 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Domain Adaptation of Foundation LLMs for e-Commerce
Jan 16, 2025We present the e-Llama models: 8 billion and 70 billion parameter large language models that are adapted towards the e-commerce domain. These models are meant as foundation models with deep knowledge about e-commerce, that form a base for instruction- and fine-tuning. The e-Llama models are obtained by continuously pretraining the Llama 3.1 base models on 1 trillion tokens of domain-specific data. We discuss our approach and motivate our choice of hyperparameters with a series of ablation studies. To quantify how well the models have been adapted to the e-commerce domain, we define and implement a set of multilingual, e-commerce specific evaluation tasks. We show that, when carefully choosing the training setup, the Llama 3.1 models can be adapted towards the new domain without sacrificing significant performance on general domain tasks. We also explore the possibility of merging the adapted model and the base model for a better control of the performance trade-off between domains.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
A Tractable Statistical Representation of IFTR Fading with Applications
Jul 12, 2023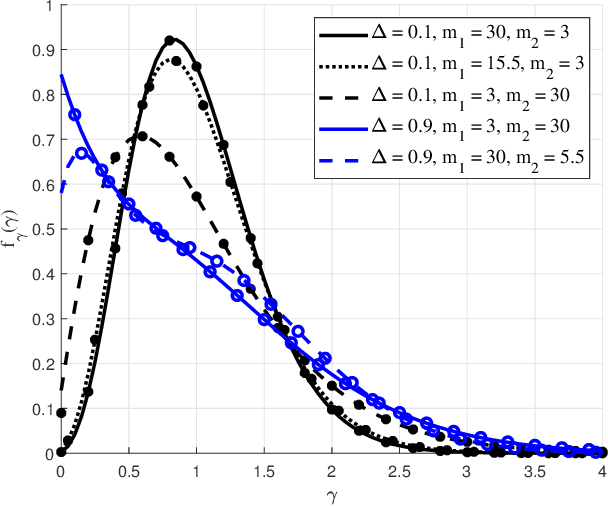
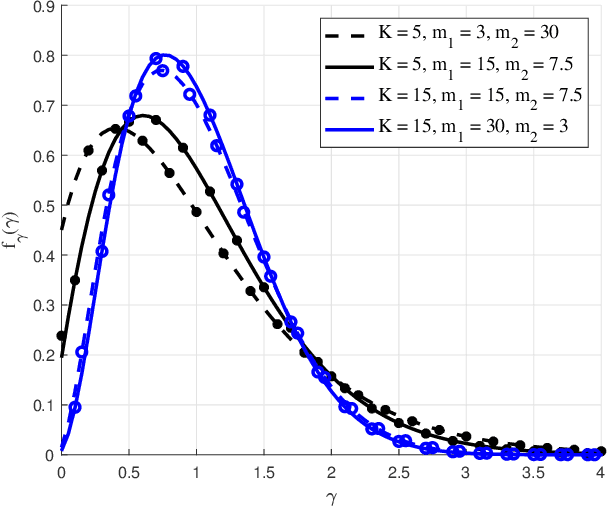
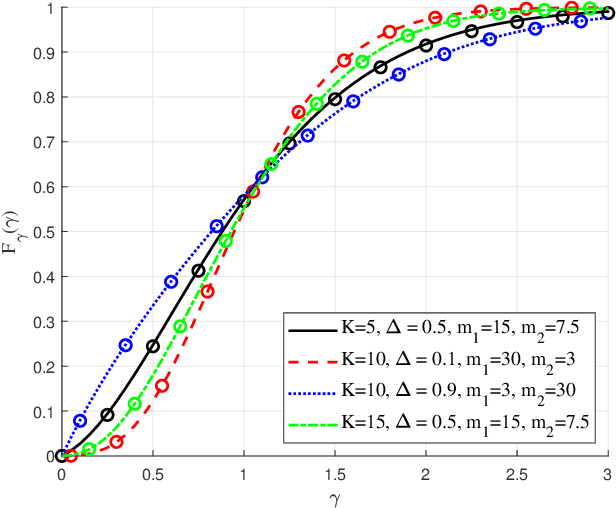
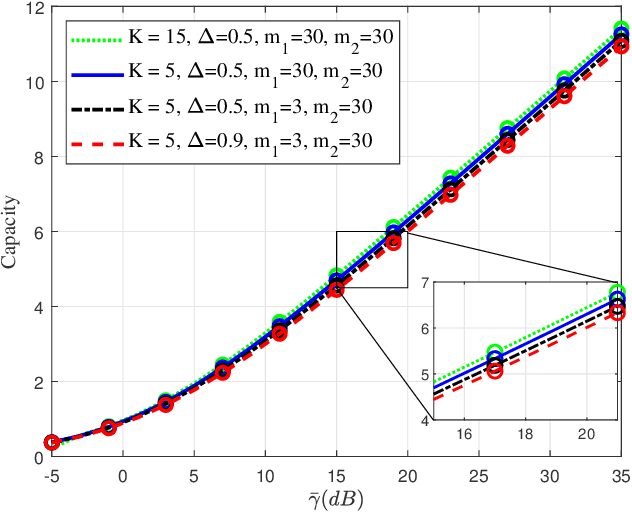
The recently introduced independent fluctuating two-ray (IFTR) fading model, consisting of two specular components fluctuating independently plus a diffuse component, has proven to provide an excellent fit to different wireless environments, including the millimeter-wave band. However, the original formulations of the probability density function (PDF) and cumulative distribution function (CDF) of this model are not applicable to all possible values of its defining parameters, and are given in terms of multifold generalized hypergeometric functions, which prevents their widespread use for the derivation of performance metric expressions. In this paper we present a new formulation of the IFTR model as a countable mixture of Gamma distributions which greatly facilitates the performance evaluation for this model in terms of the metrics already known for the much simpler and widely used Nakagami-m fading. Additionally, a closed-form expression is presented for the generalized moment generating function (GMGF), which permits to readily obtain all the moments of the distribution of the model, as well as several relevant performance metrics. Based on these new derivations, the IFTR model is evaluated for the average channel capacity, the outage probability with and without co-channel interference, and the bit error rate (BER), which are verified by Monte Carlo simulations.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.