 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture Encoder Supporting Continuous Speech Separation for Meeting Recognition
Paper and Code
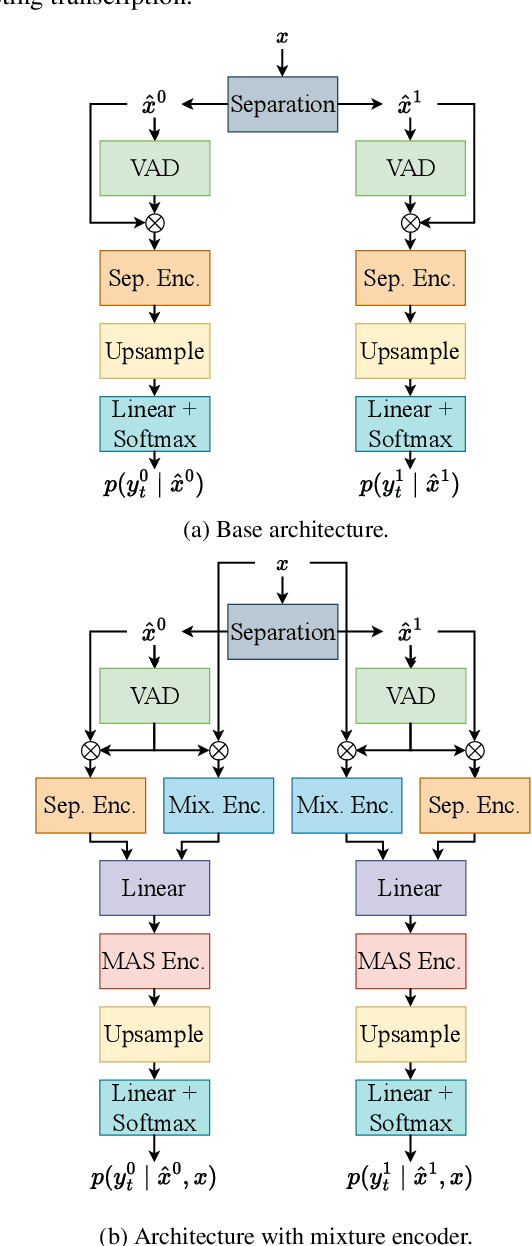



Many real-life applications of automatic speech recognition (ASR) require processing of overlapped speech. A commonmethod involves first separating the speech into overlap-free streams and then performing ASR on the resulting signals. Recently, the inclusion of a mixture encoder in the ASR model has been proposed. This mixture encoder leverages the original overlapped speech to mitigate the effect of artifacts introduced by the speech separation. Previously, however, the method only addressed two-speaker scenarios. In this work, we extend this approach to more natural meeting contexts featuring an arbitrary number of speakers and dynamic overlaps. We evaluate the performance using different speech separators, including the powerful TF-GridNet model. Our experiments show state-of-the-art performance on the LibriCSS dataset and highlight the advantages of the mixture encoder. Furthermore, they demonstrate the strong separation of TF-GridNet which largely closes the gap between previous methods and oracle separation.