 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating the what and how of compositional computation to enable reuse and continual learning
Oct 23, 2025The ability to continually learn, retain and deploy skills to accomplish goals is a key feature of intelligent and efficient behavior. However, the neural mechanisms facilitating the continual learning and flexible (re-)composition of skills remain elusive. Here, we study continual learning and the compositional reuse of learned computations in recurrent neural network (RNN) models using a novel two-system approach: one system that infers what computation to perform, and one that implements how to perform it. We focus on a set of compositional cognitive tasks commonly studied in neuroscience. To construct the what system, we first show that a large family of tasks can be systematically described by a probabilistic generative model, where compositionality stems from a shared underlying vocabulary of discrete task epochs. The shared epoch structure makes these tasks inherently compositional. We first show that this compositionality can be systematically described by a probabilistic generative model. Furthermore, We develop an unsupervised online learning approach that can learn this model on a single-trial basis, building its vocabulary incrementally as it is exposed to new tasks, and inferring the latent epoch structure as a time-varying computational context within a trial. We implement the how system as an RNN whose low-rank components are composed according to the context inferred by the what system. Contextual inference facilitates the creation, learning, and reuse of low-rank RNN components as new tasks are introduced sequentially, enabling continual learning without catastrophic forgetting. Using an example task set, we demonstrate the efficacy and competitive performance of this two-system learning framework, its potential for forward and backward transfer, as well as fast compositional generalization to unseen tasks.
Order parameters and phase transitions of continual learning in deep neural networks
Jul 14, 2024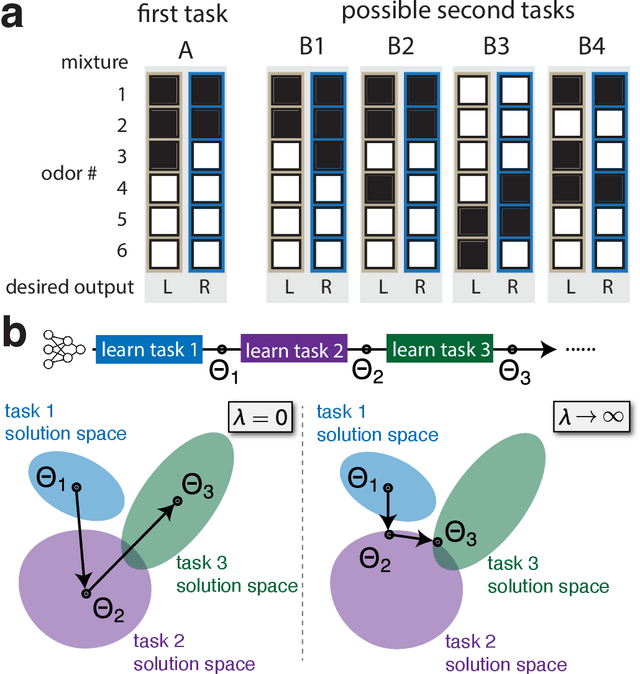

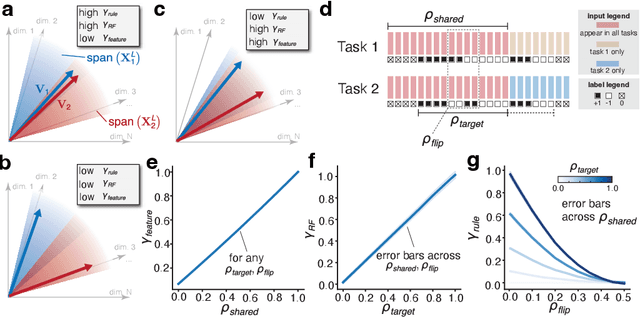
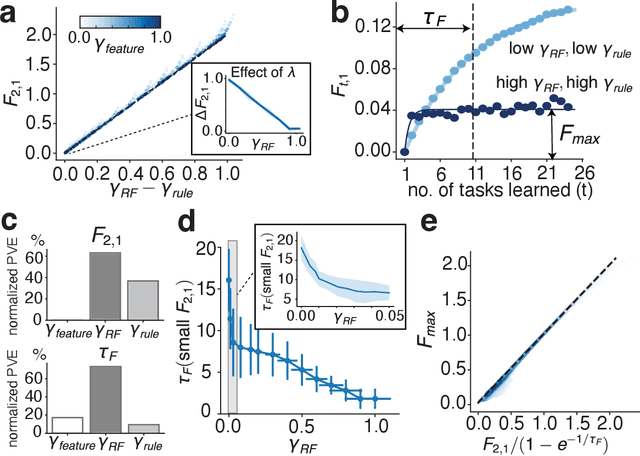
Continual learning (CL) enables animals to learn new tasks without erasing prior knowledge. CL in artificial neural networks (NNs) is challenging due to catastrophic forgetting, where new learning degrades performance on older tasks. While various techniques exist to mitigate forgetting, theoretical insights into when and why CL fails in NNs are lacking. Here, we present a statistical-mechanics theory of CL in deep, wide NNs, which characterizes the network's input-output mapping as it learns a sequence of tasks. It gives rise to order parameters (OPs) that capture how task relations and network architecture influence forgetting and knowledge transfer, as verified by numerical evaluations. We found that the input and rule similarity between tasks have different effects on CL performance. In addition, the theory predicts that increasing the network depth can effectively reduce overlap between tasks, thereby lowering forgetting. For networks with task-specific readouts, the theory identifies a phase transition where CL performance shifts dramatically as tasks become less similar, as measured by the OPs. Sufficiently low similarity leads to catastrophic anterograde interference, where the network retains old tasks perfectly but completely fails to generalize new learning. Our results delineate important factors affecting CL performance and suggest strategies for mitigating forgetting.
Augmenting conformers with structured state space models for online speech recognition
Sep 15, 2023
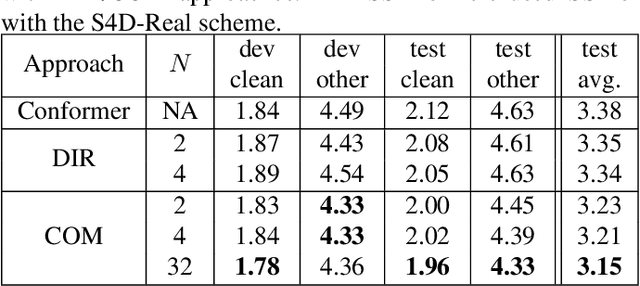
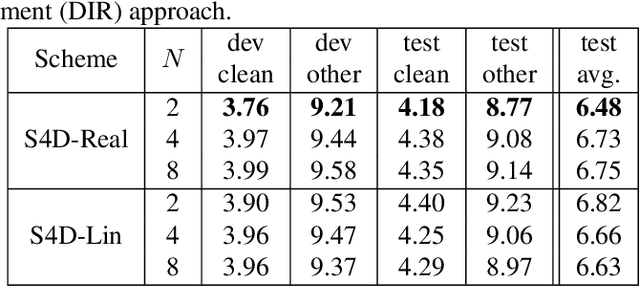
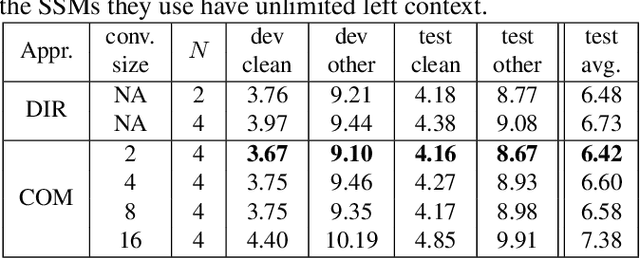
Online speech recognition, where the model only accesses context to the left, is an important and challenging use case for ASR systems. In this work, we investigate augmenting neural encoders for online ASR by incorporating structured state-space sequence models (S4), which are a family of models that provide a parameter-efficient way of accessing arbitrarily long left context. We perform systematic ablation studies to compare variants of S4 models and propose two novel approaches that combine them with convolutions. We find that the most effective design is to stack a small S4 using real-valued recurrent weights with a local convolution, allowing them to work complementarily. Our best model achieves WERs of 4.01%/8.53% on test sets from Librispeech, outperforming Conformers with extensively tuned convolution.
Rapid Feature Evolution Accelerates Learning in Neural Networks
May 29, 2021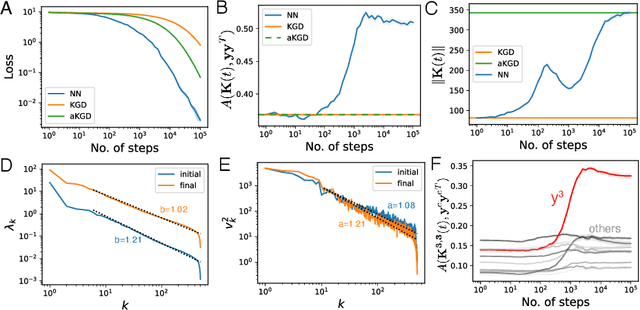
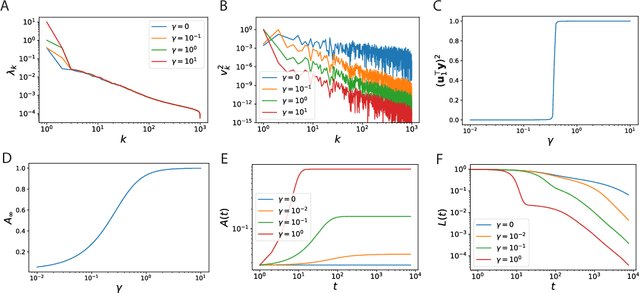
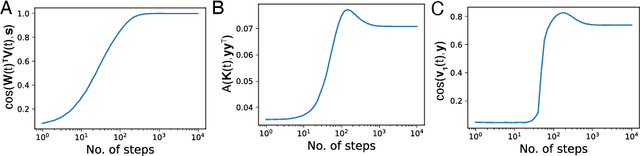
Neural network (NN) training and generalization in the infinite-width limit are well-characterized by kernel methods with a neural tangent kernel (NTK) that is stationary in time. However, finite-width NNs consistently outperform corresponding kernel methods, suggesting the importance of feature learning, which manifests as the time evolution of NTKs. Here, we analyze the phenomenon of kernel alignment of the NTK with the target functions during gradient descent. We first provide a mechanistic explanation for why alignment between task and kernel occurs in deep linear networks. We then show that this behavior occurs more generally if one optimizes the feature map over time to accelerate learning while constraining how quickly the features evolve. Empirically, gradient descent undergoes a feature learning phase, during which top eigenfunctions of the NTK quickly align with the target function and the loss decreases faster than power law in time; it then enters a kernel gradient descent (KGD) phase where the alignment does not improve significantly and the training loss decreases in power law. We show that feature evolution is faster and more dramatic in deeper networks. We also found that networks with multiple output nodes develop separate, specialized kernels for each output channel, a phenomenon we termed kernel specialization. We show that this class-specific alignment is does not occur in linear networks.
Multiscale dictionary of rat locomotion
Aug 23, 2017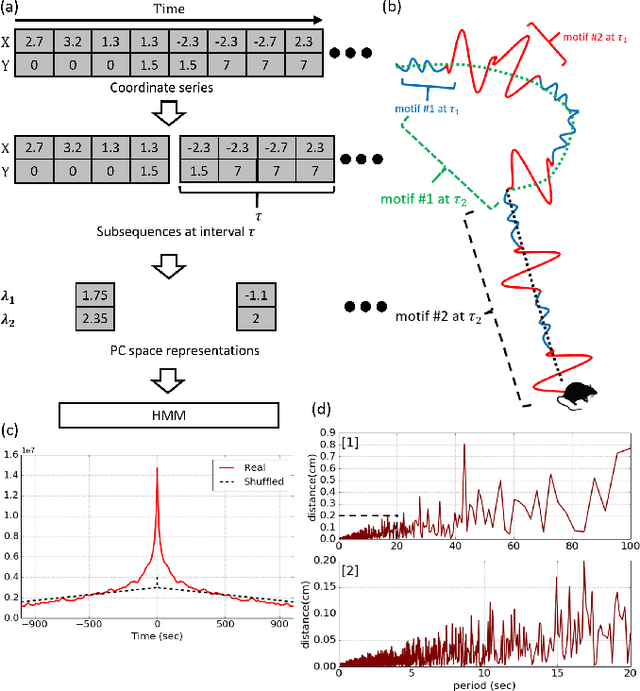
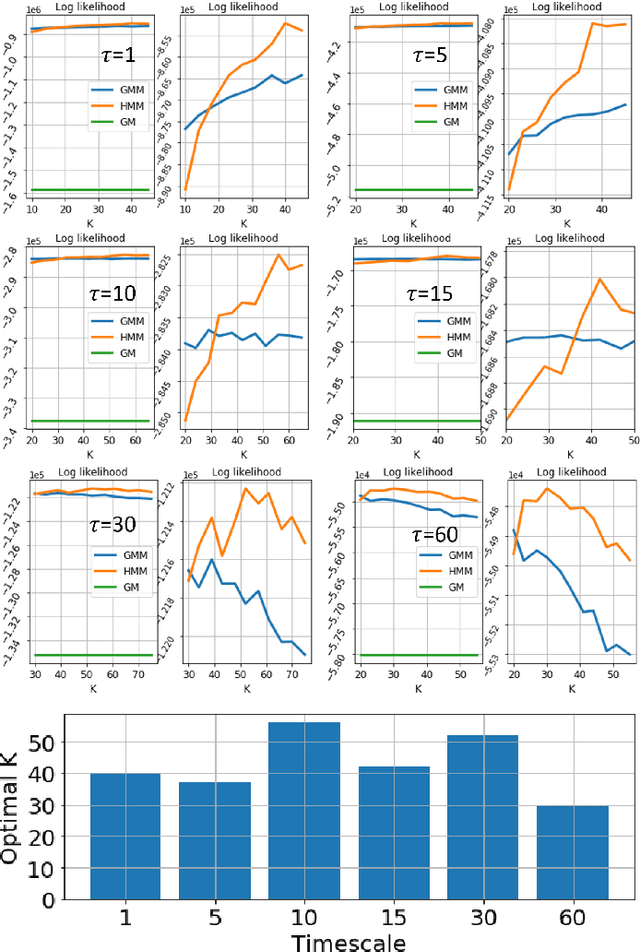
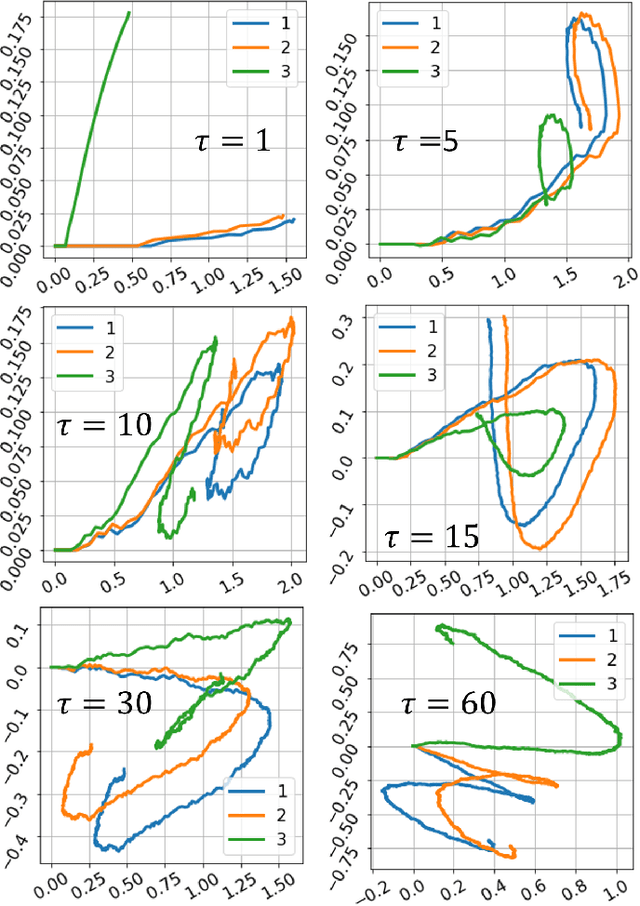
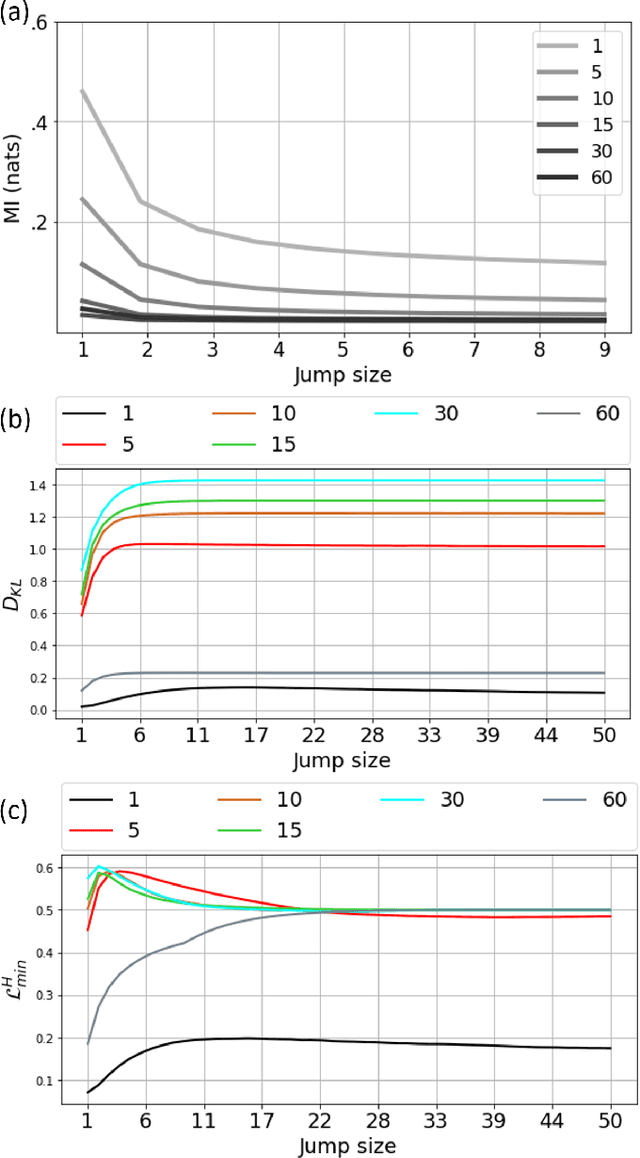
To effectively connect animal behaviors to activities and patterns in the nervous system, it is ideal have a precise, accurate, and complete description of stereotyped modules and their dynamics in behaviors. In case of rodent behaviors, observers have identified and described several stereotyped behaviors, such as grooming and lateral threat. Discovering behavioral repertoires in this way is imprecise, slow and contaminated with biases and individual differences. As a replacement, we propose a framework for unbiased, efficient and precise investigation of rat locomotor activities. We propose that locomotion possesses multiscale dynamics that can be well approximated by multiple Markov processes running in parallel at different spatial-temporal scales. To capture motifs and transition dynamics on multiple scales, we developed a segmentation-decomposition procedure, which imposes explicit constraints on timescales on parallel Hidden Markov Models (HMM). Each HMM describes the motifs and transition dynamics at its respective timescale. We showed that the motifs discovered across timescales have experimental significance and space-dependent heterogeneity. Through statistical tests, we show that locomotor dynamics largely conforms with Markov property across scales. Finally, using layered HMMs, we showed that motif assembly is strongly constrained to a few fixed sequences. The motifs potentially reflect outputs of canonical underlying behavioral output motifs. Our approach and results for the first time capture behavioral dynamics at different spatial-temporal scales, painting a more complete picture of how behaviors are organized.