 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlot Writing From Pre-Trained Language Models
Jun 07, 2022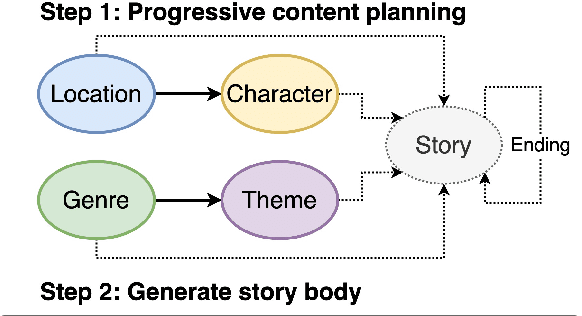



Pre-trained language models (PLMs) fail to generate long-form narrative text because they do not consider global structure. As a result, the generated texts are often incohesive, repetitive, or lack content. Recent work in story generation reintroduced explicit content planning in the form of prompts, keywords, or semantic frames. Trained on large parallel corpora, these models can generate more logical event sequences and thus more contentful stories. However, these intermediate representations are often not in natural language and cannot be utilized by PLMs without fine-tuning. We propose generating story plots using off-the-shelf PLMs while maintaining the benefit of content planning to generate cohesive and contentful stories. Our proposed method, ScratchPlot, first prompts a PLM to compose a content plan. Then, we generate the story's body and ending conditioned on the content plan. Furthermore, we take a generate-and-rank approach by using additional PLMs to rank the generated (story, ending) pairs. We benchmark our method with various baselines and achieved superior results in both human and automatic evaluation.
Bootstrapping Large-Scale Fine-Grained Contextual Advertising Classifier from Wikipedia
Feb 12, 2021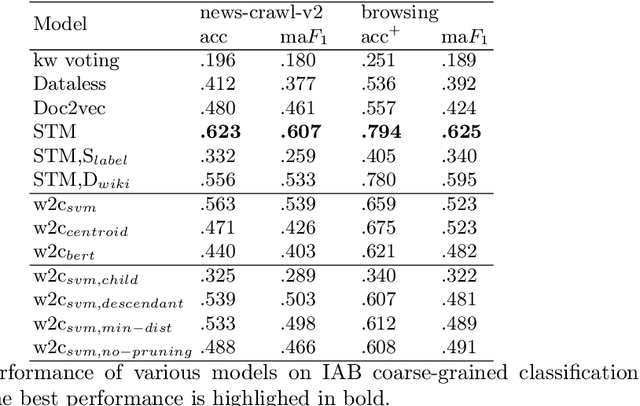
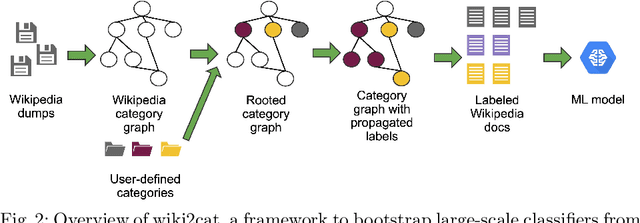
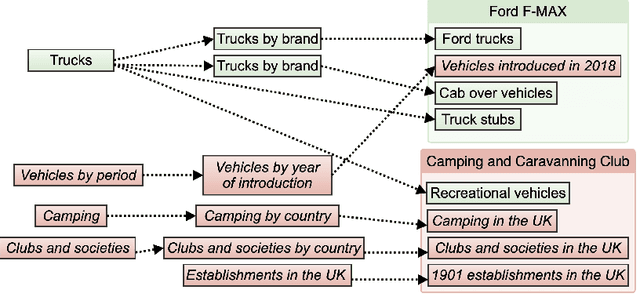
Contextual advertising provides advertisers with the opportunity to target the context which is most relevant to their ads. However, its power cannot be fully utilized unless we can target the page content using fine-grained categories, e.g., "coupe" vs. "hatchback" instead of "automotive" vs. "sport". The widely used advertising content taxonomy (IAB taxonomy) consists of 23 coarse-grained categories and 355 fine-grained categories. With the large number of categories, it becomes very challenging either to collect training documents to build a supervised classification model, or to compose expert-written rules in a rule-based classification system. Besides, in fine-grained classification, different categories often overlap or co-occur, making it harder to classify accurately. In this work, we propose wiki2cat, a method to tackle the problem of large-scaled fine-grained text classification by tapping on Wikipedia category graph. The categories in IAB taxonomy are first mapped to category nodes in the graph. Then the label is propagated across the graph to obtain a list of labeled Wikipedia documents to induce text classifiers. The method is ideal for large-scale classification problems since it does not require any manually-labeled document or hand-curated rules or keywords. The proposed method is benchmarked with various learning-based and keyword-based baselines and yields competitive performance on both publicly available datasets and a new dataset containing more than 300 fine-grained categories.