 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Factored Hybrid HMM Acoustic Modeling without State Tying
Paper and Code

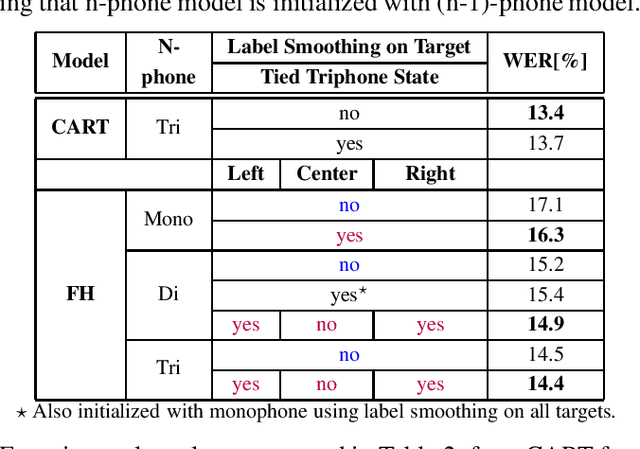
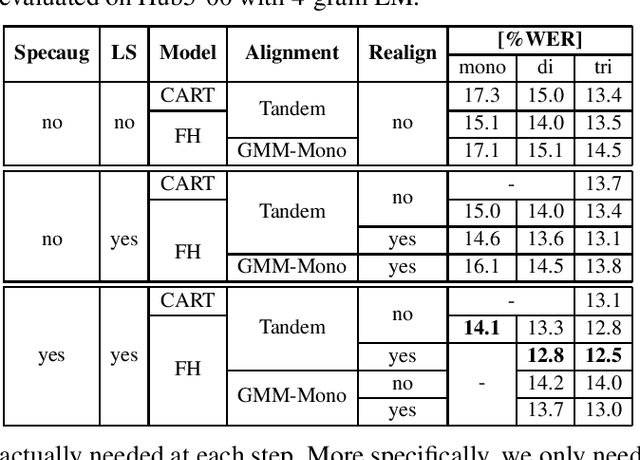
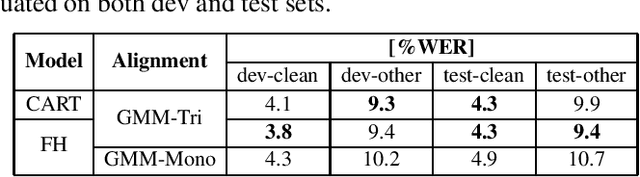
In this work, we show that a factored hybrid hidden Markov model (FH-HMM) which is defined without any phonetic state-tying outperforms a state-of-the-art hybrid HMM. The factored hybrid HMM provides a link to transducer models in the way it models phonetic (label) context while preserving the strict separation of acoustic and language model of the hybrid HMM approach. Furthermore, we show that the factored hybrid model can be trained from scratch without using phonetic state-tying in any of the training steps. Our modeling approach enables triphone context while avoiding phonetic state-tying by a decomposition into locally normalized factored posteriors for monophones/HMM states in phoneme context. Experimental results are provided for Switchboard 300h and LibriSpeech. On the former task we also show that by avoiding the phonetic state-tying step, the factored hybrid can take better advantage of regularization techniques during training, compared to the standard hybrid HMM with phonetic state-tying based on classification and regression trees (CART).