 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Pipeline-Based Conversational Agents with Large Language Models
Sep 07, 2023The latest advancements in AI and deep learning have led to a breakthrough in large language model (LLM)-based agents such as GPT-4. However, many commercial conversational agent development tools are pipeline-based and have limitations in holding a human-like conversation. This paper investigates the capabilities of LLMs to enhance pipeline-based conversational agents during two phases: 1) in the design and development phase and 2) during operations. In 1) LLMs can aid in generating training data, extracting entities and synonyms, localization, and persona design. In 2) LLMs can assist in contextualization, intent classification to prevent conversational breakdown and handle out-of-scope questions, auto-correcting utterances, rephrasing responses, formulating disambiguation questions, summarization, and enabling closed question-answering capabilities. We conducted informal experiments with GPT-4 in the private banking domain to demonstrate the scenarios above with a practical example. Companies may be hesitant to replace their pipeline-based agents with LLMs entirely due to privacy concerns and the need for deep integration within their existing ecosystems. A hybrid approach in which LLMs' are integrated into the pipeline-based agents allows them to save time and costs of building and running agents by capitalizing on the capabilities of LLMs while retaining the integration and privacy safeguards of their existing systems.
End-To-End Dilated Variational Autoencoder with Bottleneck Discriminative Loss for Sound Morphing -- A Preliminary Study
Nov 19, 2020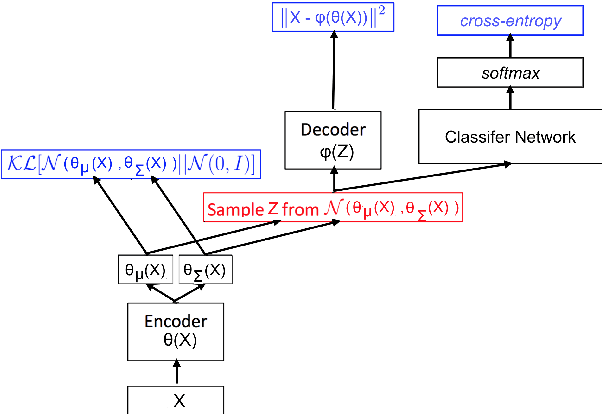
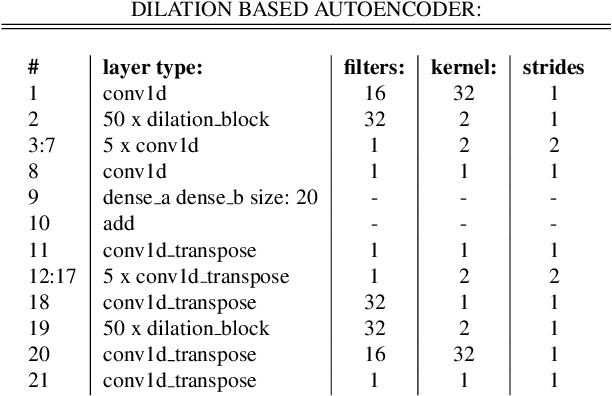
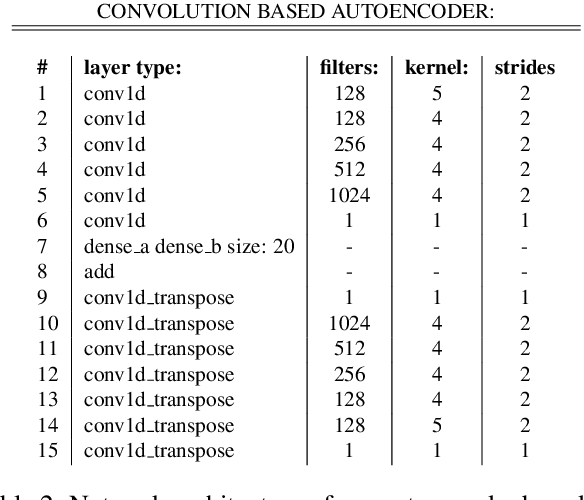
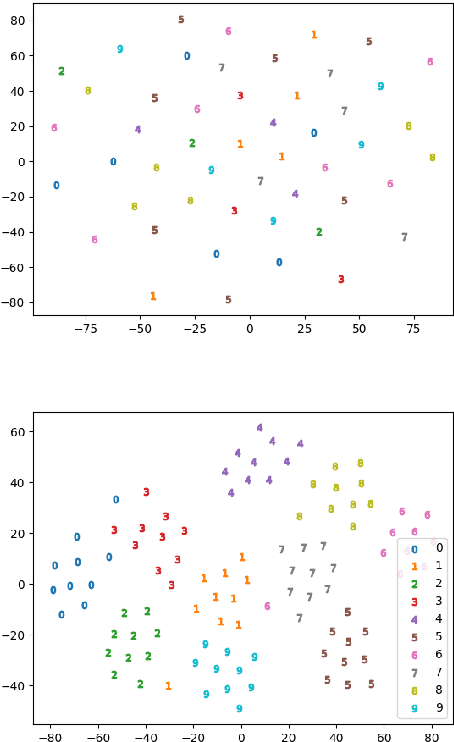
We present a preliminary study on an end-to-end variational autoencoder (VAE) for sound morphing. Two VAE variants are compared: VAE with dilation layers (DC-VAE) and VAE only with regular convolutional layers (CC-VAE). We combine the following loss functions: 1) the time-domain mean-squared error for reconstructing the input signal, 2) the Kullback-Leibler divergence to the standard normal distribution in the bottleneck layer, and 3) the classification loss calculated from the bottleneck representation. On a database of spoken digits, we use 1-nearest neighbor classification to show that the sound classes separate in the bottleneck layer. We introduce the Mel-frequency cepstrum coefficient dynamic time warping (MFCC-DTW) deviation as a measure of how well the VAE decoder projects the class center in the latent (bottleneck) layer to the center of the sounds of that class in the audio domain. In terms of MFCC-DTW deviation and 1-NN classification, DC-VAE outperforms CC-VAE. These results for our parametrization and our dataset indicate that DC-VAE is more suitable for sound morphing than CC-VAE, since the DC-VAE decoder better preserves the topology when mapping from the audio domain to the latent space. Examples are given both for morphing spoken digits and drum sounds.
Deep Learning for Audio Signal Processing
May 25, 2019
Given the recent surge in developments of deep learning, this article provides a review of the state-of-the-art deep learning techniques for audio signal processing. Speech, music, and environmental sound processing are considered side-by-side, in order to point out similarities and differences between the domains, highlighting general methods, problems, key references, and potential for cross-fertilization between areas. The dominant feature representations (in particular, log-mel spectra and raw waveform) and deep learning models are reviewed, including convolutional neural networks, variants of the long short-term memory architecture, as well as more audio-specific neural network models. Subsequently, prominent deep learning application areas are covered, i.e. audio recognition (automatic speech recognition, music information retrieval, environmental sound detection, localization and tracking) and synthesis and transformation (source separation, audio enhancement, generative models for speech, sound, and music synthesis). Finally, key issues and future questions regarding deep learning applied to audio signal processing are identified.
* 15 pages, 2 pdf figures
Utilizing Domain Knowledge in End-to-End Audio Processing
Dec 01, 2017
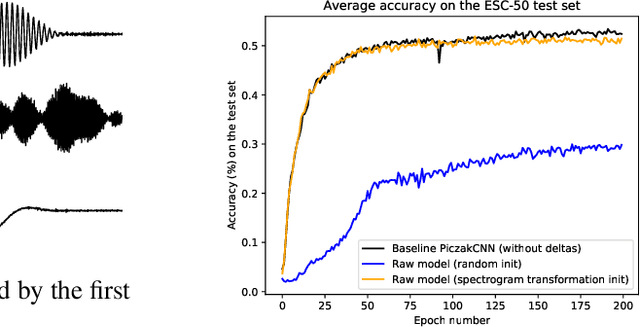
End-to-end neural network based approaches to audio modelling are generally outperformed by models trained on high-level data representations. In this paper we present preliminary work that shows the feasibility of training the first layers of a deep convolutional neural network (CNN) model to learn the commonly-used log-scaled mel-spectrogram transformation. Secondly, we demonstrate that upon initializing the first layers of an end-to-end CNN classifier with the learned transformation, convergence and performance on the ESC-50 environmental sound classification dataset are similar to a CNN-based model trained on the highly pre-processed log-scaled mel-spectrogram features.
Unsupervised Incremental Learning and Prediction of Music Signals
Oct 23, 2015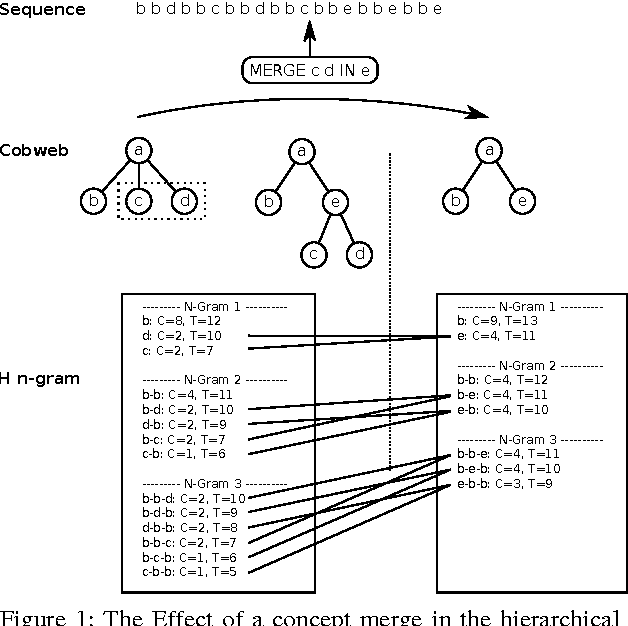

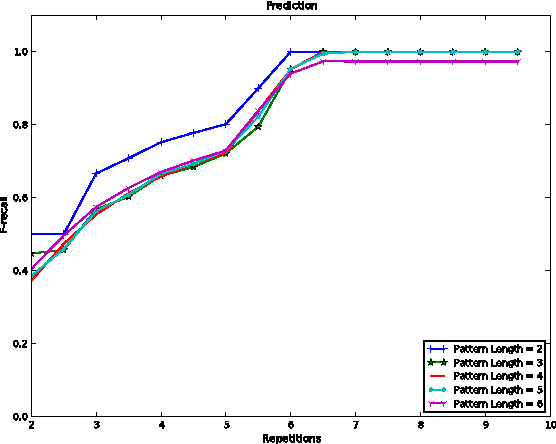
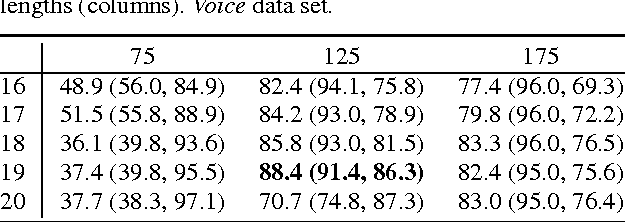
A system is presented that segments, clusters and predicts musical audio in an unsupervised manner, adjusting the number of (timbre) clusters instantaneously to the audio input. A sequence learning algorithm adapts its structure to a dynamically changing clustering tree. The flow of the system is as follows: 1) segmentation by onset detection, 2) timbre representation of each segment by Mel frequency cepstrum coefficients, 3) discretization by incremental clustering, yielding a tree of different sound classes (e.g. instruments) that can grow or shrink on the fly driven by the instantaneous sound events, resulting in a discrete symbol sequence, 4) extraction of statistical regularities of the symbol sequence, using hierarchical N-grams and the newly introduced conceptual Boltzmann machine, and 5) prediction of the next sound event in the sequence. The system's robustness is assessed with respect to complexity and noisiness of the signal. Clustering in isolation yields an adjusted Rand index (ARI) of 82.7% / 85.7% for data sets of singing voice and drums. Onset detection jointly with clustering achieve an ARI of 81.3% / 76.3% and the prediction of the entire system yields an ARI of 27.2% / 39.2%.