 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Incremental Learning and Prediction of Music Signals
Paper and Code
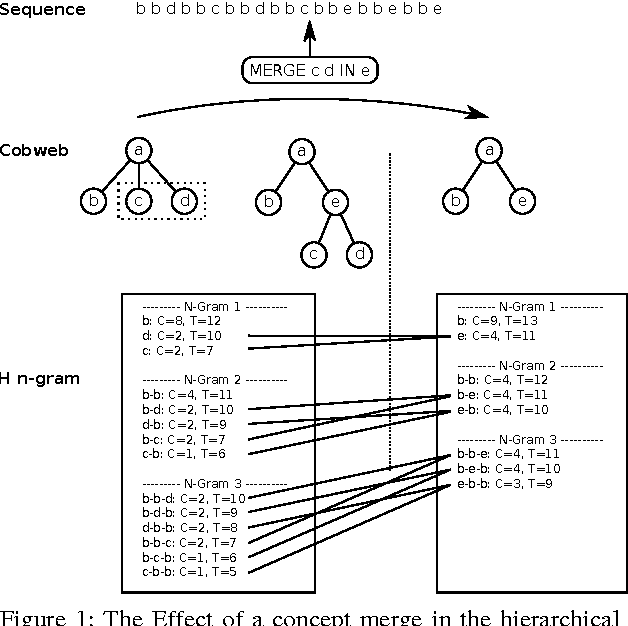

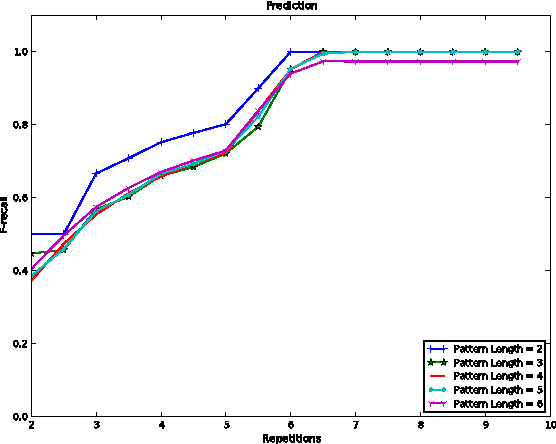
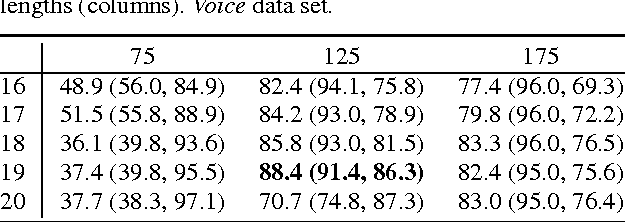
A system is presented that segments, clusters and predicts musical audio in an unsupervised manner, adjusting the number of (timbre) clusters instantaneously to the audio input. A sequence learning algorithm adapts its structure to a dynamically changing clustering tree. The flow of the system is as follows: 1) segmentation by onset detection, 2) timbre representation of each segment by Mel frequency cepstrum coefficients, 3) discretization by incremental clustering, yielding a tree of different sound classes (e.g. instruments) that can grow or shrink on the fly driven by the instantaneous sound events, resulting in a discrete symbol sequence, 4) extraction of statistical regularities of the symbol sequence, using hierarchical N-grams and the newly introduced conceptual Boltzmann machine, and 5) prediction of the next sound event in the sequence. The system's robustness is assessed with respect to complexity and noisiness of the signal. Clustering in isolation yields an adjusted Rand index (ARI) of 82.7% / 85.7% for data sets of singing voice and drums. Onset detection jointly with clustering achieve an ARI of 81.3% / 76.3% and the prediction of the entire system yields an ARI of 27.2% / 39.2%.