 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Cross-Lingual Adjustment of Contextual Word Representations on Zero-Shot Transfer
Apr 13, 2022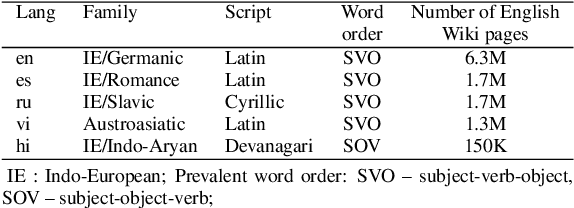
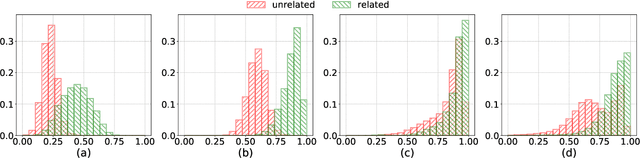

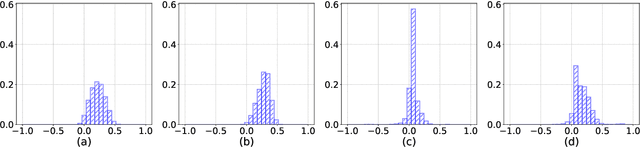
Large pre-trained multilingual models such as mBERT and XLM-R enabled effective cross-lingual zero-shot transfer in many NLP tasks. A cross-lingual adjustment of these models using a small parallel corpus can potentially further improve results. This is a more data efficient method compared to training a machine-translation system or a multi-lingual model from scratch using only parallel data. In this study, we experiment with zero-shot transfer of English models to four typologically different languages (Spanish, Russian, Vietnamese, and Hindi) and three NLP tasks (QA, NLI, and NER). We carry out a cross-lingual adjustment of an off-the-shelf mBERT model. We confirm prior finding that this adjustment makes embeddings of semantically similar words from different languages closer to each other, while keeping unrelated words apart. However, from the paired-differences histograms introduced in our work we can see that the adjustment only modestly affects the relative distances between related and unrelated words. In contrast, fine-tuning of mBERT on English data (for a specific task such as NER) draws embeddings of both related and unrelated words closer to each other. The cross-lingual adjustment of mBERT improves NLI in four languages and NER in two languages, while QA performance never improves and sometimes degrades. When we fine-tune a cross-lingual adjusted mBERT for a specific task (e.g., NLI), the cross-lingual adjustment of mBERT may still improve the separation between related and related words, but this works consistently only for the XNLI task. Our study contributes to a better understanding of cross-lingual transfer capabilities of large multilingual language models and of effectiveness of their cross-lingual adjustment in various NLP tasks.