Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Domain Knowledge in End-to-End Audio Processing
Dec 01, 2017
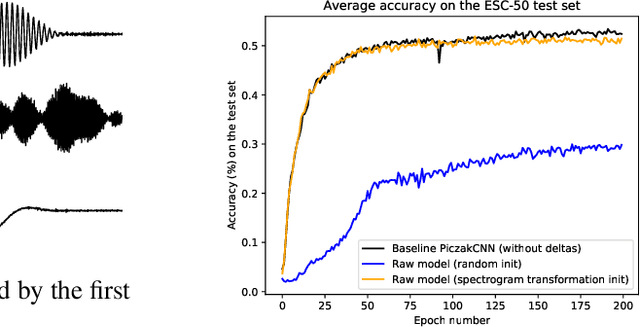
End-to-end neural network based approaches to audio modelling are generally outperformed by models trained on high-level data representations. In this paper we present preliminary work that shows the feasibility of training the first layers of a deep convolutional neural network (CNN) model to learn the commonly-used log-scaled mel-spectrogram transformation. Secondly, we demonstrate that upon initializing the first layers of an end-to-end CNN classifier with the learned transformation, convergence and performance on the ESC-50 environmental sound classification dataset are similar to a CNN-based model trained on the highly pre-processed log-scaled mel-spectrogram features.
* Accepted at the ML4Audio workshop at the NIPS 2017
Via