 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneme Based Neural Transducer for Large Vocabulary Speech Recognition
Paper and Code
Nov 09, 2020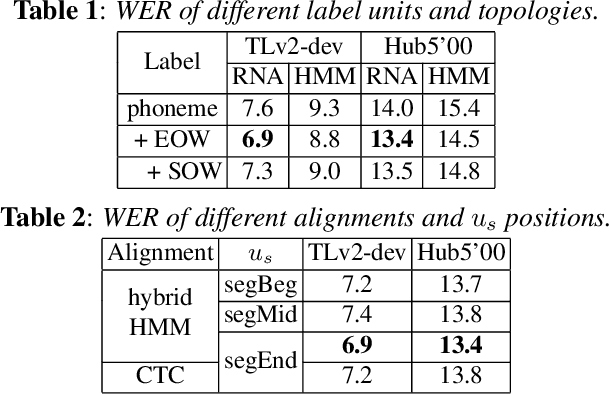
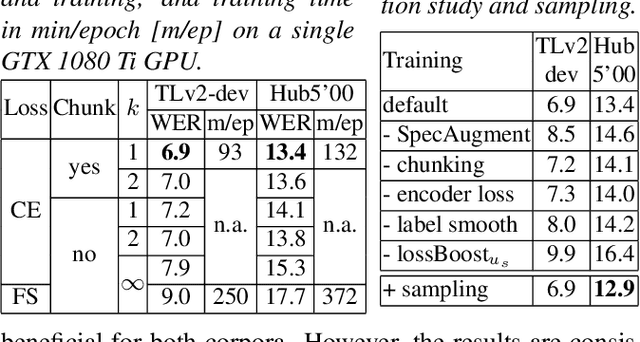

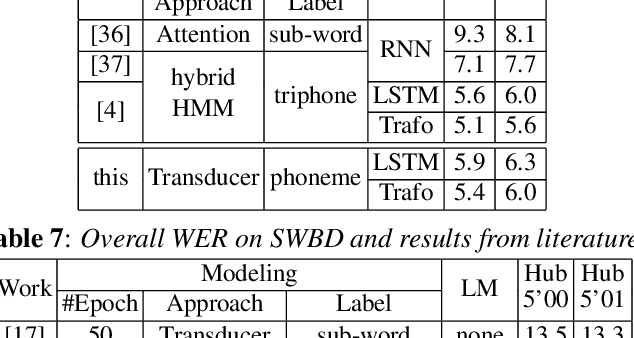
To join the advantages of classical and end-to-end approaches for speech recognition, we present a simple, novel and competitive approach for phoneme-based neural transducer modeling. Different alignment label topologies are compared and word-end-based phoneme label augmentation is proposed to improve performance. Utilizing the local dependency of phonemes, we adopt a simplified neural network structure and a straightforward integration with the external word-level language model to preserve the consistency of seq-to-seq modeling. We also present a simple, stable and efficient training procedure using frame-wise cross-entropy loss. A phonetic context size of one is shown to be sufficient for the best performance. A simplified scheduled sampling approach is applied for further improvement. We also briefly compare different decoding approaches. The overall performance of our best model is comparable to state-of-the-art results for the TED-LIUM Release 2 and Switchboard corpora.