 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Neural Transducers from Large Self-Supervised Pre-trained Models
Paper and Code
Oct 07, 2021
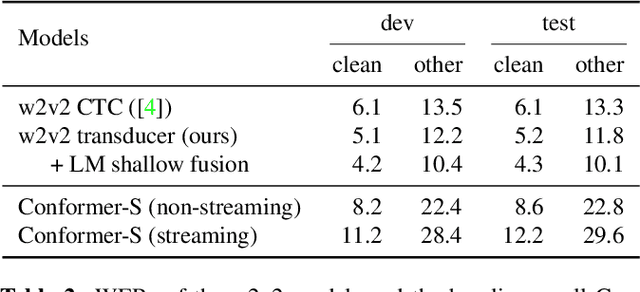
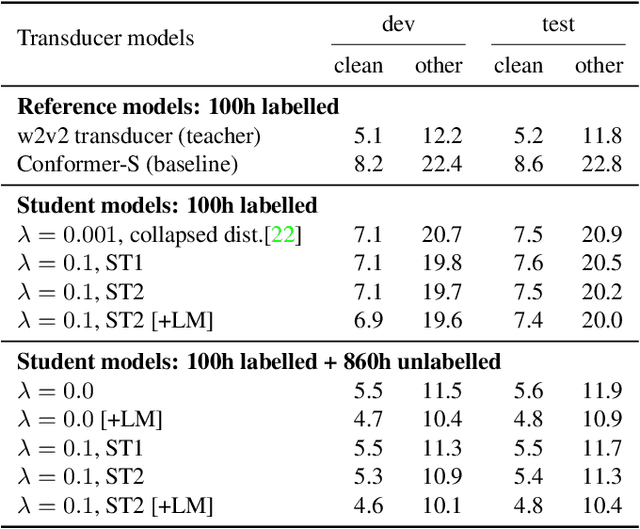
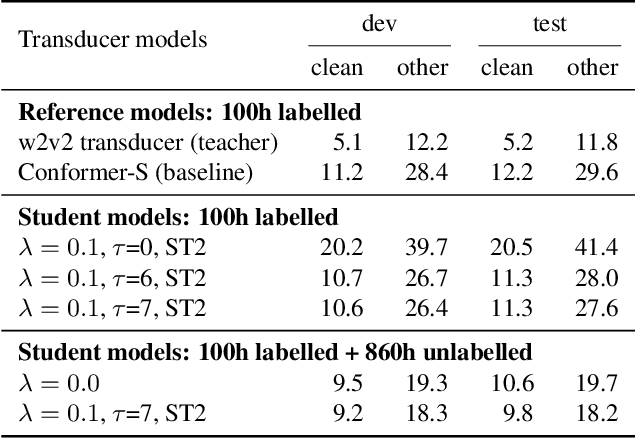
Self-supervised pre-training is an effective approach to leveraging a large amount of unlabelled data to boost the performance of automatic speech recognition (ASR) systems. However, it is impractical to serve large pre-trained models for real-world ASR applications. Therefore, it is desirable to have a much smaller model while retaining the performance of the pre-trained model. In this paper, we propose a simple knowledge distillation (KD) loss function for neural transducers that focuses on the one-best path in the output probability lattice under both the streaming and non-streaming setups, which allows the small student model to approach the performance of the large pre-trained teacher model. Experiments on the LibriSpeech dataset show that despite being more than 10 times smaller than the teacher model, the proposed loss results in relative word error rate reductions (WERRs) of 11.4% and 6.8% on test-other set for non-streaming and streaming student models compared to the baseline transducers trained without KD using the labelled 100-hour clean data. With additional 860-hour unlabelled data for KD, the WERRs increase to 50.4% and 38.5% for non-streaming and streaming students. If language model shallow fusion is used for producing distillation targets, further improvement on the student model is observed.