 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT2KD: Towards A General-Purpose Encoder for Speech, Speaker, and Audio Events
Sep 25, 2024



With the advances in deep learning, the performance of end-to-end (E2E) single-task models for speech and audio processing has been constantly improving. However, it is still challenging to build a general-purpose model with high performance on multiple tasks, since different speech and audio processing tasks usually require different training data, input features, or model architectures to achieve optimal performance. In this work, MT2KD, a novel two-stage multi-task learning framework is proposed to build a general-purpose speech and audio encoder that jointly performs three fundamental tasks: automatic speech recognition (ASR), audio tagging (AT) and speaker verification (SV). In the first stage, multi-teacher knowledge distillation (KD) is applied to align the feature spaces of three single-task high-performance teacher encoders into a single student encoder using the same unlabelled data. In the second stage, multi-task supervised fine-tuning is carried out by initialising the model from the first stage and training on the separate labelled data of each single task. Experiments demonstrate that the proposed multi-task training pipeline significantly outperforms a baseline model trained with multi-task learning from scratch. The final system achieves good performance on ASR, AT and SV: with less than 4% relative word-error-rate increase on ASR, only 1.9 lower mean averaged precision on AT and 0.23% absolute higher equal error rate on SV compared to the best-performing single-task encoders, using only a 66M total model parameters.
Handling Ambiguity in Emotion: From Out-of-Domain Detection to Distribution Estimation
Feb 20, 2024



The subjective perception of emotion leads to inconsistent labels from human annotators. Typically, utterances lacking majority-agreed labels are excluded when training an emotion classifier, which cause problems when encountering ambiguous emotional expressions during testing. This paper investigates three methods to handle ambiguous emotion. First, we show that incorporating utterances without majority-agreed labels as an additional class in the classifier reduces the classification performance of the other emotion classes. Then, we propose detecting utterances with ambiguous emotions as out-of-domain samples by quantifying the uncertainty in emotion classification using evidential deep learning. This approach retains the classification accuracy while effectively detects ambiguous emotion expressions. Furthermore, to obtain fine-grained distinctions among ambiguous emotions, we propose representing emotion as a distribution instead of a single class label. The task is thus re-framed from classification to distribution estimation where every individual annotation is taken into account, not just the majority opinion. The evidential uncertainty measure is extended to quantify the uncertainty in emotion distribution estimation. Experimental results on the IEMOCAP and CREMA-D datasets demonstrate the superior capability of the proposed method in terms of majority class prediction, emotion distribution estimation, and uncertainty estimation.
Efficient Adapter Finetuning for Tail Languages in Streaming Multilingual ASR
Jan 17, 2024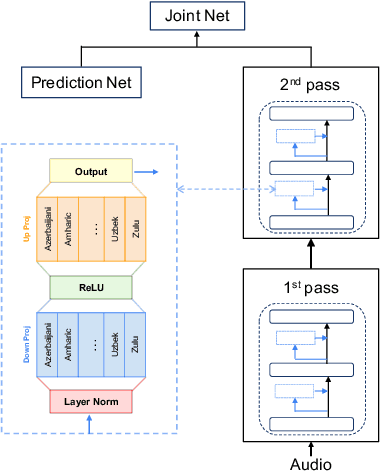

The end-to-end ASR model is often desired in the streaming multilingual scenario since it is easier to deploy and can benefit from pre-trained speech models such as powerful foundation models. Meanwhile, the heterogeneous nature and imbalanced data abundance of different languages may cause performance degradation, leading to asynchronous peak performance for different languages during training, especially on tail ones. Sometimes even the data itself may become unavailable as a result of the enhanced privacy protection. Existing work tend to significantly increase the model size or learn language-specific decoders to accommodate each language separately. In this study, we explore simple yet effective Language-Dependent Adapter (LDA) finetuning under a cascaded Conformer transducer framework enhanced by teacher pseudo-labeling for tail languages in the streaming multilingual ASR. The adapter only accounts for 0.4% of the full model per language. It is plugged into the frozen foundation model and is the only trainable module during the finetuning process with noisy student training. The final model merges the adapter parameters from different checkpoints for different languages. The model performance is validated on a challenging multilingual dictation dataset, which includes 39 tail languages across Latin, Greek, Arabic, etc. Our proposed method brings 12.2% word error rate reduction on average and up to 37.5% on a single locale. Furthermore, we show that our parameter-efficient LDA can match the quality of the full model finetuning, thus greatly alleviating the asynchronous peak performance issue.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023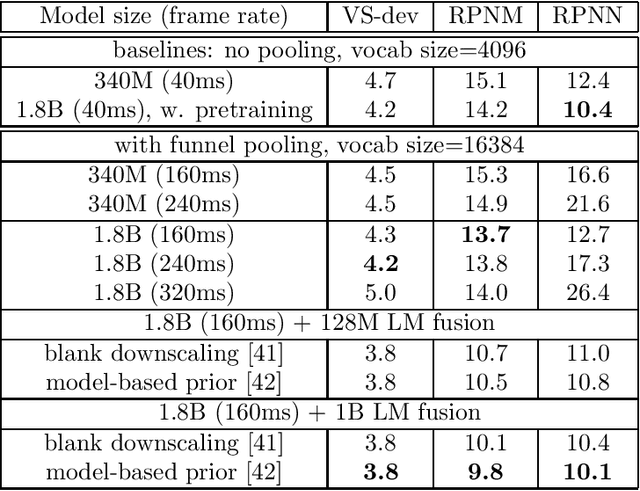
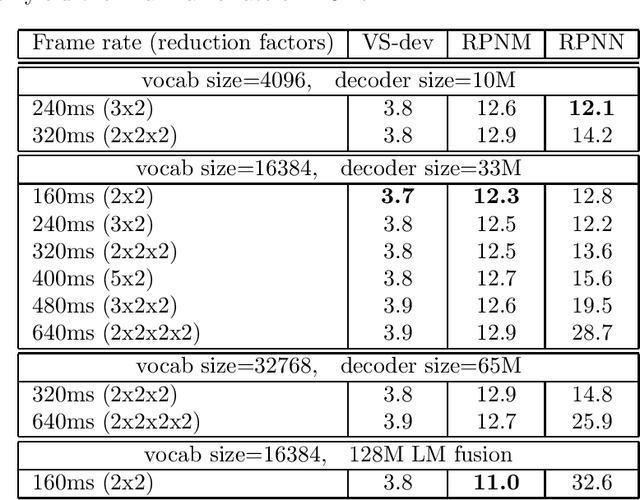
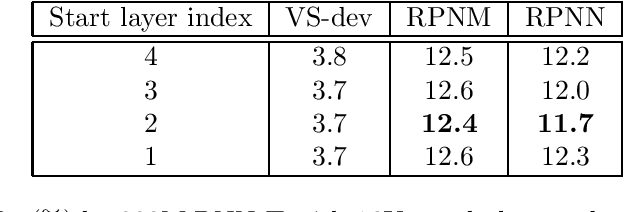
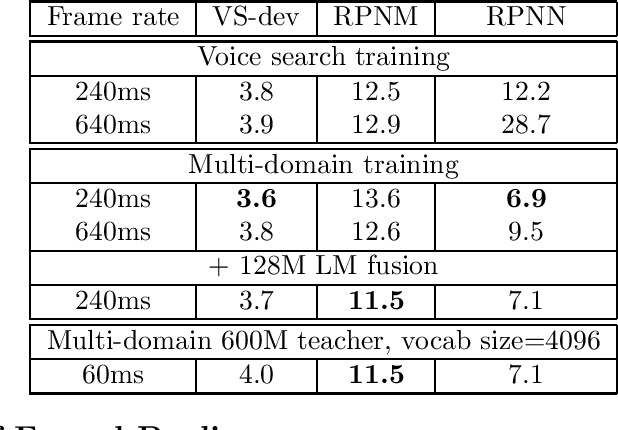
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Modular Domain Adaptation for Conformer-Based Streaming ASR
May 22, 2023Speech data from different domains has distinct acoustic and linguistic characteristics. It is common to train a single multidomain model such as a Conformer transducer for speech recognition on a mixture of data from all domains. However, changing data in one domain or adding a new domain would require the multidomain model to be retrained. To this end, we propose a framework called modular domain adaptation (MDA) that enables a single model to process multidomain data while keeping all parameters domain-specific, i.e., each parameter is only trained by data from one domain. On a streaming Conformer transducer trained only on video caption data, experimental results show that an MDA-based model can reach similar performance as the multidomain model on other domains such as voice search and dictation by adding per-domain adapters and per-domain feed-forward networks in the Conformer encoder.
Knowledge Distillation from Multiple Foundation Models for End-to-End Speech Recognition
Mar 20, 2023



Although large foundation models pre-trained by self-supervised learning have achieved state-of-the-art performance in many tasks including automatic speech recognition (ASR), knowledge distillation (KD) is often required in practice to transfer the knowledge learned by large teacher models into much smaller student models with affordable computation and memory costs. This paper proposes a novel two-stage KD framework to distil the knowledge from multiple speech foundation models as teachers into a single student neural transducer model for ASR. In the first stage, the student model encoder is pre-trained using the embeddings extracted from multiple teacher models. In the second stage, the student encoder is fine-tuned with the audio-text pairs based on the ASR task. Experiments on the LibriSpeech 100-hour subset show that the proposed KD framework improves the performance of both streaming and non-streaming student models when using only one teacher. The performance of the student model can be further enhanced when multiple teachers are used jointly, achieving word error rate reductions (WERRs) of 17.5% and 10.6%. Our proposed framework can be combined with other existing KD methods to achieve further improvements. Further WERRs were obtained by incorporating extra unlabelled data during encoder pre-training, leading to a total relative WERR of 55.0% on the non-streaming student model.
Knowledge Distillation for Neural Transducers from Large Self-Supervised Pre-trained Models
Oct 07, 2021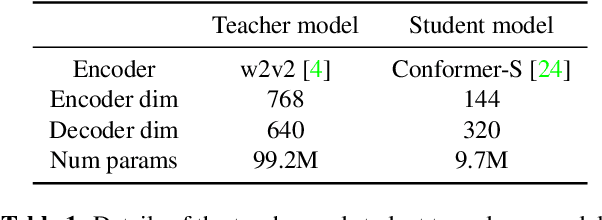
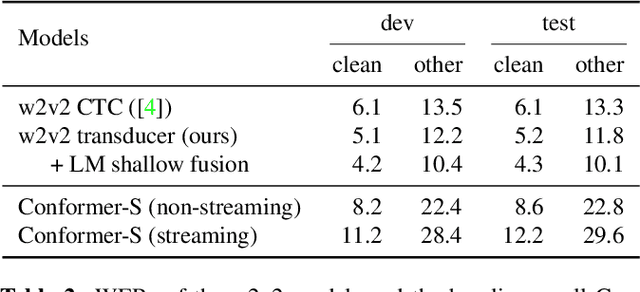
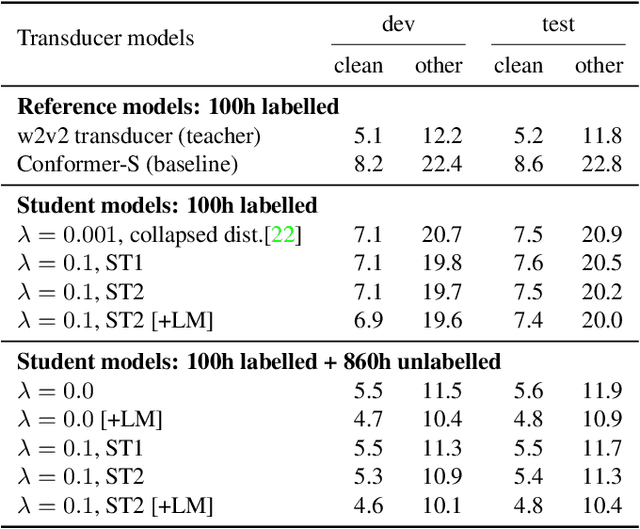
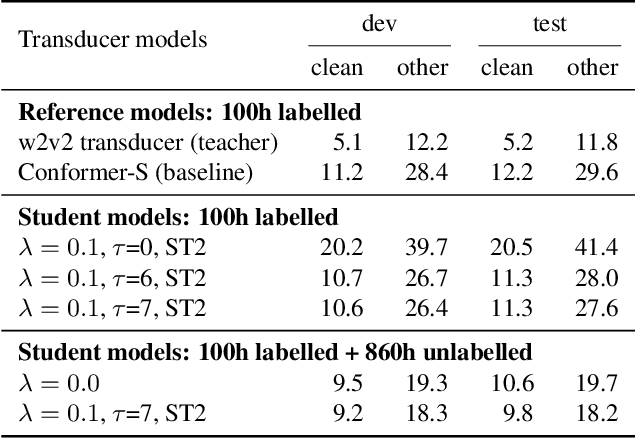
Self-supervised pre-training is an effective approach to leveraging a large amount of unlabelled data to boost the performance of automatic speech recognition (ASR) systems. However, it is impractical to serve large pre-trained models for real-world ASR applications. Therefore, it is desirable to have a much smaller model while retaining the performance of the pre-trained model. In this paper, we propose a simple knowledge distillation (KD) loss function for neural transducers that focuses on the one-best path in the output probability lattice under both the streaming and non-streaming setups, which allows the small student model to approach the performance of the large pre-trained teacher model. Experiments on the LibriSpeech dataset show that despite being more than 10 times smaller than the teacher model, the proposed loss results in relative word error rate reductions (WERRs) of 11.4% and 6.8% on test-other set for non-streaming and streaming student models compared to the baseline transducers trained without KD using the labelled 100-hour clean data. With additional 860-hour unlabelled data for KD, the WERRs increase to 50.4% and 38.5% for non-streaming and streaming students. If language model shallow fusion is used for producing distillation targets, further improvement on the student model is observed.
Improving Confidence Estimation on Out-of-Domain Data for End-to-End Speech Recognition
Oct 07, 2021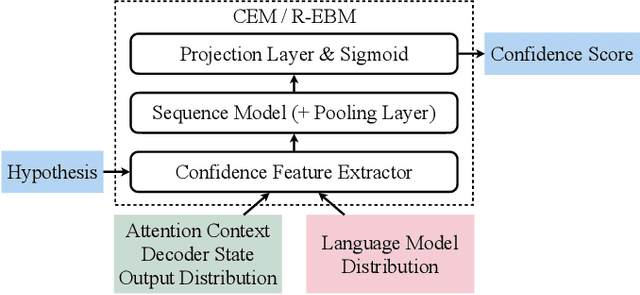
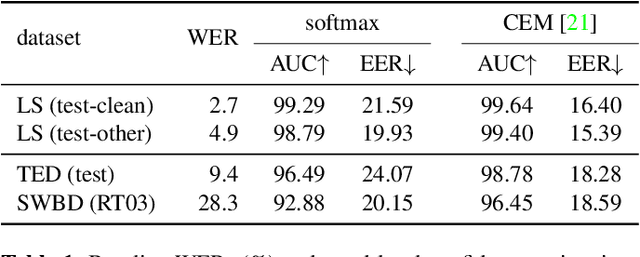
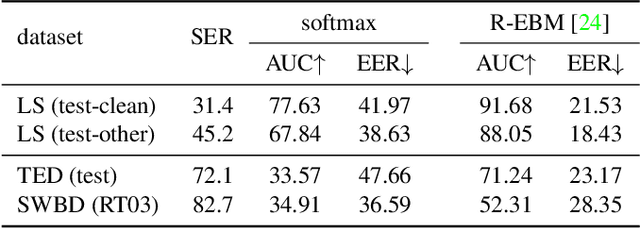
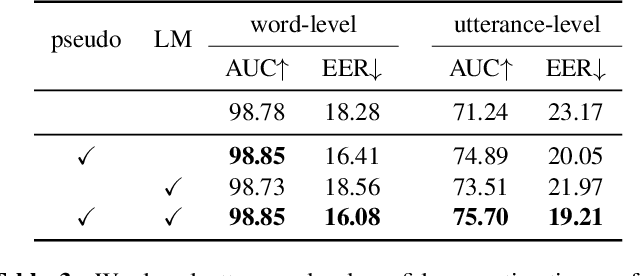
As end-to-end automatic speech recognition (ASR) models reach promising performance, various downstream tasks rely on good confidence estimators for these systems. Recent research has shown that model-based confidence estimators have a significant advantage over using the output softmax probabilities. If the input data to the speech recogniser is from mismatched acoustic and linguistic conditions, the ASR performance and the corresponding confidence estimators may exhibit severe degradation. Since confidence models are often trained on the same in-domain data as the ASR, generalising to out-of-domain (OOD) scenarios is challenging. By keeping the ASR model untouched, this paper proposes two approaches to improve the model-based confidence estimators on OOD data: using pseudo transcriptions and an additional OOD language model. With an ASR model trained on LibriSpeech, experiments show that the proposed methods can significantly improve the confidence metrics on TED-LIUM and Switchboard datasets while preserving in-domain performance. Furthermore, the improved confidence estimators are better calibrated on OOD data and can provide a much more reliable criterion for data selection.
Combining Frame-Synchronous and Label-Synchronous Systems for Speech Recognition
Jul 01, 2021
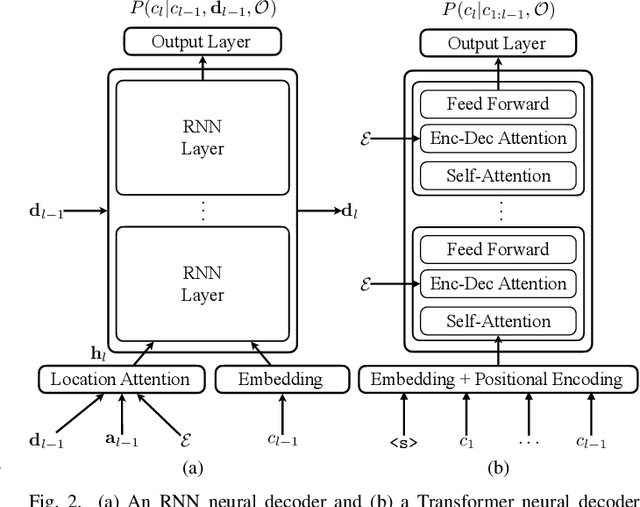
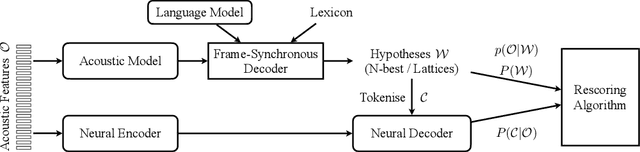
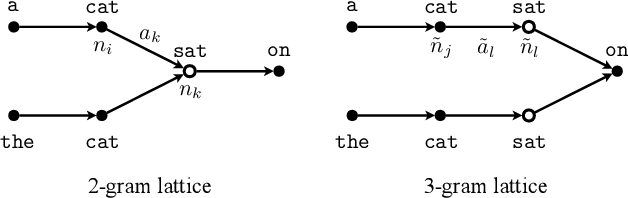
Commonly used automatic speech recognition (ASR) systems can be classified into frame-synchronous and label-synchronous categories, based on whether the speech is decoded on a per-frame or per-label basis. Frame-synchronous systems, such as traditional hidden Markov model systems, can easily incorporate existing knowledge and can support streaming ASR applications. Label-synchronous systems, based on attention-based encoder-decoder models, can jointly learn the acoustic and language information with a single model, which can be regarded as audio-grounded language models. In this paper, we propose rescoring the N-best hypotheses or lattices produced by a first-pass frame-synchronous system with a label-synchronous system in a second-pass. By exploiting the complementary modelling of the different approaches, the combined two-pass systems achieve competitive performance without using any extra speech or text data on two standard ASR tasks. For the 80-hour AMI IHM dataset, the combined system has a 13.7% word error rate (WER) on the evaluation set, which is up to a 29% relative WER reduction over the individual systems. For the 300-hour Switchboard dataset, the WERs of the combined system are 5.7% and 12.1% on Switchboard and CallHome subsets of Hub5'00, and 13.2% and 7.6% on Switchboard Cellular and Fisher subsets of RT03, up to a 33% relative reduction in WER over the individual systems.
Multi-Task Learning for End-to-End ASR Word and Utterance Confidence with Deletion Prediction
Apr 26, 2021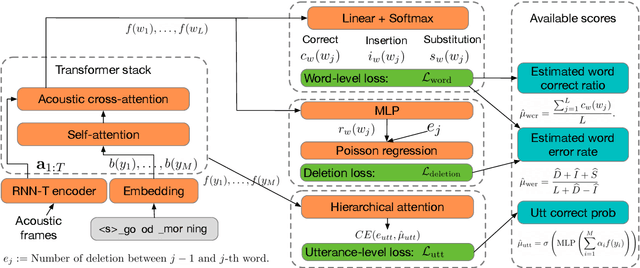
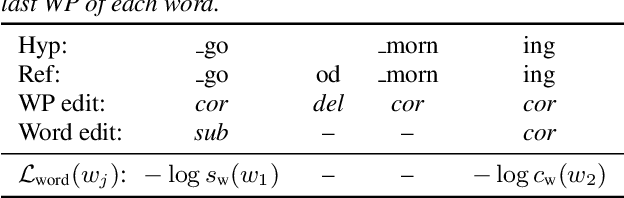
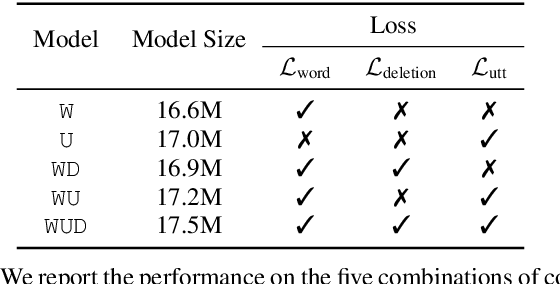
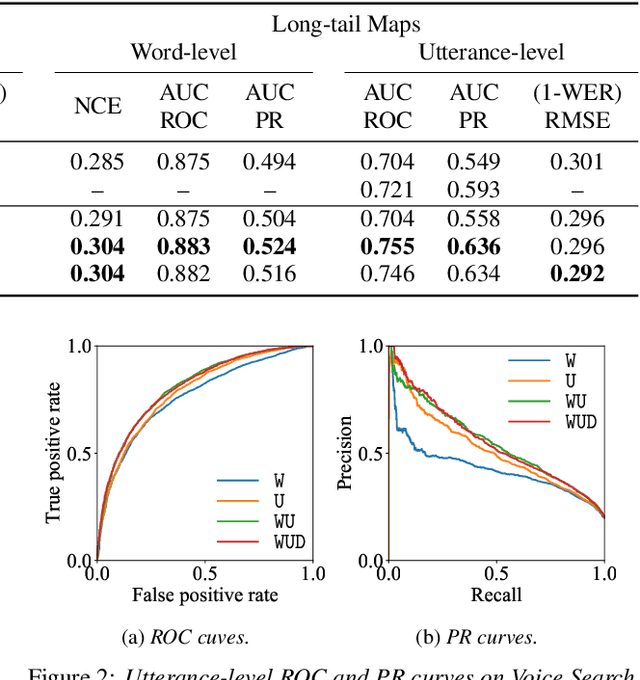
Confidence scores are very useful for downstream applications of automatic speech recognition (ASR) systems. Recent works have proposed using neural networks to learn word or utterance confidence scores for end-to-end ASR. In those studies, word confidence by itself does not model deletions, and utterance confidence does not take advantage of word-level training signals. This paper proposes to jointly learn word confidence, word deletion, and utterance confidence. Empirical results show that multi-task learning with all three objectives improves confidence metrics (NCE, AUC, RMSE) without the need for increasing the model size of the confidence estimation module. Using the utterance-level confidence for rescoring also decreases the word error rates on Google's Voice Search and Long-tail Maps datasets by 3-5% relative, without needing a dedicated neural rescorer.