 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Frame-Synchronous and Label-Synchronous Systems for Speech Recognition
Paper and Code
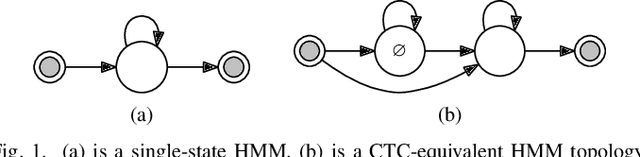
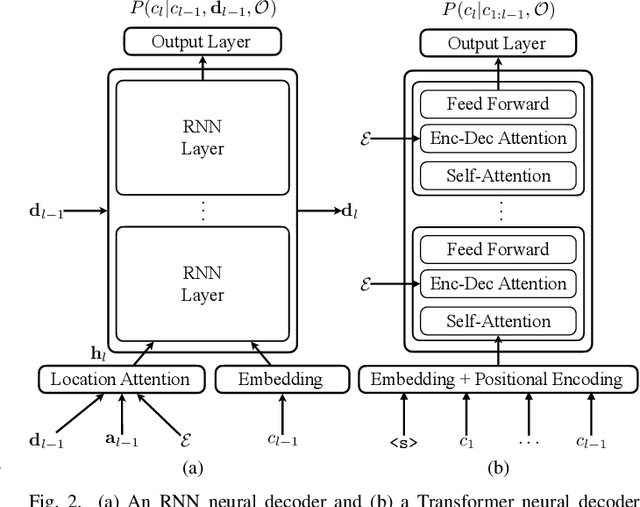
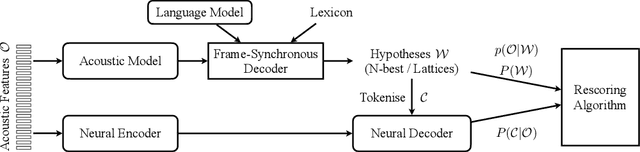
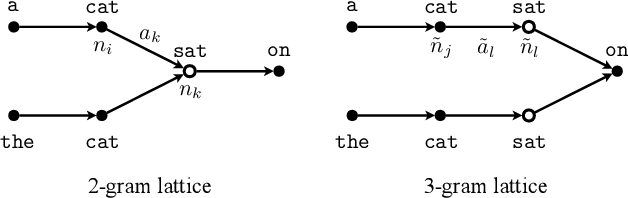
Commonly used automatic speech recognition (ASR) systems can be classified into frame-synchronous and label-synchronous categories, based on whether the speech is decoded on a per-frame or per-label basis. Frame-synchronous systems, such as traditional hidden Markov model systems, can easily incorporate existing knowledge and can support streaming ASR applications. Label-synchronous systems, based on attention-based encoder-decoder models, can jointly learn the acoustic and language information with a single model, which can be regarded as audio-grounded language models. In this paper, we propose rescoring the N-best hypotheses or lattices produced by a first-pass frame-synchronous system with a label-synchronous system in a second-pass. By exploiting the complementary modelling of the different approaches, the combined two-pass systems achieve competitive performance without using any extra speech or text data on two standard ASR tasks. For the 80-hour AMI IHM dataset, the combined system has a 13.7% word error rate (WER) on the evaluation set, which is up to a 29% relative WER reduction over the individual systems. For the 300-hour Switchboard dataset, the WERs of the combined system are 5.7% and 12.1% on Switchboard and CallHome subsets of Hub5'00, and 13.2% and 7.6% on Switchboard Cellular and Fisher subsets of RT03, up to a 33% relative reduction in WER over the individual systems.