 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Dependent Acoustic Modeling without Explicit Phone Clustering
Paper and Code
May 15, 2020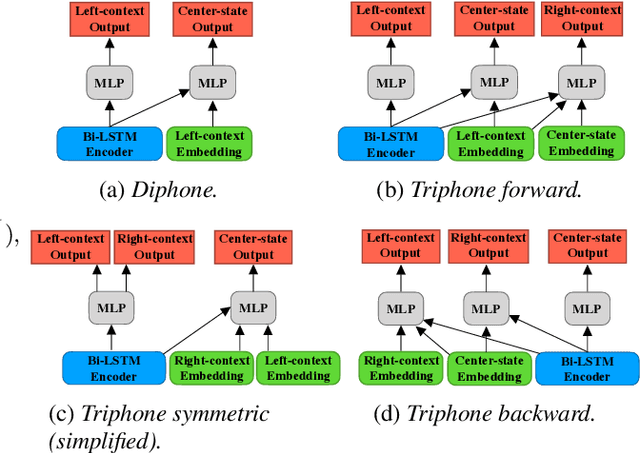
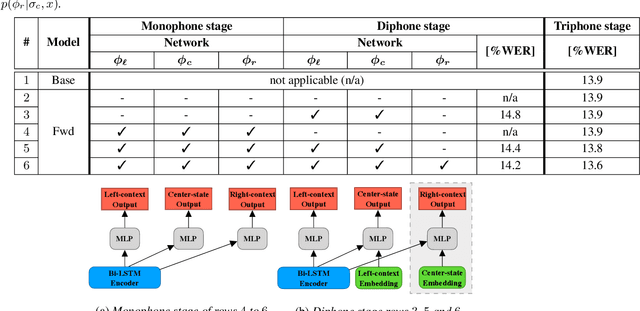
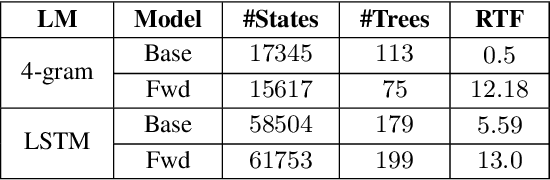
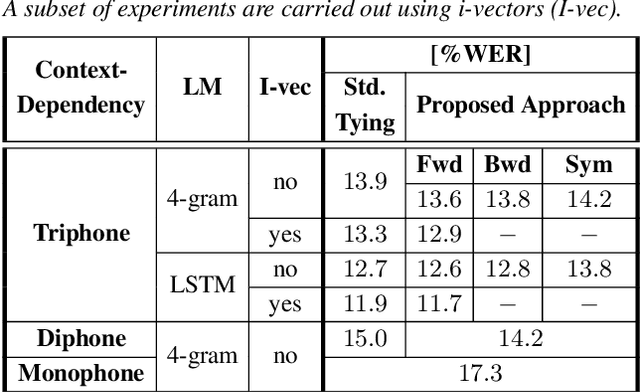
Phoneme-based acoustic modeling of large vocabulary automatic speech recognition takes advantage of phoneme context. The large number of context-dependent (CD) phonemes and their highly varying statistics require tying or smoothing to enable robust training. Usually, Classification and Regression Trees are used for phonetic clustering, which is standard in Hidden Markov Model (HMM)-based systems. However, this solution introduces a secondary training objective and does not allow for end-to-end training. In this work, we address a direct phonetic context modeling for the hybrid Deep Neural Network (DNN)/HMM, that does not build on any phone clustering algorithm for the determination of the HMM state inventory. By performing different decompositions of the joint probability of the center phoneme state and its left and right contexts, we obtain a factorized network consisting of different components, trained jointly. Moreover, the representation of the phonetic context for the network relies on phoneme embeddings. The recognition accuracy of our proposed models on the Switchboard task is comparable and outperforms slightly the hybrid model using the standard state-tying decision trees.