 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-adaptive Resonance Equalization using Dilated Residual Networks
Paper and Code
Jul 23, 2018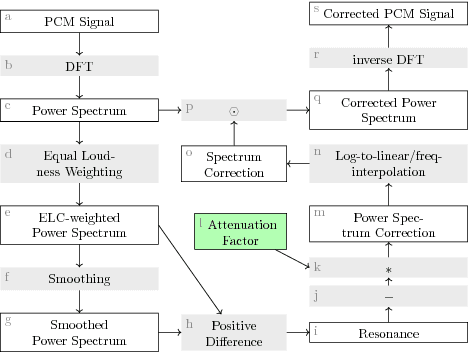
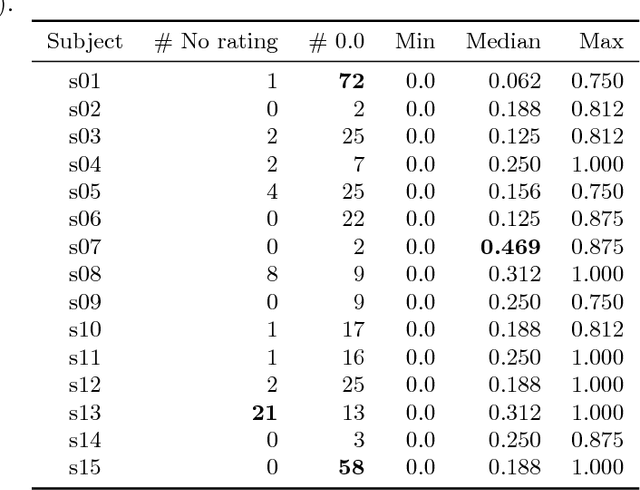
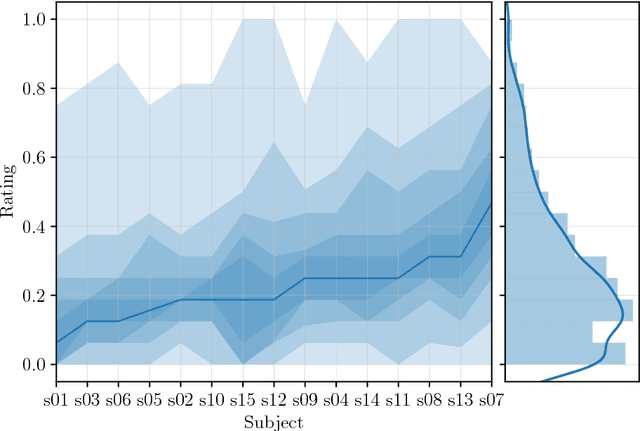

In music and audio production, attenuation of spectral resonances is an important step towards a technically correct result. In this paper we present a two-component system to automate the task of resonance equalization. The first component is a dynamic equalizer that automatically detects resonances and offers to attenuate them by a user-specified factor. The second component is a deep neural network that predicts the optimal attenuation factor based on the windowed audio. The network is trained and validated on empirical data gathered from an experiment in which sound engineers choose their preferred attenuation factors for a set of tracks. We test two distinct network architectures for the predictive model and find that a dilated residual network operating directly on the audio signal is on a par with a network architecture that requires a prior audio feature extraction stage. Both architectures predict human-preferred resonance attenuation factors significantly better than a baseline approach.