 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training of a Neural HMM with Label and Transition Probabilities
Paper and Code
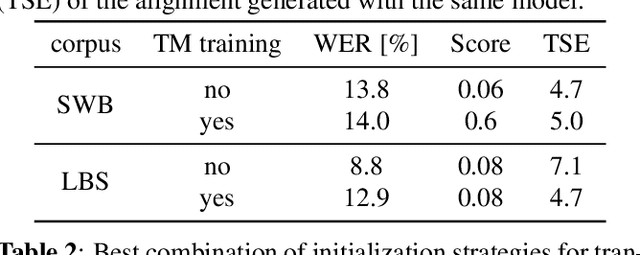
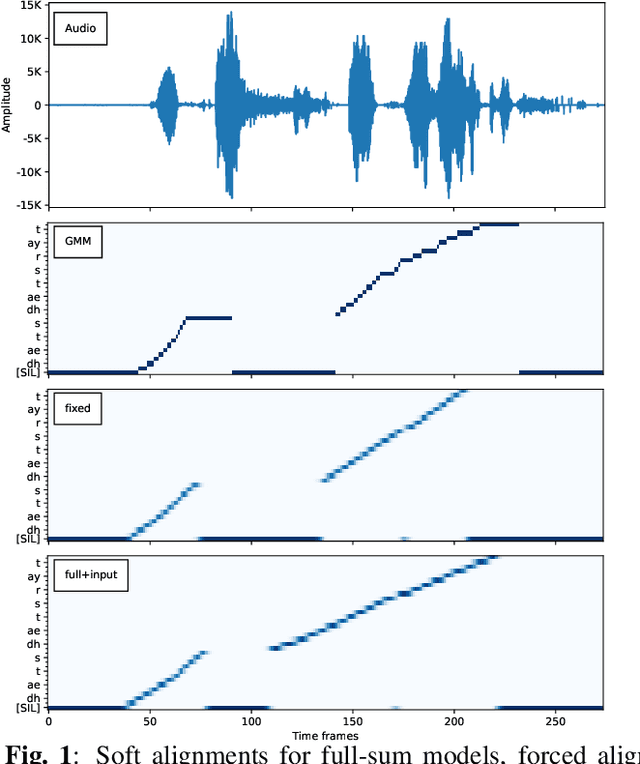

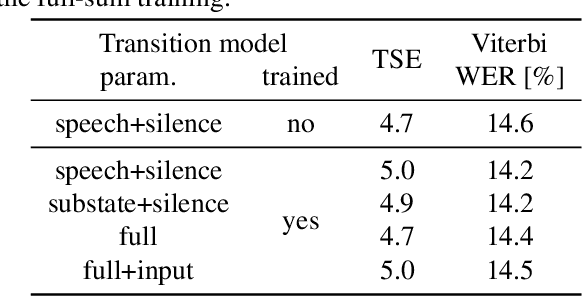
We investigate a novel modeling approach for end-to-end neural network training using hidden Markov models (HMM) where the transition probabilities between hidden states are modeled and learned explicitly. Most contemporary sequence-to-sequence models allow for from-scratch training by summing over all possible label segmentations in a given topology. In our approach there are explicit, learnable probabilities for transitions between segments as opposed to a blank label that implicitly encodes duration statistics. We implement a GPU-based forward-backward algorithm that enables the simultaneous training of label and transition probabilities. We investigate recognition results and additionally Viterbi alignments of our models. We find that while the transition model training does not improve recognition performance, it has a positive impact on the alignment quality. The generated alignments are shown to be viable targets in state-of-the-art Viterbi trainings.