 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-selective Transfer Learning for Multi-Domain Speech Recognition
Paper and Code
Sep 08, 2015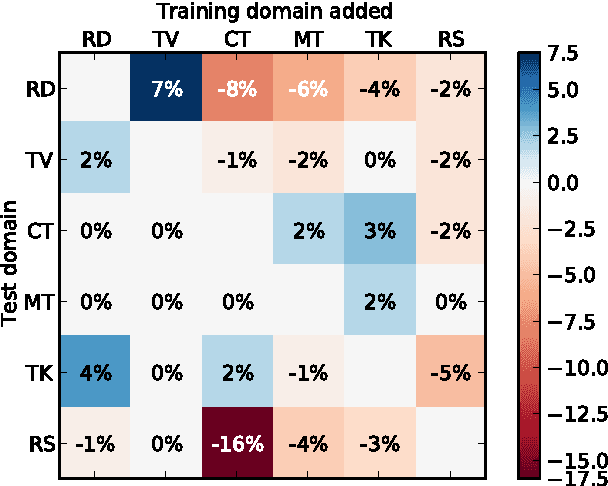


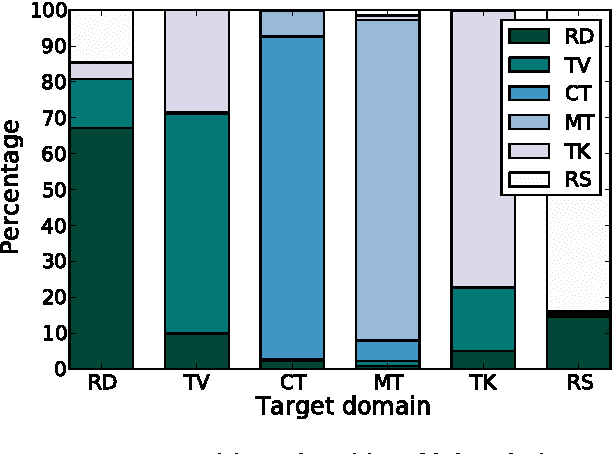
Negative transfer in training of acoustic models for automatic speech recognition has been reported in several contexts such as domain change or speaker characteristics. This paper proposes a novel technique to overcome negative transfer by efficient selection of speech data for acoustic model training. Here data is chosen on relevance for a specific target. A submodular function based on likelihood ratios is used to determine how acoustically similar each training utterance is to a target test set. The approach is evaluated on a wide-domain data set, covering speech from radio and TV broadcasts, telephone conversations, meetings, lectures and read speech. Experiments demonstrate that the proposed technique both finds relevant data and limits negative transfer. Results on a 6--hour test set show a relative improvement of 4% with data selection over using all data in PLP based models, and 2% with DNN features.