 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Quality Assessment of Blind Sweep Obstetric Ultrasound for Improved Diagnosis
Mar 26, 2026Blind Sweep Obstetric Ultrasound (BSOU) enables scalable fetal imaging in low-resource settings by allowing minimally trained operators to acquire standardized sweep videos for automated Artificial Intelligence(AI) interpretation. However, the reliability of such AI systems depends critically on the quality of the acquired sweeps, and little is known about how deviations from the intended protocol affect downstream predictions. In this work, we present a systematic evaluation of BSOU quality and its impact on three key AI tasks: sweep-tag classification, fetal presentation classification, and placenta-location classification. We simulate plausible acquisition deviations, including reversed sweep direction, probe inversion, and incomplete sweeps, to quantify model robustness, and we develop automated quality-assessment models capable of detecting these perturbations. To approximate real-world deployment, we simulate a feedback loop in which flagged sweeps are re-acquired, showing that such correction improves downstream task performance. Our findings highlight the sensitivity of BSOU-based AI models to acquisition variability and demonstrate that automated quality assessment can play a central role in building reliable, scalable AI-assisted prenatal ultrasound workflows, particularly in low-resource environments.
RobustFormer: Noise-Robust Pre-training for images and videos
Nov 20, 2024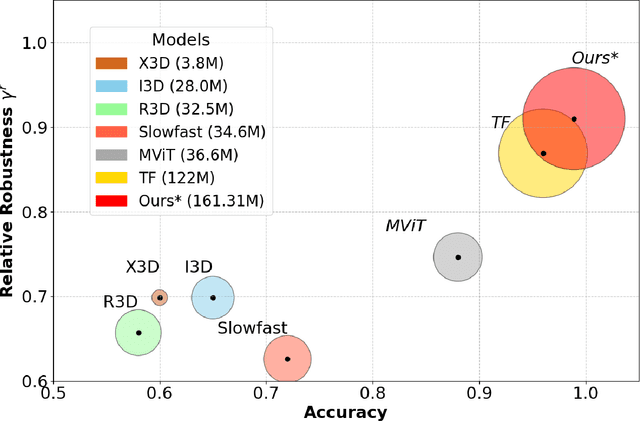
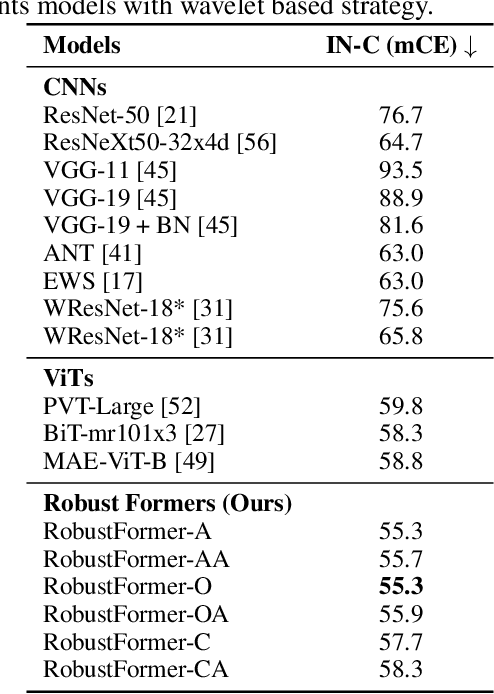
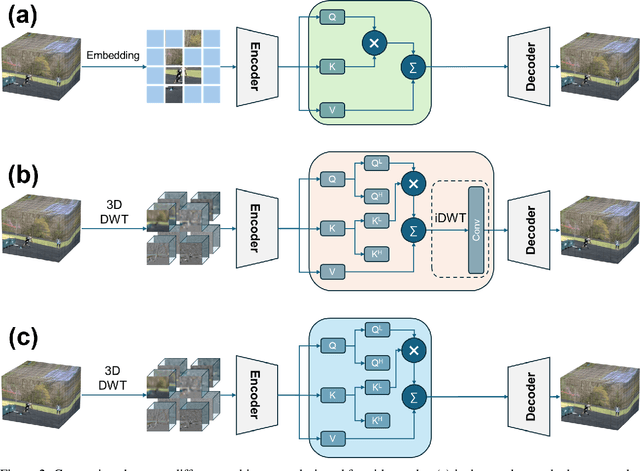
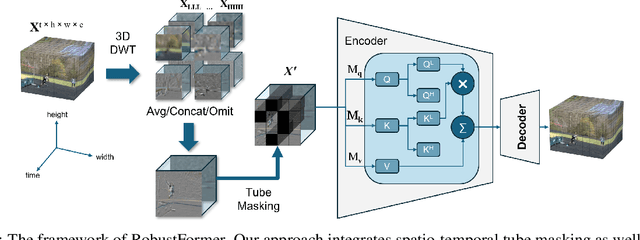
While deep learning models are powerful tools that revolutionized many areas, they are also vulnerable to noise as they rely heavily on learning patterns and features from the exact details of the clean data. Transformers, which have become the backbone of modern vision models, are no exception. Current Discrete Wavelet Transforms (DWT) based methods do not benefit from masked autoencoder (MAE) pre-training since the inverse DWT (iDWT) introduced in these approaches is computationally inefficient and lacks compatibility with video inputs in transformer architectures. In this work, we present RobustFormer, a method that overcomes these limitations by enabling noise-robust pre-training for both images and videos; improving the efficiency of DWT-based methods by removing the need for computationally iDWT steps and simplifying the attention mechanism. To our knowledge, the proposed method is the first DWT-based method compatible with video inputs and masked pre-training. Our experiments show that MAE-based pre-training allows us to bypass the iDWT step, greatly reducing computation. Through extensive tests on benchmark datasets, RobustFormer achieves state-of-the-art results for both image and video tasks.
Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Apr 28, 2024



Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
Contextual Spelling Correction with Language Model for Low-resource Setting
Apr 28, 2024



The task of Spell Correction(SC) in low-resource languages presents a significant challenge due to the availability of only a limited corpus of data and no annotated spelling correction datasets. To tackle these challenges a small-scale word-based transformer LM is trained to provide the SC model with contextual understanding. Further, the probabilistic error rules are extracted from the corpus in an unsupervised way to model the tendency of error happening(error model). Then the combination of LM and error model is used to develop the SC model through the well-known noisy channel framework. The effectiveness of this approach is demonstrated through experiments on the Nepali language where there is access to just an unprocessed corpus of textual data.