 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-To-End Dilated Variational Autoencoder with Bottleneck Discriminative Loss for Sound Morphing -- A Preliminary Study
Nov 19, 2020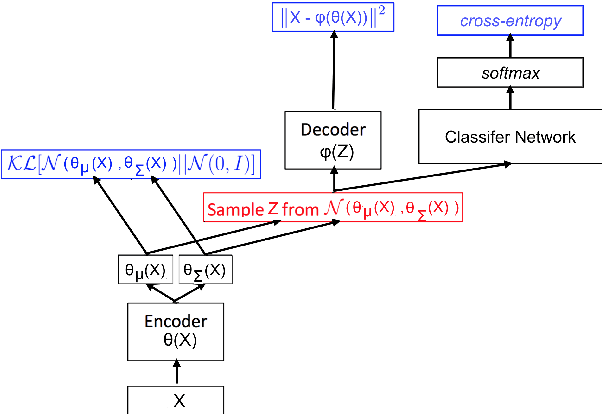
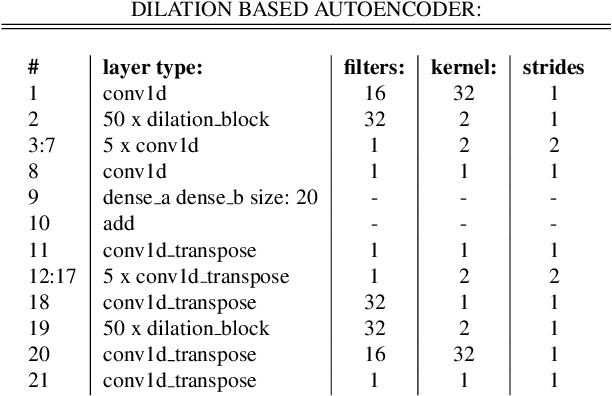
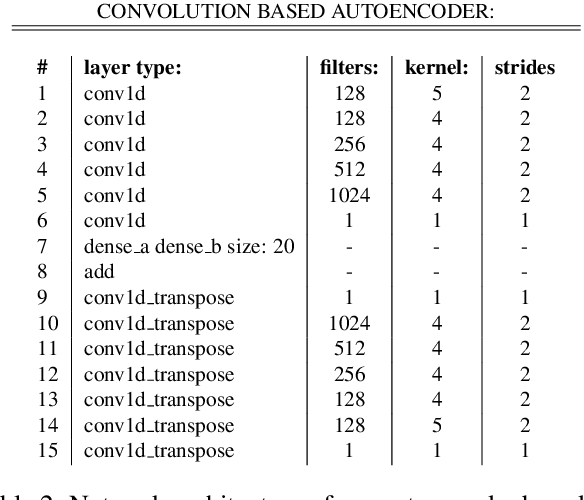
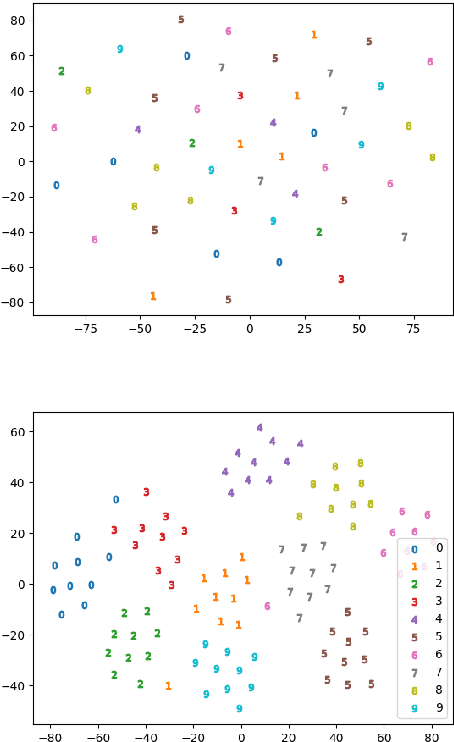
We present a preliminary study on an end-to-end variational autoencoder (VAE) for sound morphing. Two VAE variants are compared: VAE with dilation layers (DC-VAE) and VAE only with regular convolutional layers (CC-VAE). We combine the following loss functions: 1) the time-domain mean-squared error for reconstructing the input signal, 2) the Kullback-Leibler divergence to the standard normal distribution in the bottleneck layer, and 3) the classification loss calculated from the bottleneck representation. On a database of spoken digits, we use 1-nearest neighbor classification to show that the sound classes separate in the bottleneck layer. We introduce the Mel-frequency cepstrum coefficient dynamic time warping (MFCC-DTW) deviation as a measure of how well the VAE decoder projects the class center in the latent (bottleneck) layer to the center of the sounds of that class in the audio domain. In terms of MFCC-DTW deviation and 1-NN classification, DC-VAE outperforms CC-VAE. These results for our parametrization and our dataset indicate that DC-VAE is more suitable for sound morphing than CC-VAE, since the DC-VAE decoder better preserves the topology when mapping from the audio domain to the latent space. Examples are given both for morphing spoken digits and drum sounds.