 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Semantic Similarity Methods for Maximum Human Interpretability
Paper and Code
Oct 31, 2019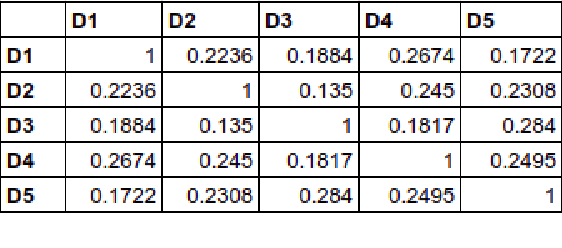


The inclusion of semantic information in any similarity measures improves the efficiency of the similarity measure and provides human interpretable results for further analysis. The similarity calculation method that focuses on features related to the text's words only, will give less accurate results. This paper presents three different methods that not only focus on the text's words but also incorporates semantic information of texts in their feature vector and computes semantic similarities. These methods are based on corpus-based and knowledge-based methods, which are: cosine similarity using tf-idf vectors, cosine similarity using word embedding and soft cosine similarity using word embedding. Among these three, cosine similarity using tf-idf vectors performed best in finding similarities between short news texts. The similar texts given by the method are easy to interpret and can be used directly in other information retrieval applications.