 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrap an end-to-end ASR system by multilingual training, transfer learning, text-to-text mapping and synthetic audio
Nov 25, 2020
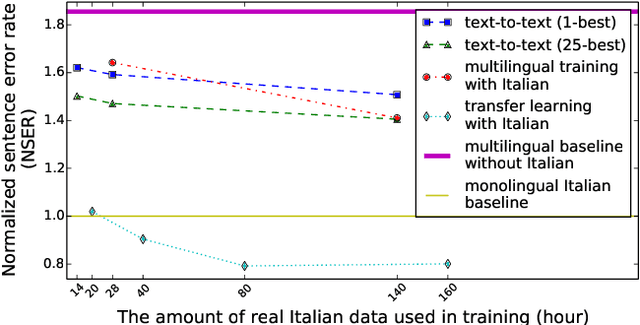
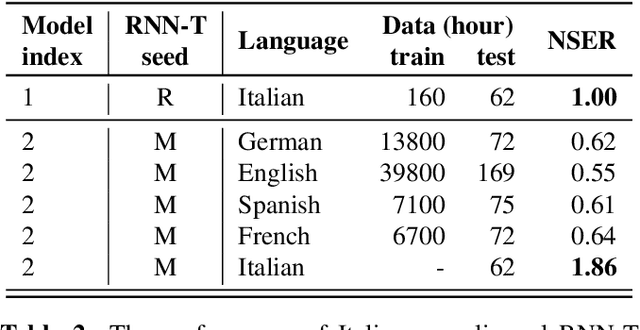
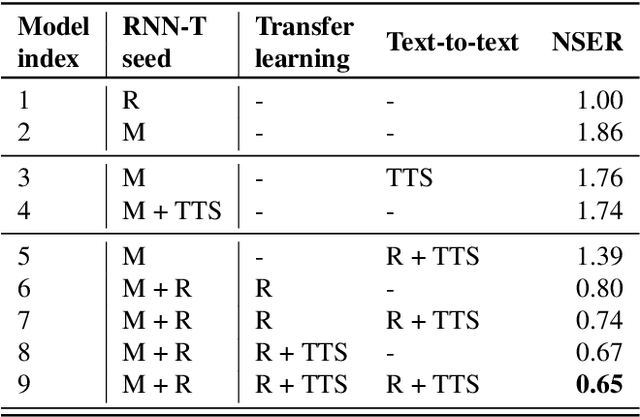
Bootstrapping speech recognition on limited data resources has been an area of active research for long. The recent transition to all-neural models and end-to-end (E2E) training brought along particular challenges as these models are known to be data hungry, but also came with opportunities around language-agnostic representations derived from multilingual data as well as shared word-piece output representations across languages that share script and roots.Here, we investigate the effectiveness of different strategies to bootstrap an RNN Transducer (RNN-T) based automatic speech recognition (ASR) system in the low resource regime,while exploiting the abundant resources available in other languages as well as the synthetic audio from a text-to-speech(TTS) engine. Experiments show that the combination of a multilingual RNN-T word-piece model, post-ASR text-to-text mapping, and synthetic audio can effectively bootstrap an ASR system for a new language in a scalable fashion with little target language data.
Exploring attention mechanism for acoustic-based classification of speech utterances into system-directed and non-system-directed
Feb 01, 2019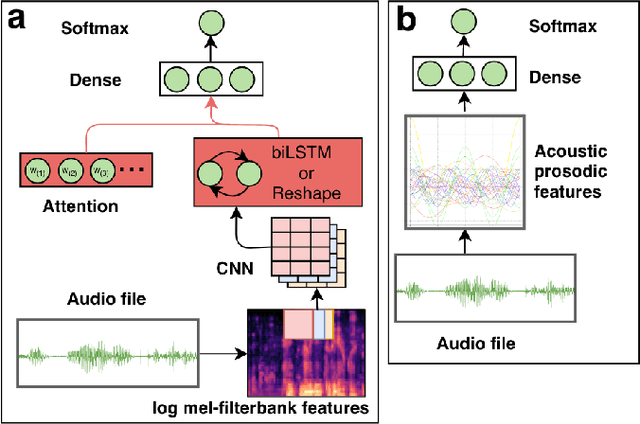
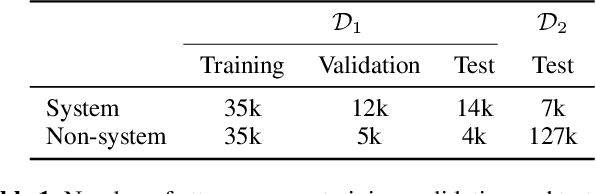
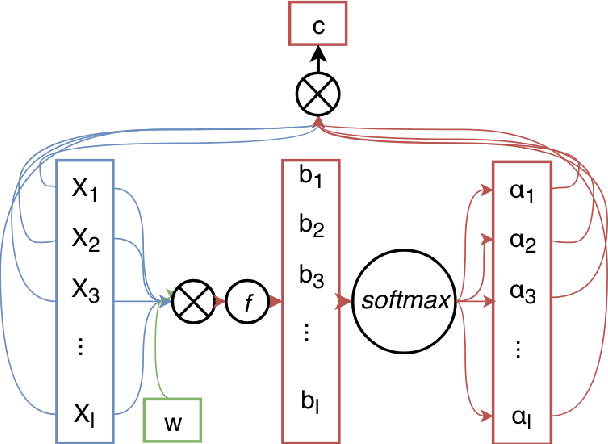
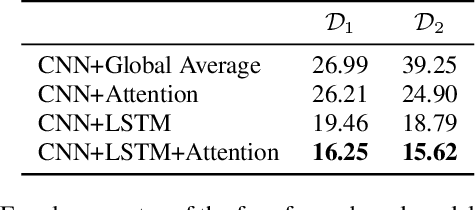
Voice controlled virtual assistants (VAs) are now available in smartphones, cars, and standalone devices in homes. In most cases, the user needs to first "wake-up" the VA by saying a particular word/phrase every time he or she wants the VA to do something. Eliminating the need for saying the wake-up word for every interaction could improve the user experience. This would require the VA to have the capability to detect the speech that is being directed at it and respond accordingly. In other words, the challenge is to distinguish between system-directed and non-system-directed speech utterances. In this paper, we present a number of neural network architectures for tackling this classification problem based on using only acoustic features. These architectures are based on using convolutional, recurrent and feed-forward layers. In addition, we investigate the use of an attention mechanism applied to the output of the convolutional and the recurrent layers. It is shown that incorporating the proposed attention mechanism into the models always leads to significant improvement in classification accuracy. The best model achieved equal error rates of 16.25 and 15.62 percents on two distinct realistic datasets.