 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Replacement and Combination for Hybrid ASR Systems
Paper and Code
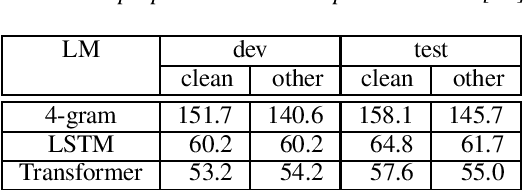


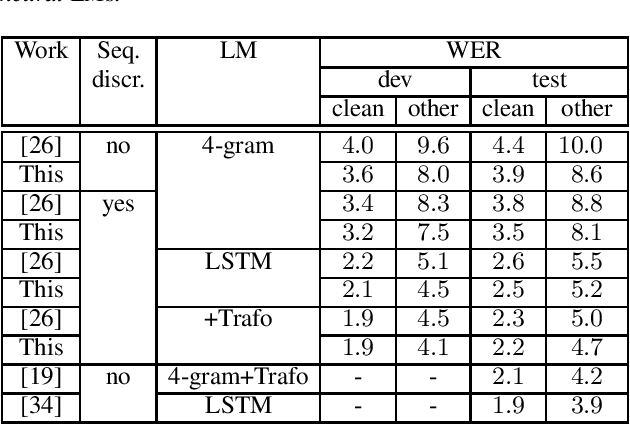
Acoustic modeling of raw waveform and learning feature extractors as part of the neural network classifier has been the goal of many studies in the area of automatic speech recognition (ASR). Recently, one line of research has focused on frameworks that can be pre-trained on audio-only data in an unsupervised fashion and aim at improving downstream ASR tasks. In this work, we investigate the usefulness of one of these front-end frameworks, namely wav2vec, for hybrid ASR systems. In addition to deploying a pre-trained feature extractor, we explore how to make use of an existing acoustic model (AM) trained on the same task with different features as well. Another neural front-end which is only trained together with the supervised ASR loss as well as traditional Gammatone features are applied for comparison. Moreover, it is shown that the AM can be retrofitted with i-vectors for speaker adaptation. Finally, the described features are combined in order to further advance the performance. With the final best system, we obtain a relative improvement of 4% and 6% over our previous best model on the LibriSpeech test-clean and test-other sets.