 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn introduction to pitch strength in contemporary popular music analysis and production
Jun 09, 2025Music information retrieval distinguishes between low- and high-level descriptions of music. Current generative AI models rely on text descriptions that are higher level than the controls familiar to studio musicians. Pitch strength, a low-level perceptual parameter of contemporary popular music, may be one feature that could make such AI models more suited to music production. Signal and perceptual analyses suggest that pitch strength (1) varies significantly across and inside songs; (2) contributes to both small- and large-scale structure; (3) contributes to the handling of polyphonic dissonance; and (4) may be a feature of upper harmonics made audible in a perspective of perceptual richness.
Methods for pitch analysis in contemporary popular music: Vitalic's use of tones that do not operate on the principle of acoustic resonance
Jun 08, 2025Vitalic is an electronic music producer who has been active since 2001. Vitalic's 2005 track "No Fun" features a main synthesiser part built from a sequence of single inharmonic tones that evoke two simultaneous melodies. This part serves as a starting point for examining Vitalic's use of tones that do not operate on the principle of acoustic resonance. The study considers tones that evoke two or more simultaneous pitches and examines various inharmonic partial layouts. Examples outside Vitalic's music are also provided to suggest that similar tone properties can be found elsewhere in contemporary popular music.
Insights on Harmonic Tones from a Generative Music Experiment
Jun 08, 2025The ultimate purpose of generative music AI is music production. The studio-lab, a social form within the art-science branch of cross-disciplinarity, is a way to advance music production with AI music models. During a studio-lab experiment involving researchers, music producers, and an AI model for music generating bass-like audio, it was observed that the producers used the model's output to convey two or more pitches with a single harmonic complex tone, which in turn revealed that the model had learned to generate structured and coherent simultaneous melodic lines using monophonic sequences of harmonic complex tones. These findings prompt a reconsideration of the long-standing debate on whether humans can perceive harmonics as distinct pitches and highlight how generative AI can not only enhance musical creativity but also contribute to a deeper understanding of music.
The evolution of inharmonicity and noisiness in contemporary popular music
Aug 15, 2024Much of Western classical music uses instruments based on acoustic resonance. Such instruments produce harmonic or quasi-harmonic sounds. On the other hand, since the early 1970s, popular music has largely been produced in the recording studio. As a result, popular music is not bound to be based on harmonic or quasi-harmonic sounds. In this study, we use modified MPEG-7 features to explore and characterise the way in which the use of noise and inharmonicity has evolved in popular music since 1961. We set this evolution in the context of other broad categories of music, including Western classical piano music, Western classical orchestral music, and musique concr\`ete. We propose new features that allow us to distinguish between inharmonicity resulting from noise and inharmonicity resulting from interactions between relatively discrete partials. When the history of contemporary popular music is viewed through the lens of these new features, we find that the period since 1961 can be divided into three phases. From 1961 to 1972, there was a steady increase in inharmonicity but no significant increase in noise. From 1972 to 1986, both inharmonicity and noise increased. Then, since 1986, there has been a steady decrease in both inharmonicity and noise to today's popular music which is significantly less noisy but more inharmonic than the music of the sixties. We relate these observed trends to the development of music production practice over the period and illustrate them with focused analyses of certain key artists and tracks.
"Melatonin": A Case Study on AI-induced Musical Style
Aug 18, 2022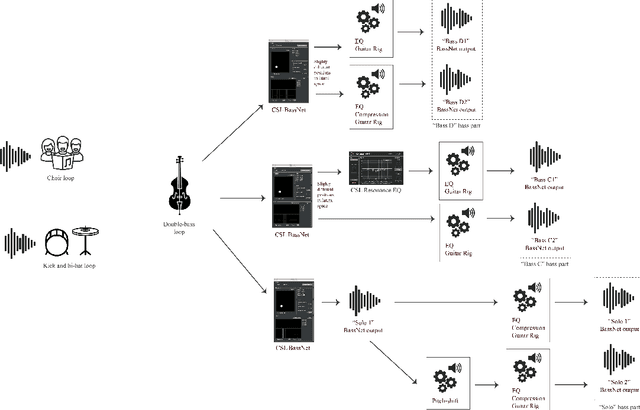


Although the use of AI tools in music composition and production is steadily increasing, as witnessed by the newly founded AI song contest, analysis of music produced using these tools is still relatively uncommon as a mean to gain insight in the ways AI tools impact music production. In this paper we present a case study of "Melatonin", a song produced by extensive use of BassNet, an AI tool originally designed to generate bass lines. Through analysis of the artists' work flow and song project, we identify style characteristics of the song in relation to the affordances of the tool, highlighting manifestations of style in terms of both idiom and sound.
Auto-adaptive Resonance Equalization using Dilated Residual Networks
Jul 23, 2018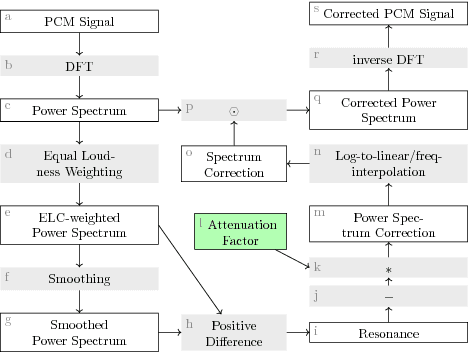
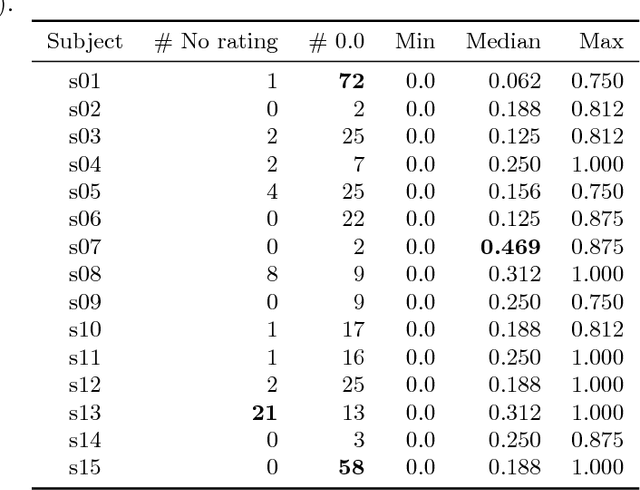
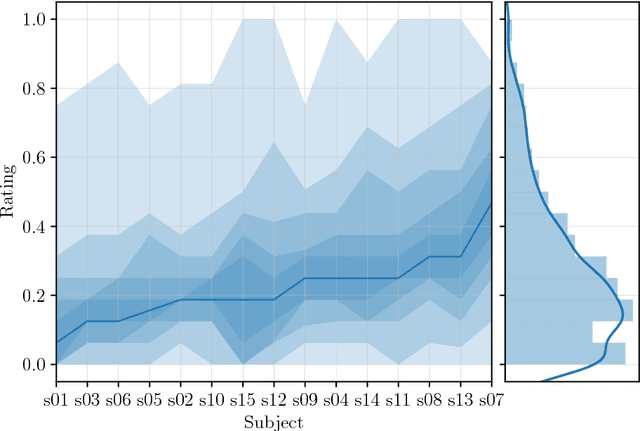

In music and audio production, attenuation of spectral resonances is an important step towards a technically correct result. In this paper we present a two-component system to automate the task of resonance equalization. The first component is a dynamic equalizer that automatically detects resonances and offers to attenuate them by a user-specified factor. The second component is a deep neural network that predicts the optimal attenuation factor based on the windowed audio. The network is trained and validated on empirical data gathered from an experiment in which sound engineers choose their preferred attenuation factors for a set of tracks. We test two distinct network architectures for the predictive model and find that a dilated residual network operating directly on the audio signal is on a par with a network architecture that requires a prior audio feature extraction stage. Both architectures predict human-preferred resonance attenuation factors significantly better than a baseline approach.