Surprisingly, the model can generate meaningful slogans, even if the input sequence does not resemble a company description. We validate the effectiveness of the proposed method with both quantitative evaluation and qualitative evaluation. Our best model achieved a ROUGE-1/-2/-L F1 score of 53.13/33.30/46.49. Besides, human evaluators assigned the generated slogans an average score of 3.39 on a scale of 1-5, indicating the system can generate plausible slogans with a quality close to human-written ones (average score 3.55).