 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effect of Label Topology and Training Criterion on ASR Performance and Alignment Quality
Paper and Code
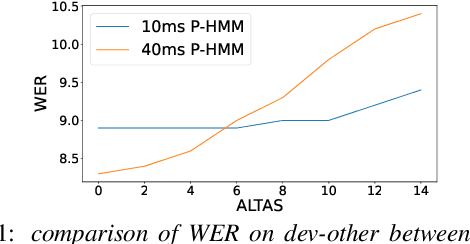
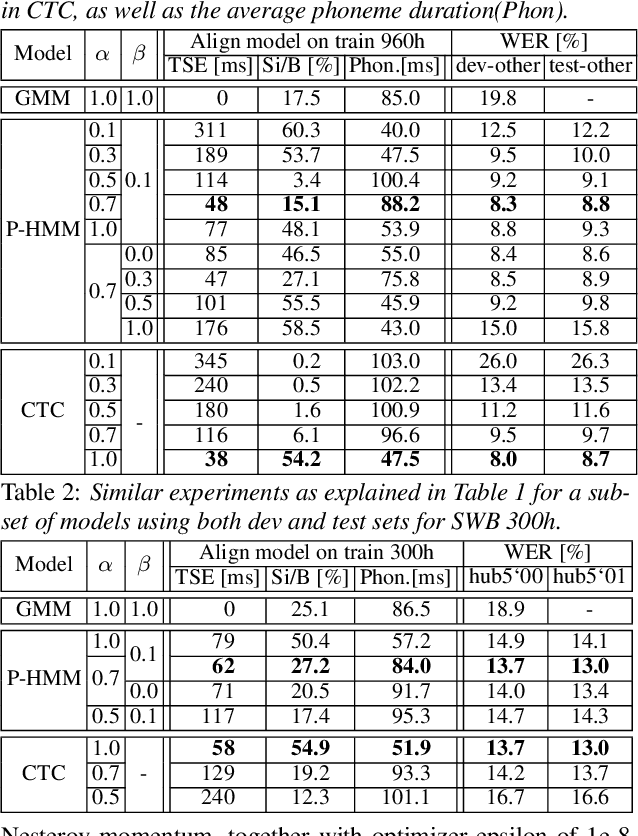
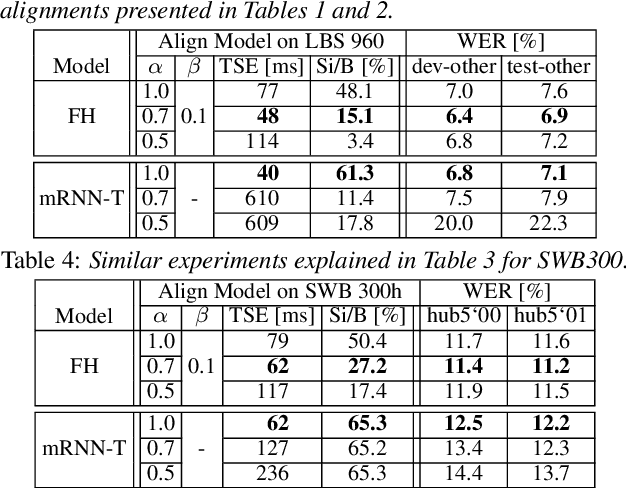
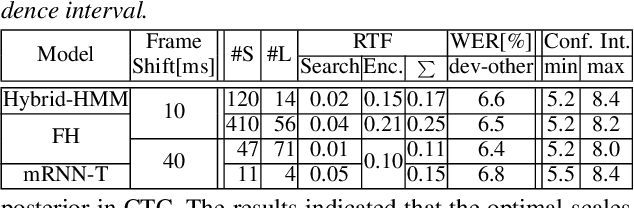
The ongoing research scenario for automatic speech recognition (ASR) envisions a clear division between end-to-end approaches and classic modular systems. Even though a high-level comparison between the two approaches in terms of their requirements and (dis)advantages is commonly addressed, a closer comparison under similar conditions is not readily available in the literature. In this work, we present a comparison focused on the label topology and training criterion. We compare two discriminative alignment models with hidden Markov model (HMM) and connectionist temporal classification topology, and two first-order label context ASR models utilizing factored HMM and strictly monotonic recurrent neural network transducer, respectively. We use different measurements for the evaluation of the alignment quality, and compare word error rate and real time factor of our best systems. Experiments are conducted on the LibriSpeech 960h and Switchboard 300h tasks.