 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Consistent Hybrid HMM Acoustic Modeling
Paper and Code
Apr 28, 2021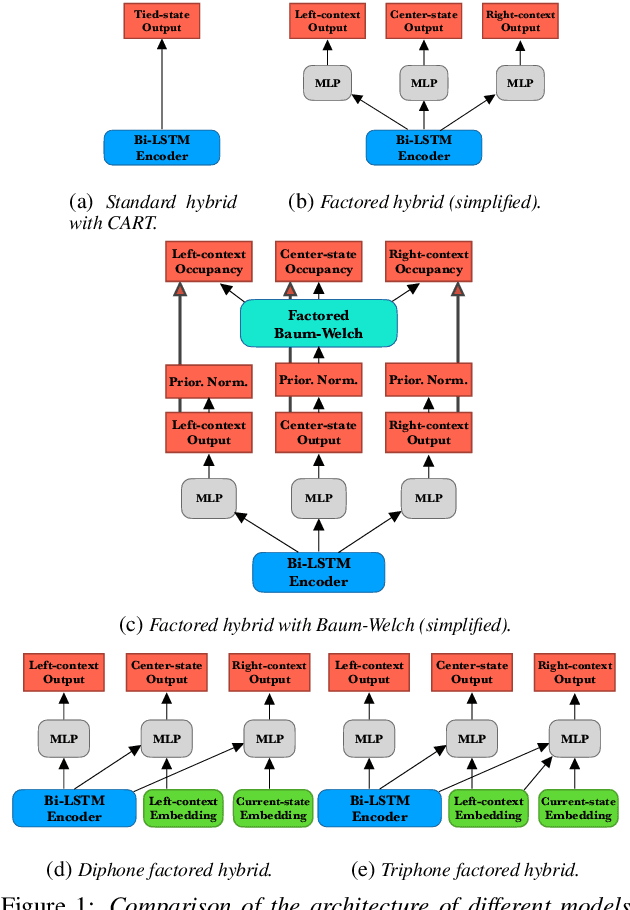
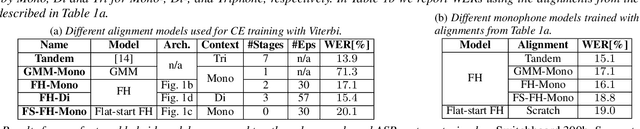
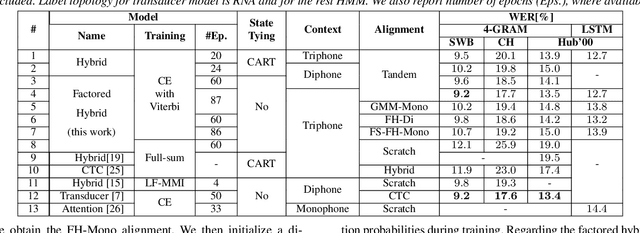
High-performance hybrid automatic speech recognition (ASR) systems are often trained with clustered triphone outputs, and thus require a complex training pipeline to generate the clustering. The same complex pipeline is often utilized in order to generate an alignment for use in frame-wise cross-entropy training. In this work, we propose a flat-start factored hybrid model trained by modeling the full set of triphone states explicitly without relying on clustering methods. This greatly simplifies the training of new models. Furthermore, we study the effect of different alignments used for Viterbi training. Our proposed models achieve competitive performance on the Switchboard task compared to systems using clustered triphones and other flat-start models in the literature.